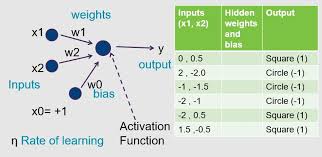
Neural networks have become a fundamental concept in the field of artificial intelligence and machine learning. Among the various types of neural networks, the basic neural network, also known as a feedforward neural network, serves as the foundation for more complex architectures.
A basic neural network consists of layers of interconnected nodes, or neurons. These nodes are organized into input, hidden, and output layers. The input layer receives the initial data, which is then processed through multiple hidden layers before producing an output in the final layer.
Each connection between nodes is associated with a weight that determines the strength of the connection. During the training process, these weights are adjusted through a method called backpropagation, where errors in prediction are used to update the weights and improve the network’s accuracy.
The activation function plays a crucial role in determining whether a neuron should be activated or not based on the input it receives. Common activation functions include sigmoid, tanh, ReLU (Rectified Linear Unit), and softmax, each serving different purposes in enhancing the network’s performance.
One of the key advantages of basic neural networks is their ability to learn complex patterns and relationships within data without explicit programming. This makes them highly versatile for tasks such as image recognition, natural language processing, and predictive analytics.
While basic neural networks are effective for many applications, they do have limitations such as overfitting with large datasets and slow convergence rates. To address these issues, researchers have developed more advanced architectures like convolutional neural networks (CNNs) and recurrent neural networks (RNNs) that excel in specific domains.
In conclusion, understanding the principles of basic neural networks is essential for delving into the world of artificial intelligence and machine learning. By grasping how these networks operate and evolve through training, individuals can harness their power to solve complex problems and drive innovation across various industries.
8 Fundamental Tips for Building and Optimizing Neural Networks
- Start with a simple neural network architecture before moving on to more complex ones.
- Ensure your input data is properly preprocessed and normalized for better training performance.
- Choose an appropriate activation function for the hidden layers, such as ReLU or sigmoid.
- Experiment with different optimizers like Adam, SGD, or RMSprop to find the best one for your model.
- Regularize your neural network using techniques like dropout or L2 regularization to prevent overfitting.
- Monitor the training process by visualizing metrics like loss and accuracy to make informed decisions for improvement.
- Fine-tune hyperparameters such as learning rate, batch size, and number of epochs to optimize model performance.
- Always split your dataset into training and validation sets to evaluate the generalization ability of your neural network.
Start with a simple neural network architecture before moving on to more complex ones.
It is recommended to begin your journey into neural networks by starting with a simple architecture before progressing to more complex ones. By starting with a basic neural network structure, you can grasp the fundamental concepts and principles that govern neural network operations. This approach allows you to build a strong foundation of understanding on which you can gradually expand and explore more intricate architectures like convolutional neural networks and recurrent neural networks. Starting simple not only helps in comprehending the core concepts effectively but also enables a smoother transition to mastering advanced neural network models in the future.
Ensure your input data is properly preprocessed and normalized for better training performance.
Ensuring your input data is properly preprocessed and normalized is crucial for optimizing the training performance of a basic neural network. By preprocessing the data, such as handling missing values, removing outliers, and encoding categorical variables, you can improve the network’s ability to learn meaningful patterns from the input. Normalizing the data by scaling it to a standard range helps prevent certain features from dominating others during training, leading to more stable and efficient learning. These preprocessing steps play a significant role in enhancing the overall performance and accuracy of the neural network model.
Choose an appropriate activation function for the hidden layers, such as ReLU or sigmoid.
When building a basic neural network, selecting the right activation function for the hidden layers is crucial for optimizing performance and accuracy. Popular choices like ReLU (Rectified Linear Unit) and sigmoid have distinct characteristics that can impact how the network learns and processes information. ReLU is known for its simplicity and effectiveness in addressing the vanishing gradient problem, while sigmoid is commonly used for binary classification tasks due to its smooth output range between 0 and 1. By carefully choosing an appropriate activation function based on the nature of the data and task at hand, one can enhance the network’s ability to capture complex patterns and improve overall predictive capabilities.
Experiment with different optimizers like Adam, SGD, or RMSprop to find the best one for your model.
To enhance the performance of your basic neural network model, it is recommended to experiment with various optimizers such as Adam, SGD, or RMSprop. Each optimizer has its own strengths and weaknesses in optimizing the network’s weights during training. By testing different optimizers and observing how they impact the model’s convergence speed and accuracy, you can determine which one works best for your specific dataset and architecture. This iterative process of optimizer selection plays a crucial role in fine-tuning your neural network to achieve optimal results in terms of training efficiency and predictive accuracy.
Regularize your neural network using techniques like dropout or L2 regularization to prevent overfitting.
To enhance the performance and generalization of your basic neural network, it is crucial to implement regularization techniques such as dropout or L2 regularization. Overfitting occurs when a neural network learns the training data too well, leading to poor performance on unseen data. Dropout randomly deactivates a portion of neurons during training, forcing the network to rely on different pathways and preventing over-reliance on specific features. On the other hand, L2 regularization adds a penalty term to the loss function based on the magnitude of weights, discouraging overly complex models. By incorporating these regularization methods into your neural network, you can effectively combat overfitting and improve its ability to generalize to new data.
Monitor the training process by visualizing metrics like loss and accuracy to make informed decisions for improvement.
Monitoring the training process of a basic neural network by visualizing metrics such as loss and accuracy is crucial for making informed decisions on how to improve the model. By tracking these key indicators throughout the training phase, developers and researchers can gain valuable insights into the network’s performance and identify areas that require adjustment or optimization. Analyzing the trends in loss and accuracy helps in fine-tuning the network’s parameters, adjusting the learning rate, or implementing regularization techniques to enhance its overall effectiveness and efficiency.
Fine-tune hyperparameters such as learning rate, batch size, and number of epochs to optimize model performance.
To optimize the performance of a basic neural network, it is crucial to fine-tune hyperparameters such as the learning rate, batch size, and number of epochs. The learning rate determines how quickly the model adapts to the training data, while the batch size affects the efficiency of parameter updates during training. Additionally, adjusting the number of epochs controls how many times the model iterates over the entire dataset. By carefully optimizing these hyperparameters, researchers and developers can enhance the accuracy and efficiency of their neural network models for better results in various applications.
Always split your dataset into training and validation sets to evaluate the generalization ability of your neural network.
It is crucial to always split your dataset into training and validation sets when working with a basic neural network. This practice allows you to assess the generalization ability of your model by training it on one subset of data and evaluating its performance on another independent subset. By doing so, you can prevent overfitting and ensure that your neural network can effectively generalize to unseen data, ultimately improving its reliability and predictive accuracy.