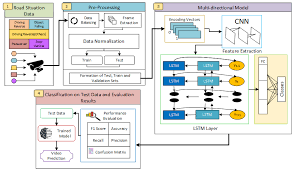
Recurrent Convolutional Neural Networks for Text Classification
Text classification is a fundamental task in natural language processing (NLP) that involves assigning predefined categories or labels to textual data. In recent years, deep learning models, such as recurrent neural networks (RNNs) and convolutional neural networks (CNNs), have shown remarkable performance in text classification tasks.
Recurrent Convolutional Neural Networks (RCNNs) combine the strengths of both RNNs and CNNs to improve the accuracy and efficiency of text classification models. In RCNNs, the input sequence is processed by a bidirectional RNN to capture contextual information, while a CNN is used to extract local features through convolutions.
The key advantage of RCNNs lies in their ability to effectively model long-range dependencies in text data using the recurrent connections of RNNs, while also capturing local patterns and features with the convolutional layers. This hybrid architecture enables RCNNs to achieve superior performance in tasks such as sentiment analysis, topic categorization, and document classification.
One common implementation of RCNN involves feeding the output of the bidirectional RNN into a max-pooling layer followed by a fully connected layer for classification. This architecture allows the model to learn hierarchical representations of text data at different levels of abstraction, leading to more accurate predictions.
Furthermore, RCNNs are known for their efficiency in training and inference due to their parallel processing capabilities and parameter sharing across layers. This makes them suitable for handling large-scale text datasets with millions of samples efficiently.
In conclusion, Recurrent Convolutional Neural Networks represent a powerful approach to text classification that combines the strengths of RNNs and CNNs. By leveraging both recurrent connections and convolutional operations, RCNNs can effectively capture both global context and local features in textual data, leading to state-of-the-art performance in various NLP tasks.
9 Essential Tips for Optimizing Recurrent Convolutional Neural Networks in Text Classification
- 1. Preprocess text data by tokenizing words and converting them to numerical representations.
- 2. Use pre-trained word embeddings like Word2Vec or GloVe to capture semantic meanings of words.
- 3. Combine convolutional layers for feature extraction with recurrent layers for capturing sequential information.
- 4. Experiment with different kernel sizes in the convolutional layers to extract features at various scales.
- 5. Consider using dropout regularization to prevent overfitting during training.
- 6. Utilize batch normalization to stabilize and accelerate training of the network.
- 7. Fine-tune hyperparameters such as learning rate, batch size, and number of epochs for optimal performance.
- 8. Implement early stopping based on validation loss to prevent model overfitting on the training data.
- 9. Evaluate model performance using metrics like accuracy, precision, recall, and F1-score.
1. Preprocess text data by tokenizing words and converting them to numerical representations.
To effectively utilize Recurrent Convolutional Neural Networks for text classification, it is essential to preprocess the text data by tokenizing words and converting them into numerical representations. This initial step is crucial as it enables the model to understand and process the textual information by transforming it into a format that can be interpreted and analyzed by the neural network. By tokenizing words and converting them into numerical vectors, the RCNN can effectively learn patterns, relationships, and features within the text data, ultimately enhancing its ability to classify and categorize textual information accurately.
2. Use pre-trained word embeddings like Word2Vec or GloVe to capture semantic meanings of words.
Utilizing pre-trained word embeddings such as Word2Vec or GloVe is a valuable strategy when implementing recurrent convolutional neural networks for text classification. These embeddings capture the semantic meanings of words by representing them in a high-dimensional vector space, where words with similar meanings are located closer to each other. By incorporating these pre-trained word embeddings into the model, the RCNN can leverage rich semantic information to enhance its understanding of textual data, ultimately improving classification accuracy and performance.
3. Combine convolutional layers for feature extraction with recurrent layers for capturing sequential information.
To enhance the performance of text classification models, it is recommended to combine convolutional layers for feature extraction with recurrent layers for capturing sequential information. By integrating the strengths of both convolutional and recurrent neural networks, this approach allows the model to extract local features efficiently while also capturing long-range dependencies in the input text data. This hybrid architecture enables the model to learn complex patterns and relationships within the text, leading to improved accuracy and effectiveness in tasks such as sentiment analysis and document classification.
4. Experiment with different kernel sizes in the convolutional layers to extract features at various scales.
To enhance the performance of recurrent convolutional neural networks for text classification, it is recommended to experiment with different kernel sizes in the convolutional layers. By varying the kernel sizes, the network can extract features at various scales from the input text data. This approach allows the model to capture both local and global patterns in the text, leading to more robust and accurate classification results. Adjusting the kernel sizes in the convolutional layers enables the network to learn diverse representations of the input text, enhancing its ability to discern subtle nuances and context-dependent features for improved classification performance.
5. Consider using dropout regularization to prevent overfitting during training.
Consider using dropout regularization to prevent overfitting during training when implementing recurrent convolutional neural networks for text classification. Dropout is a regularization technique that helps improve the generalization ability of the model by randomly setting a fraction of input units to zero during each training iteration. This prevents the network from relying too heavily on specific features or patterns in the training data, ultimately reducing overfitting and improving the model’s performance on unseen data. By incorporating dropout regularization into the training process, you can enhance the robustness and accuracy of your RCNN model for text classification tasks.
6. Utilize batch normalization to stabilize and accelerate training of the network.
Batch normalization is a crucial technique to enhance the training process of recurrent convolutional neural networks for text classification. By normalizing the input data within each mini-batch during training, batch normalization helps stabilize and accelerate the convergence of the network. This technique reduces issues like internal covariate shift and allows for faster learning rates, leading to improved model performance and efficiency. By incorporating batch normalization into the training pipeline, practitioners can achieve better results in text classification tasks while ensuring the stability and robustness of the network throughout the training process.
7. Fine-tune hyperparameters such as learning rate, batch size, and number of epochs for optimal performance.
To optimize the performance of recurrent convolutional neural networks for text classification, it is crucial to fine-tune hyperparameters such as the learning rate, batch size, and number of epochs. Adjusting these hyperparameters can significantly impact the model’s training process and ultimately its accuracy and efficiency in classifying text data. By carefully selecting the appropriate values for these parameters through experimentation and validation, researchers and practitioners can achieve optimal performance and enhance the overall effectiveness of their text classification models based on recurrent convolutional neural networks.
8. Implement early stopping based on validation loss to prevent model overfitting on the training data.
To prevent model overfitting on the training data when using recurrent convolutional neural networks for text classification, it is advisable to implement early stopping based on validation loss. By monitoring the validation loss during training and stopping the training process when the loss starts to increase, this technique helps prevent the model from memorizing noise in the training data and generalizing poorly to unseen data. Early stopping based on validation loss serves as a crucial regularization method that promotes better generalization performance and improves the overall robustness of the text classification model.
9. Evaluate model performance using metrics like accuracy, precision, recall, and F1-score.
When working with recurrent convolutional neural networks for text classification, it is essential to evaluate the model’s performance using a variety of metrics such as accuracy, precision, recall, and F1-score. Accuracy measures the overall correctness of the model’s predictions, while precision quantifies the proportion of correctly predicted positive instances among all instances predicted as positive. Recall, on the other hand, calculates the proportion of correctly predicted positive instances out of all actual positive instances. The F1-score is a harmonic mean of precision and recall, providing a balanced measure that considers both false positives and false negatives. By analyzing these metrics, one can gain valuable insights into the model’s effectiveness in classifying text data accurately and reliably.