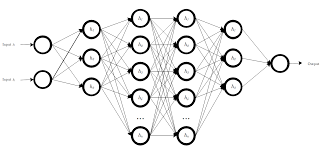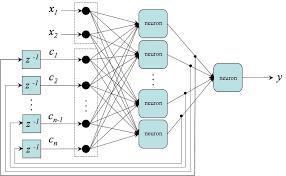
In the realm of artificial intelligence and machine learning, dynamic neural networks have emerged as a powerful tool for tackling complex problems and adapting to changing environments. Unlike traditional static neural networks, which have fixed architectures and weights, dynamic neural networks possess the ability to modify their structure and parameters during training or inference, enabling them to learn more efficiently and effectively.
One key advantage of dynamic neural networks is their flexibility in handling varying input sizes or types of data. By dynamically adjusting the network architecture based on the characteristics of the input data, these models can better capture intricate patterns and relationships within the information they process. This adaptability makes dynamic neural networks well-suited for tasks such as natural language processing, computer vision, and time series analysis.
Another benefit of dynamic neural networks is their capacity to handle sequential data with varying lengths. Recurrent neural networks (RNNs) and Long Short-Term Memory (LSTM) networks are popular examples of dynamic neural architectures that excel in processing sequences of data by maintaining internal states and selectively retaining or discarding information over time.
Furthermore, dynamic neural networks are instrumental in reinforcement learning settings where agents interact with an environment to learn optimal policies through trial and error. By dynamically adjusting network parameters in response to feedback from the environment, these models can adapt their behavior over time to achieve desired outcomes.
In conclusion, dynamic neural networks represent a significant advancement in the field of artificial intelligence, offering increased flexibility, adaptability, and performance compared to traditional static architectures. As researchers continue to explore novel techniques for enhancing the capabilities of dynamic neural networks, we can expect these models to play a crucial role in addressing challenging real-world problems across various domains.
7 Essential Tips for Optimizing Dynamic Neural Networks
- Start with a simple architecture and gradually increase complexity to avoid overfitting.
- Regularly monitor and adjust hyperparameters such as learning rate, batch size, and dropout rate.
- Utilize techniques like early stopping to prevent overfitting and save computational resources.
- Experiment with different activation functions to improve the performance of your dynamic neural network.
- Consider using techniques like batch normalization to speed up training and improve convergence.
- Implement appropriate weight initialization strategies to ensure stable training of your dynamic neural network.
- Visualize the intermediate layers and activations to gain insights into how information flows through your dynamic neural network.
Start with a simple architecture and gradually increase complexity to avoid overfitting.
When working with dynamic neural networks, a valuable tip is to begin with a straightforward architecture and incrementally introduce complexity to prevent overfitting. By starting with a simple model that captures the basic patterns in the data, you can build a solid foundation before incorporating additional layers or features. This gradual approach allows the network to learn progressively more intricate relationships within the data while avoiding the risk of memorizing noise or irrelevant details. By carefully managing the complexity of the model, you can strike a balance between capturing important patterns and generalizing well to unseen data, ultimately improving the performance and robustness of your dynamic neural network.
Regularly monitor and adjust hyperparameters such as learning rate, batch size, and dropout rate.
To optimize the performance of a dynamic neural network, it is crucial to regularly monitor and adjust key hyperparameters such as learning rate, batch size, and dropout rate. These hyperparameters play a critical role in determining the model’s learning dynamics, convergence speed, and generalization ability. By fine-tuning these parameters based on the specific characteristics of the data and the complexity of the task at hand, researchers and practitioners can enhance the network’s efficiency and effectiveness in capturing intricate patterns and relationships within the input data. Regularly evaluating and adjusting hyperparameters is essential for achieving optimal performance and ensuring that the dynamic neural network adapts effectively to changing conditions during training and inference.
Utilize techniques like early stopping to prevent overfitting and save computational resources.
When working with dynamic neural networks, it is essential to employ strategies like early stopping to mitigate the risk of overfitting and optimize computational efficiency. Early stopping involves monitoring the model’s performance on a validation dataset during training and halting the training process when the performance starts to deteriorate, indicating that the model is overfitting the training data. By implementing early stopping, practitioners can prevent the network from memorizing noise in the training data and ensure that it generalizes well to unseen data, ultimately saving valuable computational resources and improving overall model performance.
Experiment with different activation functions to improve the performance of your dynamic neural network.
When working with dynamic neural networks, it is essential to experiment with different activation functions to enhance the performance of your model. Activation functions play a crucial role in determining the non-linear behavior of neural networks and can significantly impact their ability to learn complex patterns in data. By trying out various activation functions such as ReLU, Sigmoid, Tanh, or Leaky ReLU, you can fine-tune the behavior of your dynamic neural network and improve its overall performance in terms of accuracy and convergence speed. Selecting the right activation function tailored to your specific problem domain can make a substantial difference in the effectiveness of your model’s learning process.
Consider using techniques like batch normalization to speed up training and improve convergence.
When working with dynamic neural networks, it is essential to consider incorporating techniques like batch normalization to enhance training efficiency and convergence. Batch normalization helps stabilize and accelerate the training process by normalizing the input data within each mini-batch, reducing internal covariate shift and enabling faster convergence of the network. By ensuring that the network’s activations remain within a reasonable range throughout training, batch normalization can lead to more stable gradients, faster learning rates, and ultimately improved performance of dynamic neural networks across various tasks.
Implement appropriate weight initialization strategies to ensure stable training of your dynamic neural network.
Implementing appropriate weight initialization strategies is crucial for ensuring the stable training of your dynamic neural network. Properly initializing the weights of the network can help prevent issues such as vanishing or exploding gradients, which can hinder the convergence of the model during training. By choosing suitable initialization techniques, such as Xavier or He initialization, you can provide a good starting point for the optimization process and facilitate smoother learning dynamics in your dynamic neural network. This careful consideration of weight initialization strategies can greatly impact the overall performance and effectiveness of your model in handling complex tasks and adapting to changing data patterns.
Visualize the intermediate layers and activations to gain insights into how information flows through your dynamic neural network.
To gain a deeper understanding of how information flows through your dynamic neural network, a valuable tip is to visualize the intermediate layers and activations. By examining the activations at different stages of the network, you can gain insights into the transformations that occur as data passes through each layer. Visualizing these intermediate representations can help you identify patterns, anomalies, and areas where the model may be struggling to learn effectively. This approach not only enhances your understanding of the network’s inner workings but also enables you to make informed decisions about optimizing model performance and improving overall accuracy.