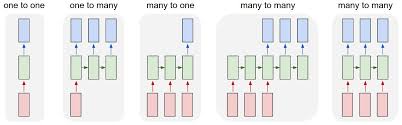
Recurrent Neural Networks (RNNs) have gained significant popularity in the field of artificial intelligence and machine learning due to their ability to effectively model sequential data. There are several types of RNN architectures that have been developed to address different challenges and improve performance in various applications.
Vanilla RNN:
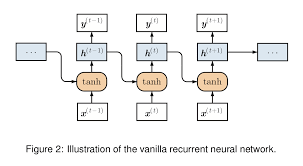
The Vanilla RNN is the simplest form of a recurrent neural network, where each neuron in the network is connected to itself through time. While it can capture short-term dependencies in sequential data, it often struggles with long-term dependencies due to the vanishing gradient problem.
Long Short-Term Memory (LSTM):
LSTM networks were introduced to address the vanishing gradient problem in Vanilla RNNs. They incorporate memory cells and gating mechanisms that allow them to retain information over long sequences. This makes LSTMs particularly effective for tasks that require modeling long-range dependencies, such as language translation and speech recognition.
Gated Recurrent Unit (GRU):
GRU is a simplified version of LSTM that combines the forget and input gates into a single update gate. This reduces the computational complexity of the model while maintaining similar performance in capturing long-term dependencies. GRUs are commonly used for tasks where efficiency is a priority, such as real-time applications and mobile devices.
Bidirectional RNN:
Bidirectional RNNs process input sequences in both forward and backward directions, allowing them to capture contextual information from past and future time steps simultaneously. This architecture is beneficial for tasks that require a comprehensive understanding of the entire input sequence, such as sentiment analysis and speech recognition.
Deep RNN:
Deep RNNs consist of multiple layers of recurrent units stacked on top of each other, enabling them to learn hierarchical representations of sequential data. Deep RNNs can capture complex patterns and relationships within sequences, making them suitable for tasks that involve intricate dependencies and structures.
In conclusion, the diverse types of recurrent neural networks offer unique strengths and capabilities for modeling sequential data in different contexts. By understanding the characteristics and applications of each architecture, researchers and practitioners can choose the most suitable RNN variant for their specific needs and achieve optimal performance in various machine learning tasks.
Exploring 7 Types of Recurrent Neural Networks: From Vanilla RNNs to Attention Mechanisms
- Vanilla RNNs have a short-term memory due to vanishing/exploding gradient problem.
- LSTM networks are capable of learning long-term dependencies with their memory cell structure.
- GRU networks are simpler than LSTM and have fewer parameters, making them faster to train.
- Bidirectional RNNs process sequences in both forward and backward directions to capture context from past and future.
- Deep RNNs stack multiple layers of recurrent units for increased model complexity and representational power.
- Attention mechanisms help focus on specific parts of the input sequence, improving performance in tasks like machine translation.
- Echo State Networks (ESNs) are a type of reservoir computing RNNs known for their fixed random structure.
Vanilla RNNs have a short-term memory due to vanishing/exploding gradient problem.
Vanilla RNNs are known for their short-term memory capabilities, which stem from the vanishing or exploding gradient problem they often encounter. This limitation arises when training the network on long sequences, causing the gradients to either diminish to insignificance or grow uncontrollably. As a result, Vanilla RNNs struggle to retain information over extended periods, making them less effective at capturing long-term dependencies in sequential data.
LSTM networks are capable of learning long-term dependencies with their memory cell structure.
LSTM networks stand out for their ability to effectively learn long-term dependencies in sequential data, thanks to their unique memory cell structure. By incorporating memory cells and gating mechanisms, LSTM networks can retain and update information over extended sequences, enabling them to capture complex relationships and patterns that span across time steps. This capability makes LSTMs particularly well-suited for tasks that require modeling intricate dependencies, such as natural language processing, speech recognition, and time series analysis.
GRU networks are simpler than LSTM and have fewer parameters, making them faster to train.
GRU networks are a more streamlined alternative to LSTM networks, offering simplicity and efficiency in training due to their reduced number of parameters. With fewer computational requirements, GRUs can be trained faster than LSTMs while still maintaining comparable performance in capturing long-term dependencies in sequential data. This makes GRU networks a practical choice for applications where speed and resource efficiency are crucial factors in model development and deployment.
Bidirectional RNNs process sequences in both forward and backward directions to capture context from past and future.
Bidirectional Recurrent Neural Networks (RNNs) are a powerful architecture that enhances the understanding of sequential data by processing input sequences in both forward and backward directions. By incorporating information from both past and future time steps, Bidirectional RNNs are able to capture a more comprehensive context that enables them to make more informed predictions and decisions. This dual-directional approach is particularly beneficial for tasks that require a deep understanding of the entire input sequence, allowing the model to leverage contextual information from all parts of the data to improve performance and accuracy.
Deep RNNs stack multiple layers of recurrent units for increased model complexity and representational power.
Deep RNNs stack multiple layers of recurrent units to enhance model complexity and boost representational power. By incorporating multiple layers, Deep RNNs can learn hierarchical features and capture intricate patterns within sequential data. This architecture enables the network to extract high-level abstract representations from the input sequence, allowing for more nuanced and accurate modeling of complex dependencies. Deep RNNs are particularly effective in tasks that require a deep understanding of sequential data structures, making them a valuable tool for advanced machine learning applications.
Attention mechanisms help focus on specific parts of the input sequence, improving performance in tasks like machine translation.
Attention mechanisms play a crucial role in enhancing the capabilities of recurrent neural networks by enabling them to focus on specific parts of the input sequence. This selective attention mechanism helps improve performance in tasks such as machine translation by allowing the model to prioritize relevant information and ignore irrelevant details. By dynamically adjusting the importance of different input elements during processing, attention mechanisms enable more accurate and context-aware translations, leading to significant advancements in the quality and efficiency of language translation systems.
Echo State Networks (ESNs) are a type of reservoir computing RNNs known for their fixed random structure.
Echo State Networks (ESNs) are a type of reservoir computing recurrent neural networks that are distinguished by their fixed random structure. In ESNs, the reservoir layer is initialized with random connections that remain unchanged during training, allowing the network to efficiently capture temporal dynamics and nonlinear patterns in sequential data. This fixed structure simplifies the training process and reduces the risk of overfitting, making ESNs particularly suitable for tasks where preserving temporal information and handling complex time-series data are essential.