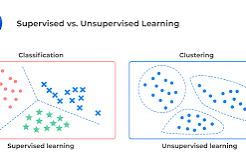
Unsupervised learning is a fascinating branch of artificial intelligence that involves training algorithms on unlabeled data without any specific guidance or supervision. Unlike supervised learning, where algorithms are provided with labeled data to learn from, unsupervised learning tasks involve finding hidden patterns and structures within the data on their own.
One of the key advantages of unsupervised learning is its ability to discover underlying relationships and structures in data that may not be apparent to human observers. By analyzing the data without predefined labels, unsupervised learning algorithms can identify clusters, anomalies, and patterns that can provide valuable insights into the nature of the data.
Clustering is a common application of unsupervised learning, where algorithms group similar data points together based on their characteristics. This can be useful in various fields such as customer segmentation, anomaly detection, and image recognition. By identifying clusters within the data, businesses can gain a better understanding of their customers’ behavior and preferences.
Another important application of unsupervised learning is dimensionality reduction, where algorithms reduce the complexity of high-dimensional data by extracting its essential features. This can help in visualizing and interpreting large datasets more effectively, as well as improving the performance of machine learning models by reducing noise and redundancy in the input data.
Despite its potential benefits, unsupervised learning also presents challenges such as scalability, interpretability, and evaluation. Since there are no ground truth labels to compare against, evaluating the performance of unsupervised learning algorithms can be more subjective and complex. Additionally, ensuring the reliability and consistency of results generated by unsupervised learning models remains a topic of ongoing research.
In conclusion, unsupervised learning plays a crucial role in uncovering hidden patterns and structures within unlabeled data. By leveraging the power of unsupervised learning algorithms, researchers and practitioners can gain valuable insights into complex datasets and drive innovation across various domains.
Understanding Unsupervised Learning: Key Differences, Examples, and Types
- What are the differences between supervised and unsupervised learning?
- Is an example of unsupervised learning?
- What’s the difference between supervised and unsupervised learning?
- What is an example of unsupervised learning data?
- Is ChatGPT supervised or unsupervised?
- What are the two 2 types of unsupervised learning?
What are the differences between supervised and unsupervised learning?
When comparing supervised and unsupervised learning, it’s important to understand the fundamental distinctions between the two approaches. In supervised learning, algorithms are trained on labeled data, where each input is associated with a corresponding output or target label. This allows the algorithm to learn from the provided examples and make predictions or classifications based on the learned patterns. On the other hand, unsupervised learning involves training algorithms on unlabeled data, without explicit guidance or predefined outputs. Instead, unsupervised learning algorithms aim to discover hidden patterns, structures, or relationships within the data on their own. While supervised learning is ideal for tasks requiring precise predictions or classifications, unsupervised learning is valuable for exploring and understanding the inherent characteristics of data without prior knowledge of its labels.
Is an example of unsupervised learning?
An example of unsupervised learning is clustering algorithms, such as K-means clustering. In this approach, the algorithm groups data points into clusters based on their similarities without any predefined labels or guidance. By analyzing the inherent structure of the data and identifying patterns, clustering algorithms help in organizing and understanding complex datasets. This unsupervised learning technique is commonly used in various fields, including customer segmentation, image recognition, and anomaly detection, to uncover hidden relationships and structures within the data.
What’s the difference between supervised and unsupervised learning?
When considering the difference between supervised and unsupervised learning, it is essential to understand their distinct approaches to training machine learning algorithms. In supervised learning, algorithms are provided with labeled data, where the input features are associated with corresponding output labels. The goal is for the algorithm to learn a mapping function that can predict the correct output for new, unseen data based on the patterns identified in the labeled training data. On the other hand, unsupervised learning involves training algorithms on unlabeled data without explicit guidance or supervision. Instead of predicting specific outputs, unsupervised learning algorithms focus on discovering hidden patterns and structures within the data itself. This fundamental distinction in their training methodologies leads to different applications and challenges for each type of learning approach in the field of artificial intelligence.
What is an example of unsupervised learning data?
In the context of unsupervised learning, an example of unsupervised learning data could be a collection of customer purchase histories from an e-commerce website. This dataset would consist of various features such as items purchased, purchase frequency, and total amount spent by each customer, but without any explicit labels or categories assigned to the data points. By applying unsupervised learning techniques such as clustering or association analysis to this dataset, businesses can uncover hidden patterns and group customers based on their purchasing behavior, allowing for targeted marketing strategies and personalized recommendations without the need for manual labeling or predefined categories.
Is ChatGPT supervised or unsupervised?
When considering the nature of ChatGPT, it is important to clarify that ChatGPT is a supervised learning model. In the context of natural language processing and conversational AI, ChatGPT is trained on large amounts of text data that are labeled with input-output pairs, allowing it to learn patterns and generate responses based on the provided examples. This supervised training process enables ChatGPT to understand and generate human-like text responses in conversations, making it a powerful tool for various applications such as chatbots, customer support systems, and interactive interfaces.
What are the two 2 types of unsupervised learning?
In unsupervised learning, there are two main types of approaches: clustering and dimensionality reduction. Clustering algorithms aim to group similar data points together based on their inherent characteristics, allowing for the identification of patterns and relationships within the data. On the other hand, dimensionality reduction techniques focus on simplifying complex datasets by extracting essential features and reducing the number of variables, making it easier to visualize and analyze the data effectively. Both clustering and dimensionality reduction are fundamental components of unsupervised learning that play a crucial role in uncovering hidden structures and insights within unlabeled data.