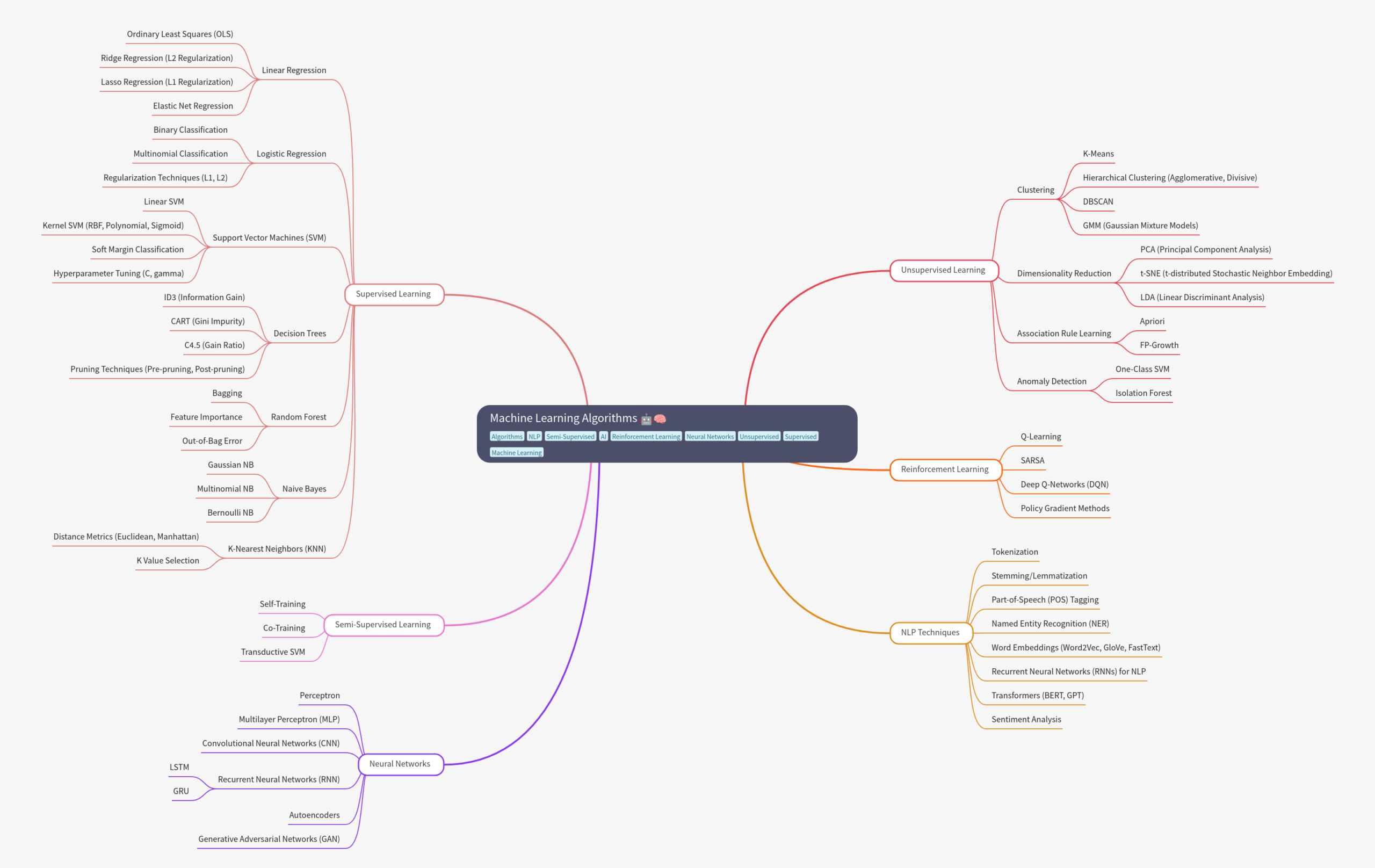
Natural Language Processing (NLP) Supervised Learning: Enhancing Language Understanding
Natural Language Processing (NLP) is a branch of artificial intelligence that focuses on the interaction between computers and human language. Within the realm of NLP, supervised learning plays a crucial role in enhancing language understanding and enabling machines to process and generate human language effectively.
Supervised learning in NLP involves training machine learning models on labeled data, where the input data is paired with corresponding output labels. This labeled data serves as a guide for the model to learn patterns and relationships within the language data, allowing it to make predictions or classifications when presented with new, unseen data.
One of the key advantages of supervised learning in NLP is its ability to handle a wide range of language tasks, such as sentiment analysis, named entity recognition, machine translation, text categorization, and more. By providing annotated examples during the training phase, supervised learning algorithms can generalize patterns and make accurate predictions on unseen text data.
Furthermore, supervised learning allows NLP models to adapt and improve over time as they receive feedback on their predictions. This iterative process of training and fine-tuning models based on new labeled data helps enhance their accuracy and performance in various language processing tasks.
Applications of supervised learning in NLP are vast and diverse. From chatbots that engage in natural conversations with users to recommendation systems that analyze user preferences from text inputs, supervised learning enables machines to understand and generate human language in a way that mimics human-like comprehension.
In conclusion, supervised learning plays a vital role in advancing natural language processing capabilities by empowering machines to learn from labeled data and make informed decisions when processing language inputs. As technology continues to evolve, the integration of supervised learning algorithms will continue to drive innovation in NLP and pave the way for more sophisticated language understanding systems.
Mastering NLP Supervised Learning: 6 Essential Tips for Optimal Model Performance
- 1. Choose the right algorithm for your NLP task, such as Naive Bayes, Support Vector Machines, or Recurrent Neural Networks.
- 2. Preprocess your text data by removing stopwords, punctuation, and performing tokenization and stemming/lemmatization.
- 3. Split your dataset into training and testing sets to evaluate the performance of your model accurately.
- 4. Use techniques like TF-IDF (Term Frequency-Inverse Document Frequency) or word embeddings to represent text data numerically.
- 5. Fine-tune hyperparameters through methods like grid search or random search to optimize model performance.
- 6. Evaluate your model using metrics like accuracy, precision, recall, and F1-score to assess its effectiveness in handling NLP tasks.
1. Choose the right algorithm for your NLP task, such as Naive Bayes, Support Vector Machines, or Recurrent Neural Networks.
When embarking on a natural language processing (NLP) task, selecting the appropriate algorithm is paramount to achieving successful outcomes. It is crucial to carefully consider the nature of the task at hand and choose the right algorithm that aligns with its requirements. Options such as Naive Bayes, Support Vector Machines, or Recurrent Neural Networks offer distinct strengths and capabilities that can be leveraged based on the specific characteristics of the NLP task. By selecting the most suitable algorithm, NLP practitioners can optimize performance, accuracy, and efficiency in processing and analyzing language data effectively.
2. Preprocess your text data by removing stopwords, punctuation, and performing tokenization and stemming/lemmatization.
To enhance the effectiveness of NLP supervised learning, it is essential to preprocess text data by removing stopwords, punctuation, and conducting tokenization and stemming/lemmatization. By eliminating common stopwords and punctuation marks, the focus shifts to the meaningful content of the text. Tokenization breaks down sentences into individual words or tokens, enabling the model to analyze language structures more effectively. Additionally, stemming or lemmatization helps reduce words to their root forms, improving consistency in data representation and aiding in better understanding and processing of textual information by NLP algorithms. This preprocessing step plays a crucial role in optimizing the performance of supervised learning models for language-related tasks.
3. Split your dataset into training and testing sets to evaluate the performance of your model accurately.
To optimize the performance of your NLP supervised learning model, it is essential to follow the tip of splitting your dataset into training and testing sets. By dividing your data in this way, you can assess the effectiveness and accuracy of your model more accurately. The training set allows the model to learn patterns and relationships within the data, while the testing set serves as a benchmark to evaluate how well the model generalizes to new, unseen data. This practice helps ensure that your NLP model is robust and capable of making reliable predictions when applied to real-world language processing tasks.
4. Use techniques like TF-IDF (Term Frequency-Inverse Document Frequency) or word embeddings to represent text data numerically.
To enhance the effectiveness of NLP supervised learning models, it is recommended to utilize techniques such as TF-IDF (Term Frequency-Inverse Document Frequency) or word embeddings to represent text data numerically. TF-IDF assigns weights to words based on their frequency in a document relative to a corpus, capturing the importance of terms in context. On the other hand, word embeddings map words to dense vector representations in a continuous space, capturing semantic relationships between words. By leveraging these numerical representations of text data, NLP models can better understand and process language inputs, leading to improved performance and accuracy in various language processing tasks.
5. Fine-tune hyperparameters through methods like grid search or random search to optimize model performance.
To enhance the performance of NLP supervised learning models, it is crucial to fine-tune hyperparameters using methods like grid search or random search. By systematically exploring various combinations of hyperparameter values, such as learning rates, batch sizes, and regularization strengths, researchers can optimize the model’s performance and achieve better results. Grid search exhaustively searches through a predefined set of hyperparameters, while random search randomly samples hyperparameter values to efficiently explore the parameter space. This process of hyperparameter tuning is essential for maximizing the model’s accuracy and generalization capabilities in natural language processing tasks.
6. Evaluate your model using metrics like accuracy, precision, recall, and F1-score to assess its effectiveness in handling NLP tasks.
When utilizing supervised learning in NLP, it is crucial to evaluate your model using metrics such as accuracy, precision, recall, and F1-score to gauge its effectiveness in handling language processing tasks. These metrics provide valuable insights into the performance of the model by measuring aspects like overall correctness (accuracy), the proportion of correctly predicted positive instances among all predicted positive instances (precision), the proportion of correctly predicted positive instances among all actual positive instances (recall), and a balanced measure that considers both precision and recall (F1-score). By analyzing these metrics, you can assess how well your model is performing and make informed decisions on further optimization or adjustments to enhance its efficiency in processing natural language data.