The Power of Neural Networks in Text Classification
Neural networks have revolutionized the field of text classification, offering a sophisticated and efficient solution to automatically categorize and organize text data. By mimicking the human brain’s neural structure, these artificial intelligence models can learn patterns and relationships within textual information, making them ideal for tasks such as sentiment analysis, spam detection, and topic categorization.
How Neural Networks Work
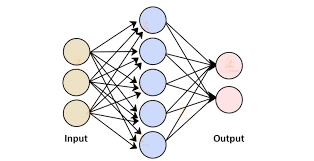
Neural networks consist of interconnected layers of artificial neurons that process input data and generate output predictions. In the context of text classification, the neural network receives textual input in the form of words or sequences of words, which are converted into numerical vectors through techniques like word embedding or one-hot encoding. These vectors are then fed into the neural network for processing.
As the data propagates through the network, each neuron performs computations on the input data based on learned weights and biases. The network adjusts these parameters during training through a process called backpropagation, where errors are minimized by updating the weights to improve prediction accuracy.
Benefits of Neural Networks in Text Classification
Neural networks offer several advantages in text classification tasks:
- Flexibility: Neural networks can handle complex relationships and non-linear patterns in text data, making them versatile for a wide range of classification tasks.
- Feature Learning: Neural networks can automatically learn relevant features from raw text data, reducing the need for manual feature engineering.
- Scalability: Neural networks can scale effectively with large datasets, providing robust performance even with vast amounts of textual information.
- Accuracy: With proper training and tuning, neural networks can achieve high levels of accuracy in classifying text data compared to traditional machine learning algorithms.
Applications of Neural Networks in Text Classification
The applications of neural networks in text classification are diverse and impactful:
- Sentiment Analysis: Neural networks can analyze sentiment from customer reviews, social media posts, or news articles to understand public opinion or customer feedback.
- Email Spam Detection: Neural networks can classify emails as spam or non-spam based on their content, helping users filter unwanted messages efficiently.
- Topic Categorization: Neural networks can categorize news articles or research papers into relevant topics or themes for easier organization and retrieval.
In Conclusion
The use of neural networks for text classification has transformed how we analyze and make sense of textual information. With their ability to learn complex patterns and relationships within text data, neural networks offer a powerful solution for automating classification tasks across various domains. As research continues to advance in this field, we can expect even more innovative applications and improvements in neural network-based text classification systems.
Understanding Neural Networks for Text Classification: FAQs and Insights
- What is a neural network and how is it used in text classification?
- How does training a neural network for text classification work?
- What are the advantages of using neural networks for text classification?
- Can neural networks handle different types of text data in classification tasks?
- What are some common challenges faced when implementing neural networks for text classification?
- Are there specific techniques or architectures recommended for optimizing neural networks in text classification?
What is a neural network and how is it used in text classification?
A neural network is a powerful artificial intelligence model inspired by the human brain’s neural structure. In the context of text classification, a neural network processes textual input data by converting it into numerical vectors and learning patterns and relationships within the text. By adjusting weights and biases through training, the neural network can make predictions about the category or sentiment of the text. Neural networks are used in text classification tasks to automatically categorize and organize textual information, enabling applications such as sentiment analysis, spam detection, and topic categorization with high accuracy and efficiency.
How does training a neural network for text classification work?
Training a neural network for text classification involves a process where the network learns to recognize patterns and relationships within textual data through iterative training on labeled examples. Initially, the neural network is initialized with random weights and biases. During training, the network processes input text data, computes predictions, compares them to the actual labels, and adjusts its parameters (weights and biases) using optimization algorithms like backpropagation to minimize prediction errors. This iterative process of feeding input data, calculating predictions, and updating parameters continues until the network converges to a state where it can accurately classify text data into predefined categories. By fine-tuning its parameters based on the training data, the neural network gradually improves its ability to generalize and make accurate predictions on unseen text samples.
What are the advantages of using neural networks for text classification?
When it comes to text classification, the advantages of using neural networks are significant. Neural networks offer unparalleled flexibility in handling complex relationships and patterns within textual data, making them versatile for a wide range of classification tasks. One key advantage is their ability to automatically learn relevant features from raw text data, reducing the need for manual feature engineering. Additionally, neural networks can scale effectively with large datasets, providing robust performance even with vast amounts of textual information. With proper training and tuning, neural networks can achieve high levels of accuracy in classifying text data compared to traditional machine learning algorithms, making them a powerful tool for text classification tasks.
Can neural networks handle different types of text data in classification tasks?
One frequently asked question regarding neural networks for text classification is whether they can handle different types of text data in classification tasks. The answer is yes, neural networks are highly versatile and can effectively process various types of textual information for classification purposes. Whether it’s short text snippets, long-form articles, social media posts, or technical documents, neural networks can learn patterns and relationships within the data to make accurate predictions. With proper training and tuning, neural networks can adapt to different text structures, languages, and domains, making them a powerful tool for handling diverse text data in classification tasks.
What are some common challenges faced when implementing neural networks for text classification?
When implementing neural networks for text classification, several common challenges may arise. One significant challenge is handling the complexity and variability of natural language, as text data can contain nuances, ambiguities, and irregularities that make it challenging for neural networks to accurately classify. Another challenge is the need for large amounts of labeled training data to train the neural network effectively, which can be time-consuming and costly to acquire. Additionally, selecting the right architecture, hyperparameters, and optimization techniques for the neural network can be a daunting task that requires expertise and experimentation to achieve optimal performance. Lastly, interpreting and explaining the decisions made by neural networks in text classification tasks can be difficult due to their black-box nature, raising concerns about transparency and interpretability in real-world applications. Addressing these challenges through careful design, data preparation, and model evaluation is crucial for successful implementation of neural networks in text classification tasks.
Are there specific techniques or architectures recommended for optimizing neural networks in text classification?
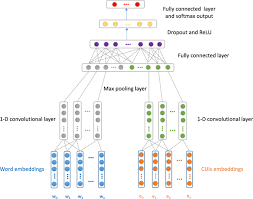
When it comes to optimizing neural networks for text classification, there are several techniques and architectures that are commonly recommended to enhance performance and accuracy. One popular approach is the use of recurrent neural networks (RNNs) or their variants, such as long short-term memory (LSTM) or gated recurrent units (GRUs), which are well-suited for processing sequential data like text. Additionally, techniques like word embeddings, attention mechanisms, and transfer learning can be beneficial in improving the network’s ability to understand and classify textual information effectively. Experimenting with different network architectures, tuning hyperparameters, and incorporating regularization techniques are also essential strategies for optimizing neural networks in text classification tasks.