Understanding the NARX Neural Network: A Powerful Tool for Time Series Prediction
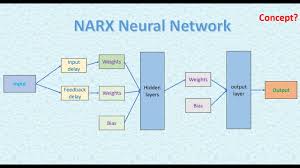
The Nonlinear Autoregressive with Exogenous Inputs (NARX) neural network is a type of recurrent dynamic network, widely used for modeling and predicting time series data. Its unique architecture makes it particularly effective in scenarios where the future state depends not only on past states but also on external inputs.
What is a NARX Neural Network?
A NARX neural network is designed to capture complex temporal patterns by leveraging both autoregressive and exogenous input components. The network predicts future values of a time series by considering:
- Autoregressive Component: This part of the model uses past values of the target variable to predict future values.
- Exogenous Inputs: These are additional inputs that can influence the target variable. They provide supplementary information that can enhance prediction accuracy.
Architecture of NARX Neural Networks
The architecture of a NARX neural network typically includes three layers:
- Input Layer: This layer receives both past values of the target variable and exogenous input data.
- Hidden Layer(s): These layers process the input data using nonlinear activation functions, allowing the network to learn complex relationships within the data.
- Output Layer: The final layer produces the predicted value for the next time step.
The feedback loop in NARX networks allows them to maintain memory of previous states, which is crucial for capturing temporal dependencies in time series data.
Applications of NARX Neural Networks
NARX neural networks are employed in various fields due to their ability to model dynamic systems accurately. Some common applications include:
- Financial Forecasting: Predicting stock prices or economic indicators based on historical data and external factors such as interest rates or market indices.
- Meteorology: Weather prediction models that incorporate historical weather patterns along with exogenous variables like atmospheric pressure or temperature readings from different locations.
- Control Systems: Designing controllers for dynamic systems where predictions about future states can optimize performance or stability.
The Advantages of Using NARX Neural Networks
NARX networks offer several advantages over traditional time series models, including:
- Coping with Nonlinearity: The nonlinear activation functions allow these networks to model complex relationships more effectively than linear models.
- Incorporating External Information: By using exogenous inputs, NARX networks can leverage additional context that might be missing from autoregressive approaches alone.
- Dynamically Adapting to Changes: The recurrent nature enables them to adjust predictions based on new information continuously, making them robust against changes in underlying patterns over time.
Conclusion
The NARX neural network stands out as a powerful tool for time series prediction due to its ability to integrate past observations with relevant external factors. As technology evolves and datasets grow larger and more complex, these networks will continue to play an essential role in fields requiring accurate forecasting and modeling capabilities. Whether it’s predicting financial markets or optimizing industrial processes, understanding how to harness the potential of NARX neural networks can provide significant advantages across numerous domains.
8 Essential Tips for Optimizing NARX Neural Networks
- Ensure you have enough data for training to avoid overfitting.
- Normalize input and output data to improve training performance.
- Experiment with different network architectures to find the most suitable one for your problem.
- Regularize the network using techniques like dropout or L2 regularization to prevent overfitting.
- Use appropriate activation functions such as ReLU or sigmoid in hidden layers for better convergence.
- Monitor training progress by visualizing metrics like loss and accuracy to make informed decisions.
- Consider using batch normalization to speed up training and improve generalization.
- Tune hyperparameters like learning rate, batch size, and number of epochs for optimal performance.
Ensure you have enough data for training to avoid overfitting.
It is crucial to ensure that you have an ample amount of data for training when working with NARX neural networks to prevent overfitting. Overfitting occurs when a model learns the training data too well, capturing noise or random fluctuations rather than true patterns. By providing a sufficient quantity of diverse and representative data during training, the network can better generalize and make accurate predictions on unseen data. Adequate data helps the NARX neural network learn meaningful relationships and avoid memorizing specific instances, ultimately improving its performance and reliability in time series prediction tasks.
Normalize input and output data to improve training performance.
Normalizing input and output data is a crucial tip for enhancing the training performance of NARX neural networks. By scaling the input and output variables to a consistent range, such as between 0 and 1 or using standardization techniques, we can prevent large values from dominating the learning process and ensure that the network can effectively learn from all features equally. Normalization helps in speeding up convergence, reducing the risk of vanishing or exploding gradients, and improving the overall stability and accuracy of the model during training. This simple yet effective preprocessing step can significantly boost the performance and efficiency of NARX networks in handling time series data with varying scales and distributions.
Experiment with different network architectures to find the most suitable one for your problem.
To optimize the performance of your NARX neural network, it is crucial to experiment with various network architectures to identify the most suitable one for your specific problem. By exploring different configurations of layers, neurons, and activation functions, you can fine-tune the model to better capture the complex temporal patterns in your time series data. Adjusting the architecture allows you to enhance the network’s ability to learn from past observations and external inputs, ultimately improving its predictive accuracy and overall effectiveness in solving your particular prediction task.
Regularize the network using techniques like dropout or L2 regularization to prevent overfitting.
To enhance the performance and generalization ability of a NARX neural network, it is crucial to incorporate regularization techniques such as dropout or L2 regularization. Overfitting, a common issue in neural network training, occurs when the model learns noise present in the training data rather than capturing underlying patterns. By applying dropout or L2 regularization, the network’s complexity is effectively controlled, preventing it from memorizing noise and improving its ability to generalize well to unseen data. These regularization techniques play a vital role in ensuring that the NARX neural network maintains robustness and accuracy in time series prediction tasks.
Use appropriate activation functions such as ReLU or sigmoid in hidden layers for better convergence.
When working with NARX neural networks, it is crucial to select suitable activation functions, such as Rectified Linear Unit (ReLU) or sigmoid, for the hidden layers to ensure optimal convergence. Activation functions play a pivotal role in introducing nonlinearity and enabling the network to learn complex patterns effectively. ReLU is known for its simplicity and ability to mitigate the vanishing gradient problem, while sigmoid function can be useful for introducing non-linearity in specific cases. By choosing the right activation functions for the hidden layers, practitioners can enhance the network’s convergence speed and overall performance in time series prediction tasks.
Monitor training progress by visualizing metrics like loss and accuracy to make informed decisions.
Monitoring the training progress of a NARX neural network is essential for optimizing its performance. By visualizing metrics such as loss and accuracy throughout the training process, users can gain valuable insights into how well the model is learning and generalizing from the data. Tracking these metrics allows for informed decision-making, enabling adjustments to be made to the network’s architecture or hyperparameters as needed to improve its predictive capabilities. Ultimately, visualizing training metrics empowers users to fine-tune their NARX neural network effectively and achieve more accurate and reliable predictions in time series analysis.
Consider using batch normalization to speed up training and improve generalization.
When working with NARX neural networks, it is beneficial to consider incorporating batch normalization techniques to enhance the training process and boost overall generalization performance. By applying batch normalization, the network can stabilize and accelerate convergence during training by normalizing the input to each layer. This not only speeds up the optimization process but also helps prevent overfitting and improves the model’s ability to generalize well to unseen data. Integrating batch normalization into the NARX neural network architecture can lead to more efficient training and better overall predictive capabilities, making it a valuable strategy for optimizing performance in time series prediction tasks.
Tune hyperparameters like learning rate, batch size, and number of epochs for optimal performance.
To maximize the performance of a NARX neural network, it is crucial to tune hyperparameters such as learning rate, batch size, and number of epochs. Adjusting the learning rate controls how quickly the model adapts to the data, while optimizing the batch size can impact training efficiency and generalization. Additionally, fine-tuning the number of epochs ensures that the network converges to an optimal solution without overfitting or underfitting. By carefully selecting and adjusting these hyperparameters, practitioners can enhance the predictive accuracy and overall effectiveness of their NARX neural network models.