The Power of NLP in Data Science
In the world of data science, Natural Language Processing (NLP) has emerged as a powerful tool that enables machines to understand, interpret, and generate human language. NLP combines the fields of artificial intelligence, computational linguistics, and computer science to bridge the gap between human communication and computer analysis.
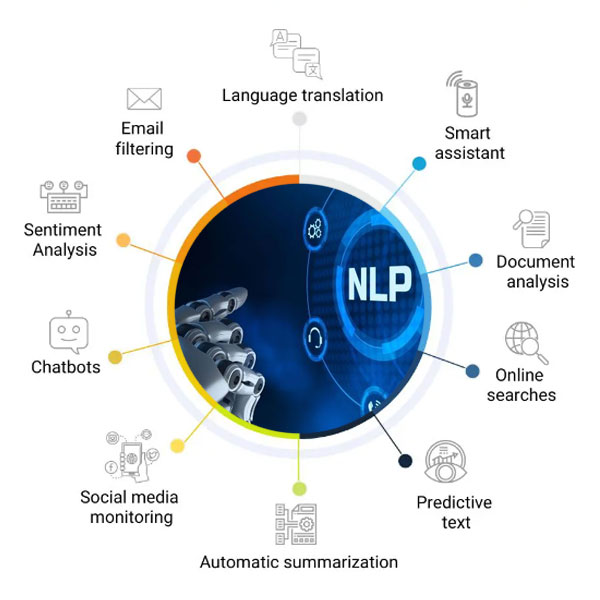
One of the key applications of NLP in data science is text mining, where large volumes of unstructured text data are processed to extract valuable insights and patterns. By using NLP techniques such as tokenization, part-of-speech tagging, and named entity recognition, data scientists can analyze text data from sources like social media, customer reviews, and news articles to uncover trends and sentiments.
Sentiment analysis is another important use case for NLP in data science. By applying machine learning algorithms to text data, sentiment analysis can help businesses understand how customers feel about their products or services. This information can be used to improve marketing strategies, product development, and customer satisfaction.
Machine translation is yet another area where NLP plays a crucial role in data science. By utilizing neural networks and deep learning algorithms, machines can translate text from one language to another with increasing accuracy and fluency. This has significant implications for global businesses looking to communicate effectively across language barriers.
Overall, NLP is revolutionizing the field of data science by providing powerful tools for processing and analyzing unstructured text data. As technology continues to advance, we can expect NLP to play an even greater role in unlocking the potential of natural language understanding for a wide range of applications.
8 Key Advantages of NLP in Data Science: Transforming Language Understanding and Processing
- Enables machines to understand human language.
- Facilitates text mining for valuable insights.
- Empowers sentiment analysis for understanding customer opinions.
- Improves machine translation accuracy and fluency.
- Enhances chatbot and virtual assistant capabilities.
- Aids in information extraction from unstructured data sources.
- Supports automated summarization of large volumes of text.
- Drives innovation in natural language understanding and processing.
Challenges in NLP Data Science: Addressing Ambiguity, Bias, Resource Demands, and Privacy Concerns
- Ambiguity in language can lead to misinterpretation of text.
- NLP models may struggle with understanding slang, dialects, or informal language.
- Data bias in training datasets can result in biased NLP models.
- Complex NLP algorithms require significant computational resources and processing power.
- Privacy concerns arise when sensitive information is processed and analyzed using NLP techniques.
- NLP models may not always generalize well to new or unseen data, leading to performance issues.
Enables machines to understand human language.
One of the key advantages of Natural Language Processing (NLP) in data science is its ability to enable machines to understand human language. By employing sophisticated algorithms and linguistic rules, NLP allows computers to interpret and process text data in a way that mimics human comprehension. This capability opens up a world of possibilities for applications such as sentiment analysis, machine translation, and text mining, where machines can analyze, extract insights from, and generate meaningful responses to human language inputs. The ability of NLP to bridge the gap between human communication and machine analysis is transforming the way we interact with technology and unlocking new opportunities for innovation in various industries.
Facilitates text mining for valuable insights.
Natural Language Processing (NLP) in data science facilitates text mining for valuable insights by enabling the extraction and analysis of meaningful information from unstructured text data. Through NLP techniques such as tokenization, entity recognition, and sentiment analysis, data scientists can uncover trends, patterns, and sentiments hidden within large volumes of textual information. This process allows businesses to gain a deeper understanding of customer feedback, market trends, and other valuable insights that can inform strategic decision-making and drive business growth.
Empowers sentiment analysis for understanding customer opinions.
Natural Language Processing (NLP) in data science empowers sentiment analysis by enabling businesses to gain valuable insights into customer opinions and emotions. By leveraging NLP techniques, such as text mining and machine learning algorithms, companies can analyze vast amounts of unstructured text data from sources like social media, customer reviews, and surveys to understand how customers feel about their products or services. This deeper understanding of customer sentiments allows businesses to tailor their strategies, improve customer experiences, and make data-driven decisions that ultimately enhance overall satisfaction and loyalty.
Improves machine translation accuracy and fluency.
Natural Language Processing (NLP) in data science significantly enhances machine translation accuracy and fluency. By leveraging advanced algorithms and neural networks, NLP enables machines to translate text from one language to another with remarkable precision and naturalness. This improvement in translation quality not only facilitates seamless communication across language barriers but also enhances user experience and comprehension. As NLP technology continues to evolve, the future of machine translation looks promising, opening up new possibilities for global collaboration and understanding.
Enhances chatbot and virtual assistant capabilities.
Natural Language Processing (NLP) in data science significantly enhances chatbot and virtual assistant capabilities by enabling more seamless and intelligent interactions between users and machines. With advanced NLP algorithms, chatbots and virtual assistants can better understand user queries, extract relevant information, and provide accurate responses in a natural language format. This leads to improved user experience, increased efficiency in handling customer inquiries, and overall enhanced functionality of chatbot and virtual assistant systems.
Aids in information extraction from unstructured data sources.
Natural Language Processing (NLP) in data science offers a significant advantage by aiding in the extraction of valuable information from unstructured data sources. With NLP techniques such as text parsing, entity recognition, and relationship extraction, data scientists can efficiently process and analyze vast amounts of unstructured text data from sources like emails, social media posts, and documents. This capability enables organizations to uncover hidden patterns, trends, and insights that would otherwise remain buried in the sea of unstructured information. By harnessing the power of NLP for information extraction, businesses can make informed decisions, improve operational efficiency, and gain a competitive edge in today’s data-driven world.
Supports automated summarization of large volumes of text.
Natural Language Processing (NLP) in data science offers a significant advantage by supporting the automated summarization of large volumes of text. This capability allows organizations to efficiently process and distill extensive amounts of information into concise summaries, saving time and resources while still capturing the essential insights and key points from the text. Automated summarization powered by NLP technology enables faster decision-making, enhances information retrieval, and facilitates better understanding of complex textual data sets, ultimately improving productivity and knowledge management within various industries.
Drives innovation in natural language understanding and processing.
Natural Language Processing (NLP) in data science drives innovation in natural language understanding and processing by enabling machines to comprehend and interpret human language with increasing accuracy and sophistication. Through advanced algorithms and machine learning techniques, NLP enhances the capabilities of systems to analyze, generate, and respond to natural language input, paving the way for groundbreaking applications in areas such as virtual assistants, sentiment analysis, machine translation, and more. This pro of NLP data science not only enhances user experiences but also opens up new possibilities for businesses and industries seeking to leverage the power of language processing for improved communication and decision-making processes.
Ambiguity in language can lead to misinterpretation of text.
Ambiguity in language poses a significant challenge in NLP data science, as it can result in the misinterpretation of text. Words or phrases with multiple meanings or contexts can lead to confusion for machine learning algorithms, causing inaccuracies in analysis and translation. This ambiguity can stem from linguistic nuances, cultural references, or even sarcasm and humor, making it difficult for machines to accurately capture the intended meaning behind the text. As a result, data scientists must constantly refine NLP models to better handle ambiguity and improve the overall accuracy and reliability of language processing systems.
NLP models may struggle with understanding slang, dialects, or informal language.
One significant challenge of NLP data science is that NLP models may struggle with understanding slang, dialects, or informal language. These variations in language can be highly context-dependent and culturally specific, making it difficult for traditional NLP models to accurately interpret and process such linguistic nuances. This limitation can lead to errors in sentiment analysis, machine translation, and other NLP applications when dealing with informal or non-standard forms of language, highlighting the need for further research and development in this area to improve the robustness and adaptability of NLP systems.
Data bias in training datasets can result in biased NLP models.
Data bias in training datasets can pose a significant challenge in the field of NLP data science, as it can lead to the development of biased NLP models. When training data is not representative of the diverse range of language use and contexts, NLP models may inadvertently learn and perpetuate biases present in the data. This can result in inaccurate or unfair outcomes when these models are applied to real-world scenarios, such as automated decision-making processes or content moderation. Addressing data bias in training datasets is crucial to ensure that NLP models are ethically sound, reliable, and inclusive in their applications.
Complex NLP algorithms require significant computational resources and processing power.
Complex NLP algorithms in data science pose a significant challenge due to their high computational demands and the need for substantial processing power. The resource-intensive nature of these algorithms can lead to longer processing times, increased costs, and limitations on the scale of data that can be effectively analyzed. This constraint hinders the widespread adoption of advanced NLP techniques in real-world applications, as organizations may struggle to allocate the necessary computing resources to support complex NLP models. As a result, balancing the benefits of sophisticated NLP algorithms with the practical constraints of computational resources remains a key concern in the field of data science.
Privacy concerns arise when sensitive information is processed and analyzed using NLP techniques.
Privacy concerns can become a significant issue when sensitive information is subjected to processing and analysis through Natural Language Processing (NLP) techniques. The use of NLP in data science raises questions about data security, confidentiality, and the potential misuse of personal information. As NLP algorithms delve into text data to extract insights, there is a risk of unintentionally revealing private details or breaching individuals’ privacy. It is essential for organizations and researchers utilizing NLP to prioritize data protection measures and ensure that ethical guidelines are followed to safeguard sensitive information from unauthorized access or misuse.
NLP models may not always generalize well to new or unseen data, leading to performance issues.
One significant drawback of NLP data science is the challenge of ensuring that NLP models can effectively generalize to new or unseen data. This limitation can result in performance issues, as NLP models may struggle to accurately process and interpret text that differs significantly from the training data they were initially exposed to. This lack of generalization can lead to errors, inconsistencies, and reduced reliability in the outcomes produced by NLP models, highlighting the importance of ongoing refinement and adaptation to enhance their robustness and applicability across diverse datasets.