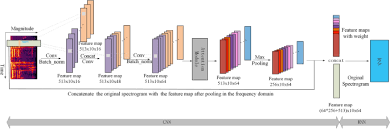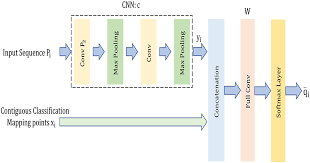
Convolutional Neural Network for Text Classification
Convolutional Neural Networks (CNNs) have gained significant popularity in the field of natural language processing, particularly for text classification tasks. Originally designed for image recognition, CNNs have proven to be highly effective in processing and analyzing textual data due to their ability to capture local patterns and dependencies within the text.
One of the key advantages of using CNNs for text classification is their capability to automatically learn hierarchical features at different levels of abstraction. In the context of text, this means that the network can identify important patterns such as word combinations, phrases, and sentence structures that are crucial for determining the category or sentiment of a given piece of text.
The basic architecture of a CNN for text classification typically involves several layers, including:
- Input Layer: Represents the input text data in vectorized form.
- Convolutional Layer: Applies filters over small sections of the input data to extract features.
- Pooling Layer: Reduces the dimensionality of the feature maps generated by the convolutional layer.
- Fully Connected Layer: Processes the pooled features and performs classification based on learned patterns.
During training, the CNN learns to adjust its parameters through backpropagation in order to minimize a loss function and improve its ability to correctly classify text samples into predefined categories or labels. With sufficient training data and proper tuning of hyperparameters, CNNs can achieve high accuracy rates in text classification tasks.
In conclusion, Convolutional Neural Networks offer a powerful and efficient approach to text classification by leveraging their ability to capture local features and hierarchies within textual data. As research in this area continues to advance, CNNs are expected to play an increasingly important role in various NLP applications, providing valuable insights and solutions for analyzing and understanding textual information.
6 Essential Tips for Enhancing Text Classification with Convolutional Neural Networks
- Preprocess text data by tokenizing and padding sequences for input to the CNN.
- Use pre-trained word embeddings like Word2Vec or GloVe to represent words in the text.
- Experiment with different filter sizes and number of filters in the convolutional layers.
- Include max pooling layers to capture the most important features from the convolutions.
- Regularize your model using techniques like dropout to prevent overfitting.
- Monitor training progress using metrics like accuracy and loss to optimize performance.
Preprocess text data by tokenizing and padding sequences for input to the CNN.
To optimize the performance of a Convolutional Neural Network for text classification, it is essential to preprocess the text data by tokenizing and padding sequences before feeding them into the CNN. Tokenization involves breaking down the text into individual words or tokens, which allows the network to understand and process the input more effectively. Padding sequences ensures that all input data is of uniform length, which is necessary for the CNN to operate efficiently. By following this preprocessing step, we can enhance the network’s ability to learn meaningful patterns and features from the text data, ultimately improving its accuracy in classifying text samples.
Use pre-trained word embeddings like Word2Vec or GloVe to represent words in the text.
Utilizing pre-trained word embeddings such as Word2Vec or GloVe is a highly recommended tip when implementing a Convolutional Neural Network for text classification. These embeddings provide a way to represent words in the text as dense vectors in a continuous space, capturing semantic relationships and contextual information. By leveraging pre-trained word embeddings, the model can benefit from transfer learning and have access to rich linguistic features without the need for extensive training data. This approach not only enhances the network’s ability to understand and interpret textual content more effectively but also helps improve overall classification performance by leveraging the knowledge embedded in these pre-trained word representations.
Experiment with different filter sizes and number of filters in the convolutional layers.
To enhance the performance of a Convolutional Neural Network for text classification, it is recommended to experiment with various filter sizes and the number of filters in the convolutional layers. By adjusting these parameters, researchers and practitioners can fine-tune the network’s ability to capture different patterns and features within the text data. Different filter sizes allow the CNN to analyze text at varying granularities, while increasing the number of filters can help extract a wider range of information from the input text. Through systematic experimentation and optimization of filter sizes and quantities, one can improve the model’s capacity to learn intricate relationships in textual data and enhance its overall classification accuracy.
Include max pooling layers to capture the most important features from the convolutions.
To enhance the performance of a Convolutional Neural Network for text classification, it is recommended to incorporate max pooling layers into the architecture. Max pooling layers play a crucial role in capturing the most significant features extracted by the convolutional layers. By selecting the maximum value from each feature map, max pooling helps to retain essential information while reducing the dimensionality of the data, leading to improved efficiency and effectiveness in identifying key patterns within the text data. Including max pooling layers enables the network to focus on extracting and emphasizing the most relevant features, ultimately enhancing its ability to make accurate classifications based on learned representations.
Regularize your model using techniques like dropout to prevent overfitting.
To enhance the performance of your Convolutional Neural Network for text classification, it is crucial to incorporate regularization techniques such as dropout. Dropout is a method that randomly deactivates a certain percentage of neurons during training, which helps prevent overfitting by reducing the network’s reliance on specific features or patterns in the data. By implementing dropout regularization, you can improve the generalization ability of your model and ensure that it performs well on unseen data, ultimately enhancing the overall accuracy and robustness of your text classification system.
Monitor training progress using metrics like accuracy and loss to optimize performance.
Monitoring training progress using metrics such as accuracy and loss is crucial for optimizing the performance of a convolutional neural network for text classification. By regularly evaluating these metrics during the training process, developers can gain valuable insights into how well the model is learning and adjusting its parameters to improve classification accuracy. Tracking the loss function helps in understanding how effectively the network is minimizing errors, while monitoring accuracy provides a measure of how well the model is performing on the classification task. By analyzing these metrics and making adjustments as needed, developers can fine-tune their CNN model to achieve optimal performance in text classification tasks.