Understanding Neural Networks
Neural networks have become a buzzword in the world of artificial intelligence and machine learning. But what exactly are neural networks, and how do they work? Let’s delve into the fascinating world of neural networks to gain a better understanding of this powerful technology.
What are Neural Networks?
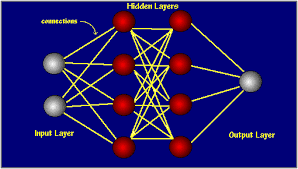
Neural networks are a type of computer algorithm inspired by the structure and function of the human brain. Just like the brain is composed of interconnected neurons that process and transmit information, neural networks consist of layers of artificial nodes that work together to analyze complex data and make predictions.
How Do Neural Networks Work?
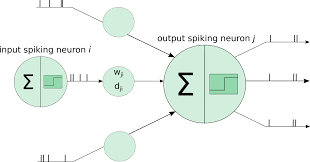
Neural networks operate by processing input data through a series of interconnected layers, each containing multiple nodes or “neurons.” These neurons apply mathematical transformations to the input data and pass it on to the next layer. Through this process, neural networks can learn patterns and relationships within the data, enabling them to make accurate predictions or classifications.
The Role of Weights and Activation Functions
In a neural network, each connection between neurons is assigned a weight that determines the strength of the connection. During training, these weights are adjusted based on the error between the predicted output and the actual output. Activation functions are used to introduce non-linearities into the network, allowing it to model complex relationships in the data.
Types of Neural Networks
There are several types of neural networks designed for different tasks, such as:
- Feedforward Neural Networks: The simplest form of neural network where information flows in one direction from input to output.
- Recurrent Neural Networks (RNNs): Neural networks with loops that allow them to retain information over time, making them suitable for sequential data.
- Convolutional Neural Networks (CNNs): Specialized for processing grid-like data such as images, using convolutional layers to extract features.
Applications of Neural Networks
Neural networks have found applications in various fields, including image recognition, natural language processing, autonomous vehicles, healthcare diagnostics, and more. Their ability to learn from data and adapt to new information makes them versatile tools for solving complex problems.
The Future of Neural Networks
As research in artificial intelligence advances, neural networks continue to evolve with more sophisticated architectures and improved performance. With ongoing developments in deep learning techniques and computational power, we can expect neural networks to play an increasingly prominent role in shaping our technological future.
In conclusion, understanding neural networks is key to unlocking their potential for revolutionizing industries and driving innovation. By harnessing the power of these intelligent systems, we can pave the way for a smarter and more connected world.
Key FAQs for Grasping Neural Networks: Types, Interpretation, Explanation, and Required Mathematics
- What are the 3 different types of neural networks?
- How do you read a neural network model?
- How do you explain a neural network?
- What math is needed to understand neural networks?
What are the 3 different types of neural networks?
There are three main types of neural networks commonly used in artificial intelligence and machine learning: feedforward neural networks, recurrent neural networks (RNNs), and convolutional neural networks (CNNs). Feedforward neural networks are the simplest form, with information flowing in one direction from input to output. RNNs have loops that allow them to retain information over time, making them suitable for sequential data analysis. CNNs are specialized for processing grid-like data such as images, using convolutional layers to extract features and patterns. Each type of neural network is designed to address specific tasks and challenges, showcasing the versatility and power of this technology in various domains.
How do you read a neural network model?
Understanding how to read a neural network model is essential for interpreting its structure and parameters. When examining a neural network model, it is important to start by looking at the number of layers it contains, the type of neurons in each layer, and the connections between them. By analyzing the weights and biases assigned to these connections, one can gain insights into how the network processes information and makes predictions. Additionally, understanding the activation functions used in each layer can provide valuable information about how the network introduces non-linearities into its computations. Overall, reading a neural network model involves dissecting its architecture and parameters to unravel the inner workings of this powerful machine learning tool.
How do you explain a neural network?
Explaining a neural network involves likening it to the human brain’s structure and function. Just as the brain’s interconnected neurons process and transmit information, a neural network comprises layers of artificial nodes that work together to analyze data and make predictions. By breaking down complex data into simpler components and passing them through interconnected layers, neural networks can learn patterns and relationships, enabling them to make accurate predictions or classifications. The concept of weights determining connection strength and activation functions introducing non-linearities further elucidates how neural networks process information to achieve desired outcomes.
What math is needed to understand neural networks?
To understand neural networks, a foundational knowledge of mathematics is essential. Key mathematical concepts that are crucial for comprehending neural networks include linear algebra, calculus, probability theory, and optimization techniques. Linear algebra is used to represent and manipulate the matrices and vectors that define the connections and computations within a neural network. Calculus helps in understanding how gradients are computed during the training process to optimize the network’s parameters. Probability theory is utilized in certain types of neural networks for modeling uncertainty and making probabilistic predictions. Optimization techniques, such as gradient descent, play a vital role in adjusting the network’s weights to minimize errors and improve performance. By mastering these mathematical principles, one can gain a deeper insight into the inner workings of neural networks and effectively leverage their capabilities for various applications.