Building Neural Networks with PySpark
In the era of big data, the ability to process and analyze vast amounts of information efficiently is crucial. Apache Spark has emerged as a powerful tool for big data processing, and its Python library, PySpark, extends these capabilities to Python users. When combined with neural networks, PySpark offers a potent solution for developing scalable machine learning models.
What is PySpark?
PySpark is the Python API for Apache Spark, an open-source distributed computing system that provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. It allows users to leverage the power of Spark’s distributed computing framework using Python’s simple and intuitive syntax.
Integrating Neural Networks with PySpark
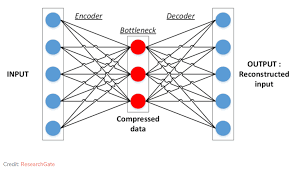
Neural networks are a subset of machine learning algorithms inspired by the human brain’s structure and function. They are particularly effective in tasks like image recognition, natural language processing, and predictive analytics. By integrating neural networks with PySpark, developers can harness the power of distributed computing to train models on large datasets efficiently.
Why Use PySpark for Neural Networks?
- Scalability: With PySpark, developers can easily scale their computations across multiple nodes in a cluster, allowing them to handle massive datasets that would be infeasible on a single machine.
- Speed: Apache Spark’s in-memory computation capability significantly speeds up data processing tasks compared to traditional disk-based systems.
- Simplicity: The combination of Python’s easy-to-read syntax and Spark’s powerful computation engine makes PySpark an accessible choice for both beginners and experienced developers.
Building a Neural Network with PySpark
The process of building a neural network using PySpark involves several key steps:
- Data Preparation: Load and preprocess your dataset using Spark DataFrames or RDDs (Resilient Distributed Datasets). This step often involves cleaning data, handling missing values, and transforming features.
- Create the Model: Define your neural network architecture. While native support for deep learning is limited in Spark MLlib (the machine learning library in Spark), you can use libraries like TensorFlowOnSpark or Elephas to integrate deep learning frameworks such as TensorFlow or Keras with Spark.
- Train the Model: Distribute your training process across the cluster using the integrated deep learning framework. This allows you to leverage multiple CPUs or GPUs for faster training times.
- Evaluate the Model: After training, evaluate your model’s performance on a test dataset. Use metrics such as accuracy, precision, recall, or F1-score depending on your specific task requirements.
The Future of Neural Networks in Big Data
The integration of neural networks with big data platforms like Apache Spark represents a significant advancement in how we approach machine learning at scale. As both technologies continue to evolve, they promise even more efficient ways to process vast amounts of information quickly and accurately.
The combination of PySpark’s scalability and speed with neural networks’ advanced modeling capabilities makes this duo an invaluable asset for businesses looking to gain insights from their data while staying ahead in today’s competitive landscape.
If you’re interested in exploring this powerful combination further, consider diving into resources like official documentation or community forums where you can learn from other practitioners’ experiences working at this intersection between big data processing and advanced machine learning techniques.
9 Advantages of Using PySpark Neural Networks: From Scalability to Performance Optimization
- 1. Scalable
- 2. Speed
- 3. Ease of Use
- 4. Parallel Processing
- 5. Fault Tolerance
- 6. Integration Flexibility
- 7. Resource Efficiency
- 8. Community Support
- 9. Performance Optimization
Challenges of Implementing Neural Networks with PySpark: Key Limitations to Consider
- Limited native support for deep learning in Spark MLlib
- Complexity in integrating external deep learning frameworks like TensorFlow or Keras with PySpark
- Potential challenges in debugging and troubleshooting distributed neural network training processes
- Higher resource requirements due to distributed computing nature of PySpark, which may incur additional costs
- Possible performance bottlenecks when scaling neural network training on large datasets across a cluster
- Steep learning curve for beginners due to the combined complexity of PySpark and neural network development
1. Scalable
PySpark’s scalability is a game-changer for neural network training, as it enables distributed computing across multiple nodes in a cluster. This capability allows developers to efficiently train neural networks on large datasets that would be impractical to handle on a single machine. By leveraging PySpark’s distributed computing framework, users can harness the power of parallel processing to accelerate model training and achieve superior performance even when dealing with massive amounts of data.
2. Speed
One key advantage of using PySpark for neural networks is its speed. Apache Spark’s in-memory processing capability significantly accelerates computations when compared to traditional disk-based systems. By leveraging Spark’s ability to store data in memory and perform operations in parallel across a cluster of nodes, developers can achieve faster training times and more efficient processing of large datasets, enhancing the overall performance and scalability of neural network models.
3. Ease of Use
Python’s intuitive syntax combined with Spark’s powerful engine in PySpark makes building neural networks a straightforward process. The seamless integration of Python with Spark simplifies the development of complex neural network architectures, allowing developers to focus on model design and training rather than dealing with intricate technical details. This ease of use not only accelerates the development cycle but also enables both beginners and experienced practitioners to leverage the full potential of neural networks for machine learning tasks efficiently.
4. Parallel Processing
One significant advantage of utilizing PySpark for neural networks is its capability for parallel processing. By distributing computations across multiple nodes within a cluster, PySpark accelerates the model training process significantly. This parallel processing feature not only increases the speed of training neural networks but also enables efficient handling of large datasets, making it a valuable asset for developers seeking to build and train complex models at scale.
5. Fault Tolerance
Fault Tolerance is a crucial advantage of using PySpark for neural network tasks. Apache Spark’s built-in fault tolerance mechanism ensures that even in the event of node failures or errors during computation, the system can recover and continue processing data seamlessly. This reliability feature minimizes the risk of data loss or job failure, allowing neural network tasks to be executed with confidence and consistency, ultimately leading to more robust and dependable machine learning models.
6. Integration Flexibility
One key advantage of using PySpark for neural network development is its integration flexibility. PySpark has the capability to seamlessly integrate with popular deep learning frameworks such as TensorFlow and Keras, allowing developers to leverage these advanced tools for building sophisticated and powerful models. By combining the distributed computing capabilities of PySpark with the advanced features of TensorFlow and Keras, users can take their model development to the next level, enabling them to tackle complex machine learning tasks efficiently and effectively.
7. Resource Efficiency
Resource Efficiency is a key advantage of utilizing PySpark for neural network training. By leveraging multiple CPUs or GPUs in a cluster, developers can optimize resource utilization during the training process. Distributing the workload across different nodes allows for parallel processing, significantly reducing training times and improving overall efficiency. This capability not only speeds up model training but also maximizes the use of available computing resources, making PySpark an ideal choice for scaling neural network models to handle large datasets effectively.
8. Community Support
The PySpark community provides invaluable support through a wealth of resources, tutorials, and forums dedicated to sharing knowledge and addressing troubleshooting issues. This robust community network enables users to connect with experts, exchange ideas, and find solutions to challenges they may encounter while working with PySpark neural networks. By tapping into this community support system, users can enhance their understanding, improve their skills, and stay updated on the latest developments in PySpark technology.
9. Performance Optimization
Performance optimization is a key advantage of integrating neural networks with PySpark. By leveraging PySpark’s optimization techniques, developers can significantly enhance the performance of neural networks when working with large-scale datasets. These optimization methods help streamline computations, improve resource utilization, and ultimately boost the efficiency of training and inference processes for neural network models. As a result, users can achieve faster training times and more accurate predictions, making PySpark a valuable tool for maximizing the performance of neural networks in big data environments.
Limited native support for deep learning in Spark MLlib
One significant drawback of using PySpark for neural networks is the limited native support for deep learning within Spark MLlib, the machine learning library in Apache Spark. While Spark MLlib offers a wide range of traditional machine learning algorithms and tools for data processing, its support for deep learning models is currently constrained. This limitation can hinder developers who require advanced deep learning capabilities, such as complex neural network architectures or integration with popular deep learning frameworks like TensorFlow or PyTorch. As a result, users may need to explore alternative solutions or third-party libraries to fully leverage the potential of deep learning in their PySpark projects.
Complexity in integrating external deep learning frameworks like TensorFlow or Keras with PySpark
One significant challenge when working with PySpark neural networks is the complexity involved in integrating external deep learning frameworks such as TensorFlow or Keras. While PySpark offers a robust distributed computing environment for processing big data, its native support for deep learning is limited in Spark MLlib. This limitation necessitates the use of additional libraries like TensorFlowOnSpark or Elephas to bridge the gap between PySpark and popular deep learning frameworks. The integration process can be intricate and require a deep understanding of both PySpark’s distributed computing model and the intricacies of external deep learning libraries, adding a layer of complexity to developing neural network models within the PySpark ecosystem.
Potential challenges in debugging and troubleshooting distributed neural network training processes
One significant challenge in utilizing PySpark for distributed neural network training processes is the complexity involved in debugging and troubleshooting. When training neural networks across multiple nodes in a cluster, issues such as communication errors, data inconsistencies, and resource contention can arise, making it challenging to pinpoint the root cause of performance issues or errors. Debugging distributed neural network training processes requires a deep understanding of both PySpark’s distributed computing framework and neural network architecture, as well as expertise in diagnosing and resolving issues that may occur at scale. Effective monitoring tools and logging mechanisms are essential to track the progress of training jobs and identify bottlenecks or failures in the system. Addressing these challenges demands careful attention to detail and a systematic approach to ensure the successful deployment and optimization of distributed neural network models using PySpark.
Higher resource requirements due to distributed computing nature of PySpark, which may incur additional costs
One significant drawback of utilizing neural networks with PySpark is the higher resource requirements resulting from its distributed computing nature. As PySpark operates across multiple nodes in a cluster to process large datasets efficiently, it demands more computational power and memory compared to running neural networks on a single machine. This increased resource demand can lead to higher infrastructure costs, including expenses for additional hardware, cloud services, and maintenance. Organizations considering implementing PySpark neural networks must carefully assess and budget for these potential additional costs to ensure cost-effectiveness and optimal resource allocation.
Possible performance bottlenecks when scaling neural network training on large datasets across a cluster
One significant drawback of utilizing PySpark for scaling neural network training on large datasets across a cluster is the potential for performance bottlenecks. As the dataset size increases and the neural network model becomes more complex, distributing the training process across multiple nodes in a cluster may lead to communication overhead and synchronization issues. These bottlenecks can result in longer training times, reduced efficiency, and increased resource consumption, ultimately impacting the scalability and effectiveness of the neural network training process. Addressing these performance challenges requires careful optimization of data partitioning, network communication, and resource allocation to ensure smooth and efficient distributed training on large datasets within a cluster environment.
Steep learning curve for beginners due to the combined complexity of PySpark and neural network development
One significant drawback of utilizing PySpark for neural network development is the steep learning curve it presents, especially for beginners. The complexity arises from the need to understand both PySpark’s distributed computing framework and the intricacies of neural network architecture and training. This dual challenge can be overwhelming for those new to either technology, requiring a substantial investment of time and effort to grasp the fundamentals and effectively leverage the combined power of PySpark and neural networks. As a result, novices may face hurdles in navigating through the complexities of these advanced tools, potentially slowing down their learning and development process in building scalable machine learning models.