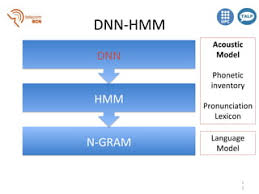
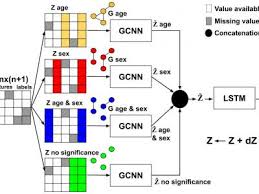
Supervised Sequence Labelling with Recurrent Neural Networks
In the realm of artificial intelligence and machine learning, supervised sequence labelling with recurrent neural networks (RNNs) has emerged as a powerful technique for processing sequential data. This approach has found applications in various fields such as natural language processing, speech recognition, and bioinformatics.
RNNs are a type of neural network architecture designed to handle sequential data by maintaining an internal state or memory. This allows them to capture dependencies and patterns in sequences, making them well-suited for tasks where the order of inputs matters.
When it comes to supervised sequence labelling, RNNs are trained on input-output pairs where the input is a sequence of data (such as words in a sentence or nucleotides in a DNA sequence) and the output is a corresponding label or prediction. The network learns to predict the correct label for each element in the input sequence by processing the data sequentially and updating its internal state at each step.
One of the key advantages of using RNNs for sequence labelling tasks is their ability to handle variable-length inputs. Unlike traditional feedforward neural networks that require fixed-size input vectors, RNNs can process sequences of arbitrary length, making them versatile for tasks like named entity recognition, part-of-speech tagging, and sentiment analysis.
However, training RNNs can be challenging due to issues like vanishing gradients and long-range dependencies. To address these challenges, researchers have developed advanced variants of RNNs such as Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks, which are better equipped to capture long-term dependencies in sequences.
In recent years, supervised sequence labelling with RNNs has seen significant advancements with the introduction of attention mechanisms and transformer architectures. These innovations have further improved the performance of RNN-based models on complex sequential tasks by enabling them to focus on relevant parts of the input sequence while making predictions.
In conclusion, supervised sequence labelling with recurrent neural networks offers a flexible and effective approach for processing sequential data across various domains. With ongoing research and development in this field, we can expect further enhancements in RNN-based models that push the boundaries of what is possible in sequence labelling tasks.
8 Essential Tips for Effective Supervised Sequence Labeling with Recurrent Neural Networks
- Preprocess input data to ensure it is in the appropriate format for RNNs.
- Choose an appropriate RNN architecture such as LSTM or GRU based on the complexity of the task.
- Carefully design the network architecture, including the number of layers and units per layer.
- Use techniques like dropout and batch normalization to prevent overfitting.
- Select a suitable loss function such as categorical cross-entropy for sequence labeling tasks.
- Optimize hyperparameters like learning rate and batch size through experimentation.
- Monitor training progress by visualizing metrics like loss and accuracy to identify potential issues.
- Evaluate model performance using metrics like precision, recall, and F1 score on a separate validation set.
Preprocess input data to ensure it is in the appropriate format for RNNs.
To optimize the performance of supervised sequence labelling with recurrent neural networks, it is crucial to preprocess input data to ensure it is in the suitable format for RNNs. This preprocessing step involves converting raw sequential data into a format that can be effectively fed into the network. Tasks such as tokenization, padding sequences to a fixed length, and encoding categorical variables are essential to prepare the input data for RNNs. By standardizing and organizing the input data appropriately, we enable the RNN model to learn meaningful patterns and dependencies within the sequences, ultimately enhancing its ability to make accurate predictions.
Choose an appropriate RNN architecture such as LSTM or GRU based on the complexity of the task.
When working on supervised sequence labelling tasks with recurrent neural networks, it is crucial to choose the right RNN architecture, such as Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU), based on the complexity of the task at hand. For more intricate tasks that involve capturing long-range dependencies and handling vanishing gradients, LSTM or GRU networks are preferred due to their ability to retain information over longer sequences. By selecting an appropriate RNN architecture tailored to the specific requirements of the task, one can enhance the model’s performance and efficiency in processing sequential data effectively.
Carefully design the network architecture, including the number of layers and units per layer.
When implementing supervised sequence labelling with recurrent neural networks, it is crucial to meticulously design the network architecture, taking into consideration factors such as the number of layers and units per layer. The architecture of the network plays a significant role in determining its capacity to learn complex patterns and dependencies within sequential data. By carefully selecting the appropriate number of layers and units per layer, researchers and practitioners can optimize the performance of the model, ensuring efficient training and accurate predictions. Balancing model complexity with computational efficiency is key in achieving successful outcomes in supervised sequence labelling tasks using recurrent neural networks.
Use techniques like dropout and batch normalization to prevent overfitting.
To enhance the performance of supervised sequence labelling with recurrent neural networks, it is advisable to incorporate techniques such as dropout and batch normalization to prevent overfitting. Dropout involves randomly deactivating a portion of neurons during training, which helps the network generalize better to unseen data by reducing reliance on specific neurons. On the other hand, batch normalization normalizes the activations of each layer in a neural network, making the training process more stable and accelerating convergence. By implementing these techniques, practitioners can improve the robustness and generalization capabilities of RNN models for sequence labelling tasks.
Select a suitable loss function such as categorical cross-entropy for sequence labeling tasks.
When working on supervised sequence labelling tasks with recurrent neural networks, it is crucial to choose an appropriate loss function to train the model effectively. One commonly used loss function for sequence labelling tasks is categorical cross-entropy, which is well-suited for scenarios where the output labels are mutually exclusive. By selecting categorical cross-entropy as the loss function, the model can learn to minimize the difference between predicted probabilities and true labels, thereby improving its ability to make accurate predictions for each element in the input sequence. This choice helps optimize the training process and enhance the performance of RNNs in sequence labelling applications.
Optimize hyperparameters like learning rate and batch size through experimentation.
To optimize the performance of supervised sequence labelling with recurrent neural networks, it is crucial to experiment with and fine-tune hyperparameters such as learning rate and batch size. By systematically varying these parameters and observing their impact on the model’s training process and accuracy, researchers and practitioners can identify the optimal settings that lead to faster convergence and improved performance. Adjusting the learning rate affects how quickly the model updates its weights during training, while varying the batch size influences the stability and efficiency of the optimization process. Through careful experimentation and analysis, practitioners can uncover the hyperparameter configurations that maximize the effectiveness of RNNs in sequence labelling tasks.
Monitor training progress by visualizing metrics like loss and accuracy to identify potential issues.
Monitoring the training progress of supervised sequence labelling with recurrent neural networks is crucial for optimizing model performance. By visualizing metrics such as loss and accuracy during training, practitioners can gain valuable insights into the behavior of the model and identify potential issues early on. Tracking these metrics allows for timely adjustments to training parameters or architecture, leading to more efficient convergence and improved overall performance of the RNN model. Effective monitoring ensures that the model is learning effectively and can help in diagnosing problems such as overfitting or underfitting, ultimately leading to better results in sequence labelling tasks.
Evaluate model performance using metrics like precision, recall, and F1 score on a separate validation set.
To ensure the effectiveness and reliability of a supervised sequence labelling model built with recurrent neural networks, it is crucial to evaluate its performance using metrics such as precision, recall, and F1 score on a separate validation set. Precision measures the accuracy of positive predictions made by the model, while recall assesses the model’s ability to correctly identify all relevant instances in the data. The F1 score provides a balanced measure of precision and recall, offering a comprehensive evaluation of the model’s performance. By conducting this evaluation on a validation set separate from the training data, researchers can gain insights into how well the model generalizes to unseen data and make informed decisions about its suitability for real-world applications.