The Power of Gated Recurrent Neural Networks
Recurrent Neural Networks (RNNs) have revolutionized the field of natural language processing and sequential data analysis. However, traditional RNNs suffer from the vanishing gradient problem, which limits their ability to capture long-range dependencies in sequential data. This is where Gated Recurrent Neural Networks (GRNNs) come into play.
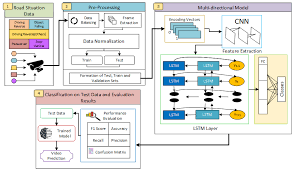
GRNNs are a type of neural network architecture that includes gating mechanisms to control the flow of information within the network. The most popular variant of GRNN is the Long Short-Term Memory (LSTM) network, which consists of three gates: input gate, forget gate, and output gate.
The input gate regulates the flow of new information into the memory cell, while the forget gate controls what information should be discarded from the cell. The output gate determines what information should be passed on to the next time step or output layer. This gating mechanism enables LSTM networks to effectively learn long-term dependencies in sequential data.
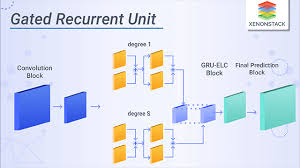
Another variant of GRNN is the Gated Recurrent Unit (GRU), which simplifies the LSTM architecture by combining the forget and input gates into a single update gate. This results in a more streamlined architecture with comparable performance to LSTM networks.
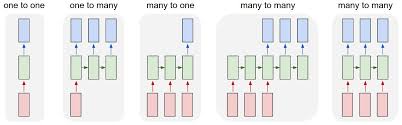
GRNNs have been widely used in various applications, including speech recognition, machine translation, sentiment analysis, and time series prediction. Their ability to capture long-range dependencies and handle sequential data makes them well-suited for tasks that involve analyzing and generating sequences of data.
In conclusion, Gated Recurrent Neural Networks represent a significant advancement in neural network architectures for processing sequential data. With their gating mechanisms and ability to learn long-term dependencies, GRNNs have become an indispensable tool for researchers and practitioners working in fields that require effective modeling of sequential data.
Understanding Gated Recurrent Neural Networks: Key Questions and Answers
- What is meant by gated recurrent unit?
- What is a gated recurrent neural network?
- What is gated recurrent neural network?
- Is GRU better than LSTM?
- What is the problem with GRU?
- Why is GRU used?
- What is GRU and LSTM?
- Why GRU is used in deep learning?
What is meant by gated recurrent unit?
A Gated Recurrent Unit (GRU) is a variant of the Gated Recurrent Neural Network (GRNN) architecture that simplifies the structure of traditional Long Short-Term Memory (LSTM) networks. In a GRU, the forget and input gates in an LSTM are merged into a single update gate, making the network more streamlined and efficient. This design allows GRUs to effectively capture long-term dependencies in sequential data while requiring fewer parameters compared to LSTMs. GRUs have gained popularity in various natural language processing tasks and time series analysis due to their simplicity and competitive performance.
What is a gated recurrent neural network?
A gated recurrent neural network, often abbreviated as GRNN, is a specialized type of neural network architecture designed to address the limitations of traditional recurrent neural networks (RNNs) in capturing long-range dependencies in sequential data. The key feature of a GRNN is the incorporation of gating mechanisms, such as those found in Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks, which regulate the flow of information within the network. These gates enable the model to selectively retain or discard information at each time step, allowing it to effectively learn and remember patterns over long sequences. By leveraging these gating mechanisms, a gated recurrent neural network can better handle tasks involving sequential data analysis and generation with improved performance and efficiency.
What is gated recurrent neural network?
A Gated Recurrent Neural Network (GRNN) is a type of neural network architecture that incorporates gating mechanisms to regulate the flow of information within the network. One of the most popular variants of GRNN is the Long Short-Term Memory (LSTM) network, which includes gates to control the input, output, and forgetting of information in memory cells. This gating mechanism allows GRNNs to effectively capture long-range dependencies in sequential data, making them ideal for tasks such as natural language processing, speech recognition, and time series analysis.
Is GRU better than LSTM?
The question of whether Gated Recurrent Units (GRU) are better than Long Short-Term Memory (LSTM) networks is a common one in the field of deep learning. Both GRU and LSTM are variants of Gated Recurrent Neural Networks that address the vanishing gradient problem and enable the modeling of long-range dependencies in sequential data. While LSTM networks have been traditionally favored for their ability to store and retrieve information over longer time scales due to their more complex architecture with separate input, forget, and output gates, GRU networks offer a simpler design by combining the forget and input gates into a single update gate. The choice between GRU and LSTM often depends on the specific task at hand, as both architectures have shown comparable performance in various applications. Researchers continue to explore the strengths and weaknesses of each architecture to determine which is better suited for different types of sequential data analysis tasks.
What is the problem with GRU?
One common question regarding Gated Recurrent Units (GRUs) is about the potential issues or limitations associated with this type of neural network architecture. While GRUs offer a more simplified design compared to Long Short-Term Memory (LSTM) networks by combining the forget and input gates, some researchers have found that GRUs may struggle with capturing long-term dependencies in sequential data as effectively as LSTMs. This limitation can impact the network’s ability to learn complex patterns and relationships in data sequences, which may lead to suboptimal performance in tasks that require modeling long-range dependencies. Despite this drawback, GRUs remain a popular choice for many applications due to their efficiency and ease of training.
Why is GRU used?
GRUs, or Gated Recurrent Units, are commonly used in neural network architectures for several reasons. One key advantage of GRUs is their simplified architecture compared to LSTM networks, as they combine the forget and input gates into a single update gate. This streamlined design makes GRUs easier to train and more computationally efficient while still allowing them to capture long-term dependencies in sequential data. Additionally, GRUs have been shown to perform comparably well to LSTM networks in various tasks, making them a popular choice for researchers and practitioners in the field of natural language processing, speech recognition, and other applications that involve processing sequential data efficiently and effectively.
What is GRU and LSTM?
Gated Recurrent Unit (GRU) and Long Short-Term Memory (LSTM) are two popular variants of Gated Recurrent Neural Networks (GRNNs) that address the limitations of traditional Recurrent Neural Networks (RNNs). Both GRU and LSTM incorporate gating mechanisms to control the flow of information within the network, allowing them to effectively capture long-term dependencies in sequential data. The main difference between GRU and LSTM lies in their architecture complexity, with GRU being a more simplified version that combines the forget and input gates into a single update gate. On the other hand, LSTM consists of three gates: input gate, forget gate, and output gate. Despite their architectural differences, both GRU and LSTM have proven to be powerful tools in various applications such as natural language processing, speech recognition, and time series analysis.
Why GRU is used in deep learning?
The Gated Recurrent Unit (GRU) is commonly used in deep learning due to its simplified architecture and comparable performance to the more complex Long Short-Term Memory (LSTM) network. The GRU combines the forget and input gates into a single update gate, making it more efficient in terms of computation and memory usage. This streamlined design allows for faster training times and better scalability, making GRUs a popular choice for tasks involving sequential data processing in deep learning models. Additionally, the GRU’s ability to capture long-range dependencies while maintaining a simpler structure makes it an attractive option for researchers and practitioners seeking a balance between performance and complexity in their neural network architectures.