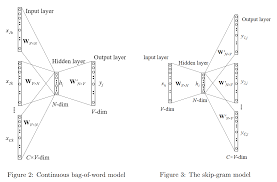
Word2Vec Neural Network: Revolutionizing Natural Language Processing
In the realm of natural language processing (NLP), Word2Vec has emerged as a groundbreaking neural network model that has revolutionized the way computers understand and process human language. Developed by a team of researchers at Google in 2013, Word2Vec is a technique for learning word embeddings – numerical representations of words that capture their semantic meanings based on their context in a given text.
At the core of Word2Vec is the idea that words with similar meanings tend to appear in similar contexts. By analyzing large amounts of text data, the model learns to map words to high-dimensional vectors in such a way that words with similar meanings are located close to each other in this vector space. This allows the model to capture semantic relationships between words and perform various NLP tasks, such as word similarity, analogy detection, and text classification, with remarkable accuracy.
One of the key advantages of Word2Vec is its ability to generate word embeddings from unlabeled text data, making it well-suited for training on vast amounts of freely available text on the web. This unsupervised learning approach enables Word2Vec to capture subtle semantic relationships between words that might be missed by traditional NLP models.
Word2Vec has found widespread applications across various NLP tasks, including sentiment analysis, named entity recognition, machine translation, and more. Its efficiency and effectiveness have made it a go-to tool for researchers and practitioners looking to leverage the power of neural networks in understanding and processing human language.
As NLP continues to advance rapidly, Word2Vec remains at the forefront of innovation in this field. Its ability to learn rich representations of words from raw text data has paved the way for new possibilities in language understanding and generation, bringing us closer to truly intelligent systems that can comprehend and communicate with humans in a more natural and intuitive manner.
8 Essential Tips for Optimizing Word2Vec Neural Networks
- Preprocess text data by tokenizing and cleaning the text
- Choose appropriate hyperparameters such as vector size and window size
- Train word2vec model on a large corpus of text data for better embeddings
- Use techniques like negative sampling to improve training efficiency
- Evaluate the quality of word embeddings using similarity metrics like cosine similarity
- Consider using pretrained word embeddings for faster implementation and potentially better performance
- Fine-tune word embeddings on domain-specific data for improved results in specialized tasks
- Understand how to handle out-of-vocabulary words during inference
Preprocess text data by tokenizing and cleaning the text
When working with the Word2Vec neural network model, it is crucial to preprocess text data by tokenizing and cleaning the text. Tokenization involves breaking down the text into individual words or tokens, which serves as the basic unit for training the model. Cleaning the text involves removing any irrelevant characters, symbols, or noise that could interfere with the learning process. By preprocessing the text data in this way, you can ensure that the Word2Vec model receives clean and structured input, allowing it to effectively learn meaningful word embeddings that capture the semantic relationships between words accurately.
Choose appropriate hyperparameters such as vector size and window size
When working with the Word2Vec neural network model, it is crucial to carefully select appropriate hyperparameters, such as the vector size and window size. The vector size determines the dimensionality of the word embeddings learned by the model, influencing the richness and complexity of the semantic information captured. On the other hand, the window size defines the context window within which the model looks at surrounding words to learn word embeddings. Choosing optimal hyperparameters tailored to the specific task and dataset at hand can significantly impact the performance and effectiveness of the Word2Vec model in capturing meaningful semantic relationships between words.
Train word2vec model on a large corpus of text data for better embeddings
Training a Word2Vec model on a large corpus of text data is a crucial tip for achieving superior word embeddings. By exposing the model to a diverse and extensive range of language patterns and contexts, it can learn more nuanced semantic relationships between words and generate more accurate representations. The richness and variety of the training data play a significant role in shaping the quality of the embeddings produced by the Word2Vec neural network, ultimately enhancing its performance across various natural language processing tasks.
Use techniques like negative sampling to improve training efficiency
To enhance the training efficiency of the Word2Vec neural network, employing techniques such as negative sampling can be highly beneficial. Negative sampling involves training the model to distinguish between true context-word pairs and randomly sampled negative examples. By focusing on a smaller set of negative samples rather than considering all possible words as negatives, the training process becomes more efficient and computationally lighter. This approach not only accelerates the learning process but also helps improve the quality of word embeddings generated by the model, leading to more accurate and meaningful representations of words in the vector space.
Evaluate the quality of word embeddings using similarity metrics like cosine similarity
To assess the effectiveness of word embeddings generated by the Word2Vec neural network, it is crucial to employ similarity metrics such as cosine similarity. By calculating the cosine similarity between vectors representing different words, we can measure the degree of similarity or relatedness between them in the embedding space. A higher cosine similarity value indicates that the words are more closely related in meaning, while a lower value suggests less semantic similarity. This evaluation method helps validate the quality of word embeddings and ensures that they capture meaningful semantic relationships, enabling more accurate performance in various natural language processing tasks.
Consider using pretrained word embeddings for faster implementation and potentially better performance
When working with Word2Vec neural networks, it is advisable to consider utilizing pretrained word embeddings to expedite implementation and potentially enhance performance. Pretrained word embeddings are precomputed vectors that have already been trained on large corpora of text data, capturing intricate semantic relationships between words. By leveraging pretrained embeddings, developers can save time and computational resources required for training their own embeddings from scratch. Additionally, pretrained word embeddings often exhibit superior performance on various NLP tasks due to their exposure to extensive linguistic contexts during training. Incorporating pretrained word embeddings into a Word2Vec model can lead to faster deployment and improved results, making it a valuable strategy for efficient and effective natural language processing applications.
Fine-tune word embeddings on domain-specific data for improved results in specialized tasks
When working with the Word2Vec neural network, a valuable tip is to fine-tune word embeddings on domain-specific data to enhance performance in specialized tasks. By training the model on data that is specific to the domain or industry of interest, such as medical or legal texts, the word embeddings can capture nuances and relationships unique to that domain. This targeted approach can lead to improved accuracy and effectiveness when applying the Word2Vec model to tasks within a specialized field, ultimately enhancing the overall performance and relevance of the NLP applications.
Understand how to handle out-of-vocabulary words during inference
When working with the Word2Vec neural network model, it is crucial to understand how to handle out-of-vocabulary words during the inference process. Out-of-vocabulary words are words that were not present in the training data and can pose a challenge when encountered during real-world applications. To address this issue, one common approach is to map out-of-vocabulary words to a special token or to their closest known word embeddings based on similarity metrics. By implementing robust strategies for handling out-of-vocabulary words, practitioners can ensure the effectiveness and reliability of their Word2Vec model in various NLP tasks.