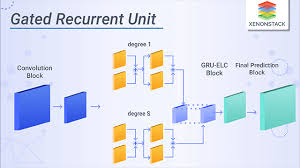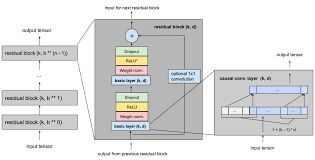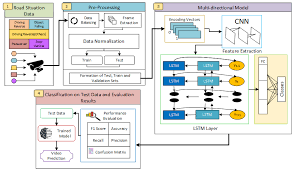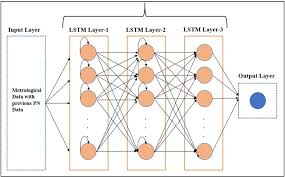
Long Short-Term Memory Recurrent Neural Network: Unleashing the Power of Sequential Data Processing
In the realm of artificial intelligence and deep learning, the Long Short-Term Memory (LSTM) recurrent neural network stands out as a powerful tool for processing sequential data. Originally proposed by Sepp Hochreiter and Jürgen Schmidhuber in 1997, LSTM has revolutionized various applications such as natural language processing, speech recognition, time series analysis, and more.
Unlike traditional feedforward neural networks, LSTM networks are designed to effectively capture long-term dependencies in sequential data. This is achieved through a sophisticated architecture that includes memory cells, input gates, forget gates, and output gates. The memory cells enable the network to retain information over long periods of time, while the gates regulate the flow of information into and out of the cells.
One of the key strengths of LSTM networks is their ability to handle vanishing and exploding gradient problems that often plague traditional recurrent neural networks. By carefully controlling the flow of information through the gates, LSTMs can effectively learn from and remember relevant patterns in sequential data without suffering from gradient instability.
Furthermore, LSTM networks are highly adaptable and can be easily extended to suit different tasks and datasets. Researchers and practitioners have developed various enhancements to the basic LSTM architecture, such as peephole connections, attention mechanisms, and stacked LSTM layers, to further improve performance on specific tasks.
In practical applications, LSTM recurrent neural networks have demonstrated remarkable success in a wide range of domains. In natural language processing tasks like machine translation and sentiment analysis, LSTMs excel at capturing contextual information and generating coherent outputs. In time series analysis tasks such as financial forecasting and speech recognition, LSTMs can effectively model temporal dependencies and make accurate predictions.
As research in deep learning continues to advance, LSTM networks remain a fundamental building block for many state-of-the-art models. Their ability to process sequential data with long-range dependencies makes them indispensable for tackling complex real-world problems that involve analyzing sequences of information.
In conclusion, the Long Short-Term Memory recurrent neural network represents a significant milestone in the field of deep learning. Its unique architecture and robust performance have established it as a cornerstone technology for handling sequential data processing tasks across diverse domains.
7 Essential Tips for Optimizing Long Short-Term Memory (LSTM) Networks
- Preprocess your data to ensure it is in the appropriate format for LSTM input.
- Normalize your input data to improve training stability and convergence.
- Experiment with different network architectures, layer sizes, and activation functions to optimize performance.
- Consider using techniques like dropout and batch normalization to prevent overfitting.
- Monitor the training process closely by tracking metrics such as loss and accuracy.
- Use early stopping to prevent overfitting and save computational resources.
- Fine-tune hyperparameters such as learning rate and batch size for better results.
Preprocess your data to ensure it is in the appropriate format for LSTM input.
To maximize the effectiveness of your Long Short-Term Memory (LSTM) recurrent neural network, it is crucial to preprocess your data and ensure that it is in the appropriate format for LSTM input. This preprocessing step involves organizing and structuring your data sequences in a way that allows the LSTM network to effectively learn from the temporal dependencies within the data. By carefully formatting your input data, you can help the LSTM model capture meaningful patterns and relationships, ultimately enhancing its ability to make accurate predictions or generate valuable insights.
Normalize your input data to improve training stability and convergence.
To enhance training stability and convergence when working with Long Short-Term Memory (LSTM) recurrent neural networks, it is advisable to normalize your input data. Normalizing the input data helps to scale the values within a consistent range, which can prevent issues such as vanishing or exploding gradients during training. By ensuring that the input data is standardized, LSTM networks can more effectively learn from the sequential patterns in the data and converge to optimal solutions efficiently. This simple yet crucial tip can significantly improve the performance and robustness of LSTM models in various applications.
Experiment with different network architectures, layer sizes, and activation functions to optimize performance.
To enhance the performance of Long Short-Term Memory recurrent neural networks, it is crucial to experiment with various network architectures, layer sizes, and activation functions. By exploring different configurations, researchers and practitioners can fine-tune the model to achieve optimal results for specific tasks. Adjusting the architecture, such as adding more layers or changing the connectivity between neurons, can help capture complex patterns in sequential data. Varying the sizes of layers can impact the network’s capacity to learn and generalize effectively. Additionally, trying out different activation functions like sigmoid, tanh, or ReLU can influence how information flows through the network and how well it adapts to different types of data. Through systematic experimentation and optimization of these key components, the performance of LSTM networks can be significantly improved.
Consider using techniques like dropout and batch normalization to prevent overfitting.
To enhance the performance and generalization of Long Short-Term Memory (LSTM) recurrent neural networks, it is advisable to incorporate techniques like dropout and batch normalization to mitigate the risk of overfitting. Dropout helps prevent individual neurons from becoming overly reliant on specific features in the training data, promoting more robust learning and reducing overfitting. Batch normalization, on the other hand, normalizes the activations of each layer in the network, leading to faster convergence during training and improved generalization. By implementing these techniques judiciously, practitioners can optimize the effectiveness of LSTM networks in handling sequential data tasks while minimizing the risk of overfitting.
Monitor the training process closely by tracking metrics such as loss and accuracy.
To maximize the effectiveness of a Long Short-Term Memory recurrent neural network, it is crucial to monitor the training process closely by tracking key metrics such as loss and accuracy. By continuously evaluating these metrics throughout the training phase, developers can gain valuable insights into the network’s performance and make informed decisions to optimize its learning process. Monitoring loss helps in assessing how well the model is fitting the training data, while tracking accuracy provides a measure of how accurately the network is making predictions. This close monitoring allows for timely adjustments and fine-tuning of the LSTM network, leading to improved performance and better results in handling sequential data tasks.
Use early stopping to prevent overfitting and save computational resources.
When working with Long Short-Term Memory (LSTM) recurrent neural networks, a valuable tip is to utilize early stopping as a strategy to prevent overfitting and conserve computational resources. By monitoring the performance of the model on a validation dataset during training, early stopping allows you to halt the training process when the model starts to overfit the training data. This helps in achieving a balance between model complexity and generalization, ultimately improving the model’s ability to make accurate predictions on unseen data. Not only does early stopping enhance the model’s performance, but it also saves time and computational resources by avoiding unnecessary iterations that do not contribute to improving the model’s predictive power.
Fine-tune hyperparameters such as learning rate and batch size for better results.
To optimize the performance of a Long Short-Term Memory recurrent neural network, it is crucial to fine-tune hyperparameters such as the learning rate and batch size. Adjusting these parameters can significantly impact the training process and overall results of the model. By carefully selecting an appropriate learning rate, the network can converge faster and more effectively learn complex patterns in sequential data. Similarly, optimizing the batch size can enhance the efficiency of training by balancing computational resources and memory usage. Fine-tuning these hyperparameters is essential for achieving better accuracy and performance in LSTM networks across various applications.