
Unveiling the Synergy of Artificial Intelligence and Machine Learning
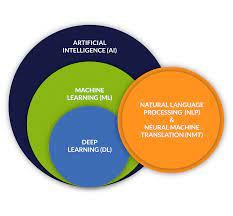
In the realm of technological advancements, two terms often dominate conversations: Artificial Intelligence (AI) and Machine Learning (ML). These concepts, while interconnected, are distinct in their applications and implications for the future. Understanding how they work together is key to grasping the potential they hold for transforming industries and everyday life.
Artificial intelligence is a broad field that aims to create machines capable of performing tasks that typically require human intelligence. This includes problem-solving, recognizing speech, translating languages, and more. AI systems are designed to mimic or even enhance human cognitive functions.
Machine learning, on the other hand, is a subset of AI focused on developing algorithms that enable computers to learn from and make decisions based on data. Unlike traditional programming where rules are explicitly coded into software, ML allows systems to learn these rules by identifying patterns in data.
The synergy between AI and ML can be seen in numerous applications across various sectors:
Healthcare: AI-powered diagnostic tools use ML algorithms to analyze medical images like X-rays or MRIs more quickly and accurately than ever before. These tools can detect abnormalities that might be overlooked by human eyes, leading to early intervention and better patient outcomes.
Finance: In finance, ML models are used for algorithmic trading, fraud detection, and risk management. By processing vast amounts of market data, these models can identify profitable trading opportunities or flag potentially fraudulent transactions with a level of speed and accuracy unattainable by humans alone.
Automotive: The automotive industry is being revolutionized by AI with the advent of autonomous vehicles. Self-driving cars use ML to process sensory data from their surroundings—such as cameras, radar, and LIDAR—to navigate safely without human intervention.
Retail: Retailers leverage ML algorithms for personalized marketing by analyzing customer data to predict shopping habits and preferences. This enables businesses to tailor recommendations and offers to individual consumers effectively driving sales and enhancing customer satisfaction.
Despite its promise, integrating AI with ML also presents challenges. Concerns about privacy arise as systems require access to large amounts of personal data for learning purposes. There’s also the issue of bias; if an ML algorithm is trained on skewed data sets, it may produce biased results.
Moreover, as these technologies advance rapidly there’s an ongoing debate about the impact on employment with fears that AI could automate jobs currently performed by humans.
Looking ahead it’s clear that AI and machine learning will continue shaping innovation across every sector imaginable. The key will be harnessing this potential responsibly ensuring these technologies serve humanity’s best interests without compromising ethical standards or societal welfare.
As research progresses so too will understanding how best to utilize AI in harmony with machine learning not only for economic growth but also for societal advancement ensuring a future where technology augments human capabilities rather than replaces them.
6 Essential Tips for Mastering Artificial Intelligence Machine Learning
- Understand the basics of machine learning algorithms such as regression, classification, and clustering.
- Collect and prepare high-quality data for training your machine learning models.
- Choose the right evaluation metrics to measure the performance of your models accurately.
- Regularly update and retrain your models to adapt to changing patterns in data.
- Consider using ensemble methods like random forests or gradient boosting for improved model performance.
- Stay up-to-date with advancements in AI and ML by following research papers, online courses, and attending conferences.
Understand the basics of machine learning algorithms such as regression, classification, and clustering.
Unlocking the Power of Machine Learning Algorithms: Regression, Classification, and Clustering
In the realm of artificial intelligence and machine learning, understanding the basics of machine learning algorithms is essential. These algorithms serve as the building blocks that enable computers to learn from data and make intelligent decisions. Among the fundamental concepts are regression, classification, and clustering.
Regression is a powerful algorithm used to predict continuous numerical values. It aims to find the relationship between input variables (also known as features) and an output variable by fitting a mathematical function to the data. Regression models can be used for various purposes, such as predicting sales figures based on historical data or estimating housing prices based on factors like location, size, and amenities.
Classification is another vital machine learning algorithm that deals with predicting discrete outcomes or assigning data points to predefined categories. It involves training a model on labeled data, where each observation is assigned a specific class or category. The trained model can then be used to classify new, unlabeled data points based on their features. Classification algorithms are widely used in spam email detection, sentiment analysis of social media posts, or even medical diagnosis.
Clustering is an unsupervised learning algorithm that groups similar data points together based on their intrinsic characteristics. Unlike classification where categories are predefined, clustering aims to discover patterns or structures within the data without any prior knowledge of how it should be grouped. This algorithm is particularly useful for customer segmentation in marketing analysis or identifying anomalies in network traffic for cybersecurity purposes.
Understanding these basic machine learning algorithms opens up a world of possibilities for solving complex problems and extracting valuable insights from data. By grasping regression’s ability to predict continuous values accurately or classification’s power in categorizing information effectively, one can make informed decisions and drive meaningful outcomes.
Moreover, clustering provides a means to uncover hidden patterns within datasets that may lead to breakthrough discoveries or improved decision-making processes.
As with any tool, it is important to choose the right algorithm for the task at hand. Each algorithm has its strengths and limitations, and understanding their nuances allows for optimal utilization. Additionally, keeping up with advancements in machine learning research and exploring more advanced algorithms can further enhance one’s capabilities in harnessing the power of AI.
By delving into the basics of machine learning algorithms such as regression, classification, and clustering, individuals can embark on a journey to unlock the true potential of artificial intelligence. Whether it’s predicting future trends, classifying data accurately, or discovering hidden patterns, these algorithms serve as invaluable tools that empower us to make informed decisions and drive innovation in an increasingly data-driven world.
Collect and prepare high-quality data for training your machine learning models.
The Foundation of Successful Machine Learning: High-Quality Data Collection and Preparation
In the realm of machine learning, the old saying “garbage in, garbage out” holds true. The success of any machine learning model heavily relies on the quality of the data used for training. Collecting and preparing high-quality data is an essential step that cannot be overlooked.
When it comes to machine learning, data acts as the fuel that powers the algorithms. Without accurate and representative data, models may produce inaccurate or biased results, rendering them ineffective or even counterproductive.
So, how can we ensure that we collect and prepare high-quality data for training our machine learning models? Here are a few key considerations:
- Define clear objectives: Start by clearly defining the objectives of your machine learning project. What problem are you trying to solve? What insights are you seeking? Having a well-defined goal will help guide your data collection efforts and ensure you gather relevant information.
- Identify reliable sources: Look for reliable and reputable sources to collect your data from. Depending on your project, this could include public datasets, proprietary databases, web scraping tools, or even manual data entry. It’s crucial to verify the credibility and accuracy of your data sources to avoid introducing biases or errors into your model.
- Cleanse and preprocess your data: Raw data often contains inconsistencies, missing values, outliers, or noise that can adversely affect model performance. Take the time to clean and preprocess your data by removing duplicates, handling missing values appropriately (e.g., imputing or discarding), addressing outliers, and normalizing or scaling variables as needed.
- Ensure diversity and representativeness: Aim for a diverse dataset that accurately represents the real-world scenarios you want your model to handle. Including a wide range of examples across different demographics, geographies, or contexts helps prevent bias in predictions while improving generalization capabilities.
- Label and annotate your data: In supervised learning, where models learn from labeled examples, ensure that your data is properly labeled and annotated. This process requires human expertise to correctly assign labels or categories to each data point. Consistency and accuracy in labeling are crucial for training effective models.
- Validate and iterate: After preparing your dataset, it’s essential to perform validation and iteration cycles. Split your data into training, validation, and test sets to evaluate model performance accurately. Continuously monitor the results, fine-tune your model, and iterate on the data collection or preparation process as necessary.
Remember, the quality of your machine learning model is directly linked to the quality of the data it is trained on. By investing time and effort into collecting and preparing high-quality data, you lay a solid foundation for building accurate, reliable, and robust machine learning models that can deliver valuable insights and drive impactful solutions.
Choose the right evaluation metrics to measure the performance of your models accurately.
Choosing the Right Yardstick: The Importance of Evaluation Metrics in AI Machine Learning
In the intricate dance of artificial intelligence and machine learning, crafting an algorithm is only part of the equation. The true measure of a model’s effectiveness lies in its evaluation — determining how well it performs its intended task. This is where the selection of appropriate evaluation metrics becomes crucial.
Evaluation metrics are the benchmarks that provide insight into a model’s accuracy, precision, and ability to generalize beyond the data on which it was trained. They are not merely statistical tools; they are fundamental to guiding model improvement and ensuring that AI systems deliver reliable and beneficial outcomes.
One common pitfall in machine learning projects is the reliance on default or familiar metrics without considering their relevance to the specific problem at hand. For instance, accuracy might seem like a natural choice for classification tasks, but it can be misleading when dealing with imbalanced datasets where one class significantly outnumbers another. In such scenarios, other metrics like precision, recall, or the F1 score provide a more nuanced view of performance.
In regression tasks where models predict continuous outcomes, metrics like mean squared error (MSE) or mean absolute error (MAE) are often used. However, depending on the context, these may not capture performance aspects that are critical for a particular application. For example, if large errors are particularly undesirable in a forecasting task, one might opt for mean squared logarithmic error (MSLE) instead.
The choice of evaluation metric also has ethical implications. In fields such as healthcare or criminal justice where AI decisions have significant human impact, it’s essential to consider fairness and bias as part of model assessment. This means going beyond traditional performance measures to include metrics that evaluate equity across different demographic groups.
Moreover, in real-world applications where multiple objectives must be balanced — such as maximizing predictive performance while minimizing cost — composite evaluation frameworks may be necessary to capture all relevant dimensions of model success.
Ultimately, selecting the right evaluation metrics requires a deep understanding of both the mathematical underpinnings of machine learning models and the practical realities of their deployment. It involves asking hard questions about what success looks like and being willing to iterate on both model design and metric selection until this alignment is achieved.
As AI continues its march into diverse facets of life and business, those who harness its power must do so with thoughtful consideration for how they measure success. By choosing appropriate evaluation metrics from the outset, practitioners ensure they’re not just creating models that work on paper but delivering AI solutions that perform robustly in the complex tapestry of real life.
Regularly update and retrain your models to adapt to changing patterns in data.
Staying Ahead of the Curve: The Importance of Updating and Retraining AI Machine Learning Models
In the dynamic world of artificial intelligence and machine learning, staying current is not just an advantage—it’s a necessity. As these technologies become increasingly embedded in various aspects of business and daily life, it’s crucial to recognize that machine learning models are not set-it-and-forget-it solutions. To maintain their accuracy and effectiveness, these models must be regularly updated and retrained to adapt to changing patterns in data.
Machine learning models are built on historical data; they identify patterns and make predictions based on past observations. However, over time, the underlying data can change due to evolving market trends, consumer behaviors, or environmental shifts. These changes can render previously learned patterns obsolete, leading to a decline in model performance—a phenomenon known as “model drift.”
To combat model drift and ensure that AI systems continue to deliver high-quality outputs, it is essential to implement a strategy for continuous improvement. Regular updates and retraining with new data allow models to learn from recent trends and adjust their algorithms accordingly.
For instance, an e-commerce recommendation system trained on last year’s shopping data may not accurately predict this year’s holiday shopping trends if consumer preferences have shifted significantly. By continuously feeding the model with up-to-date transactional data, it can recalibrate its recommendations to align with current consumer behavior.
Moreover, retraining models is not just about maintaining performance; it’s also about capitalizing on new opportunities. In sectors like finance or healthcare where real-time decisions are critical, a model that adapts quickly to new patterns can provide a competitive edge or improve patient outcomes.
However, updating and retraining models come with challenges. It requires a thoughtful approach that balances frequency of updates with computational costs and potential disruptions in service. Organizations must also be vigilant about the quality of new data being used for retraining since poor quality data can lead to inaccuracies in predictions.
Additionally, ethical considerations must be taken into account when updating models. Ensuring that new data does not introduce bias is paramount for maintaining fairness and transparency in AI-driven decisions.
In conclusion, regular updates and retraining are vital practices for anyone leveraging machine learning technology. They ensure that AI systems remain accurate, relevant, and valuable over time—adapting alongside an ever-changing world. By embracing these practices, organizations can continue harnessing the power of AI while safeguarding against the risks associated with static models.
Consider using ensemble methods like random forests or gradient boosting for improved model performance.
Boosting Model Performance with Ensemble Methods: Random Forests and Gradient Boosting
When it comes to harnessing the power of artificial intelligence and machine learning, one tip that experts often recommend is to consider using ensemble methods like random forests or gradient boosting. These techniques have proven to be highly effective in improving model performance and producing more accurate predictions.
Ensemble methods work by combining multiple individual models, known as base learners, to create a stronger and more robust predictive model. Random forests and gradient boosting are two popular ensemble methods that have gained significant attention in the field.
Random forests operate by constructing a multitude of decision trees during the training phase. Each tree is built on a different subset of the training data, and the final prediction is determined through a voting or averaging process across all the trees. This approach helps to reduce overfitting, increase stability, and improve generalization capabilities.
On the other hand, gradient boosting focuses on building an ensemble of weak learners iteratively. It starts with an initial model and then adds subsequent models that correct errors made by previous models. By continuously refining predictions based on previous mistakes, gradient boosting gradually creates a strong predictive model that can handle complex relationships within the data.
Both random forests and gradient boosting offer several advantages over standalone models:
- Improved Accuracy: Ensemble methods often outperform individual models by reducing bias and variance in predictions. The combination of multiple models helps capture different aspects of the data, resulting in more accurate overall predictions.
- Robustness: Ensemble methods are less prone to overfitting compared to single models. By aggregating predictions from multiple base learners, they can better handle noise or outliers in the data, leading to increased robustness.
- Feature Importance: Ensemble methods provide insights into feature importance, allowing users to identify which variables have a significant impact on predictions. This information can be valuable for feature selection or understanding underlying patterns within the dataset.
However, it’s important to note that ensemble methods are not a one-size-fits-all solution. They require careful parameter tuning and can be computationally expensive, especially when dealing with large datasets. Additionally, interpretability may be compromised as ensemble models are more complex than individual models.
In conclusion, if you’re looking to enhance your model’s performance in artificial intelligence and machine learning projects, considering ensemble methods like random forests or gradient boosting is a wise choice. These techniques offer improved accuracy, robustness, and insights into feature importance. By leveraging the power of ensemble methods, you can unlock the full potential of your predictive models and make more accurate predictions in various domains.
Stay up-to-date with advancements in AI and ML by following research papers, online courses, and attending conferences.
Staying Current: The Importance of Keeping Pace with AI and ML Innovations
In the rapidly evolving fields of Artificial Intelligence (AI) and Machine Learning (ML), staying informed about the latest advancements is not just beneficial—it’s essential. For professionals, academics, and enthusiasts alike, keeping abreast of new developments can mean the difference between leading the curve or trailing behind it.
The pace at which AI and ML are advancing is nothing short of breathtaking. Breakthroughs in neural networks, deep learning architectures, reinforcement learning, and natural language processing are transforming what machines can do. As these technologies become more sophisticated, they open up possibilities that were previously in the realm of science fiction.
One of the best ways to stay updated with these changes is by following research papers. Academic journals like “Journal of Machine Learning Research,” “Neural Information Processing Systems,” and “IEEE Transactions on Pattern Analysis and Machine Intelligence” regularly publish cutting-edge research. For those without a formal background in these areas, platforms like arXiv.org provide free access to thousands of papers across AI and ML disciplines.
Online courses offer another avenue for education and skill development. Websites like Coursera, Udacity, edX, and Khan Academy host courses created by universities or industry leaders that range from introductory to advanced levels. These platforms often include hands-on projects that help learners apply theoretical knowledge in practical scenarios.
Furthermore, attending conferences is an invaluable way to connect with the community, learn from experts in the field, and witness firsthand demonstrations of new technologies. Conferences such as NeurIPS (Conference on Neural Information Processing Systems), ICML (International Conference on Machine Learning), and CVPR (Conference on Computer Vision and Pattern Recognition) are annual events where attendees can absorb insights from presentations, workshops, and discussions.
However, it’s not just about passive consumption; engaging with these resources provides an opportunity for networking with peers who share similar interests. It opens doors to collaborations that could lead to innovation or even breakthroughs within the field.
Professionals who invest time in staying current can bring valuable insights back to their organizations—leveraging new techniques to solve complex problems or identifying trends that could impact strategic decisions. For job seekers or students looking to enter this dynamic field, understanding the latest technologies can give them a competitive edge.
In conclusion, as AI and ML continue to advance at an astonishing rate, dedicating time for continuous learning through research papers online courses conferences becomes crucial for anyone involved in these sectors. Not only does this commitment enhance one’s knowledge base but it also ensures active participation in shaping future applications of these transformative technologies.


