The Power of Recurrent Neural Networks in PyTorch
Recurrent Neural Networks (RNNs) have revolutionized the field of natural language processing and sequential data analysis. In PyTorch, a popular deep learning framework, RNNs are implemented with ease and efficiency, making them a powerful tool for various applications.
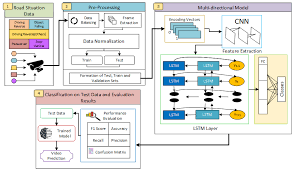
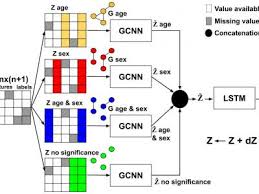
One of the key advantages of RNNs is their ability to process sequential data while maintaining memory of previous inputs. This makes them ideal for tasks such as language modeling, speech recognition, machine translation, and more. In PyTorch, RNNs can be easily constructed using the built-in modules provided by the framework.
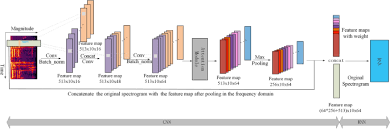
PyTorch offers a variety of RNN modules, including basic RNNs, Long Short-Term Memory (LSTM) networks, and Gated Recurrent Units (GRUs). These modules can be customized and combined to create complex neural network architectures tailored to specific tasks.
Training RNNs in PyTorch is straightforward thanks to its automatic differentiation capabilities. This allows developers to focus on model design and hyperparameter tuning without worrying about manual gradient computation. With PyTorch’s dynamic computation graph feature, RNN models can be easily modified and debugged during development.
Furthermore, PyTorch provides extensive documentation and a vibrant community that offer support and resources for implementing RNNs effectively. Developers can leverage pre-trained models, tutorials, and code snippets to accelerate their projects and explore the full potential of recurrent neural networks.
In conclusion, the combination of recurrent neural networks and PyTorch opens up exciting possibilities for deep learning enthusiasts and researchers alike. Whether you are working on text generation, sentiment analysis, or time series prediction, RNNs in PyTorch provide a flexible and powerful solution to tackle complex sequential data tasks with ease.
Top 6 Frequently Asked Questions About Implementing Recurrent Neural Networks in PyTorch
- What is a recurrent neural network (RNN) in the context of deep learning?
- How does a recurrent neural network differ from other types of neural networks?
- What are the advantages of using PyTorch for implementing recurrent neural networks?
- Can you explain the concept of backpropagation through time (BPTT) in the context of RNNs in PyTorch?
- Are there any common challenges or issues when training recurrent neural networks in PyTorch?
- Is it possible to visualize and interpret the internal workings of a recurrent neural network implemented in PyTorch?
What is a recurrent neural network (RNN) in the context of deep learning?
In the context of deep learning, a Recurrent Neural Network (RNN) is a type of neural network designed to effectively handle sequential data by retaining memory of past inputs. Unlike traditional feedforward neural networks, RNNs have connections that form loops, allowing information to persist and be passed from one time step to the next. This unique architecture makes RNNs well-suited for tasks involving sequences, such as natural language processing, speech recognition, and time series analysis. In PyTorch, a popular deep learning framework, RNNs can be easily implemented and customized to create sophisticated models that excel at capturing patterns and dependencies within sequential data.
How does a recurrent neural network differ from other types of neural networks?
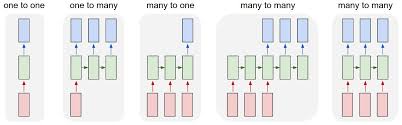
A recurrent neural network (RNN) differs from other types of neural networks in its ability to process sequential data by maintaining memory of past inputs. Unlike feedforward neural networks that process data in a single pass from input to output, RNNs have connections that form loops, allowing them to exhibit temporal dynamics and capture dependencies across time steps. This makes RNNs well-suited for tasks involving sequences, such as natural language processing, time series analysis, and speech recognition. The recurrent nature of RNNs enables them to handle variable-length inputs and generate context-aware predictions based on the entire input sequence, making them a powerful tool for modeling sequential data in a wide range of applications.
What are the advantages of using PyTorch for implementing recurrent neural networks?
When it comes to implementing recurrent neural networks (RNNs), PyTorch offers a range of advantages that make it a preferred choice among developers and researchers. One key advantage is PyTorch’s flexibility in designing and customizing RNN architectures, thanks to its modular design and easy-to-use API. Additionally, PyTorch’s dynamic computation graph feature simplifies the process of building and training RNN models, allowing for quick experimentation and iteration. The seamless integration of automatic differentiation in PyTorch also streamlines the optimization process, enabling efficient training of RNNs without the need for manual gradient computation. Overall, PyTorch’s robust support for RNNs, coupled with its rich documentation and active community, makes it an ideal framework for implementing and exploring the capabilities of recurrent neural networks effectively.
Can you explain the concept of backpropagation through time (BPTT) in the context of RNNs in PyTorch?
In the context of Recurrent Neural Networks (RNNs) in PyTorch, backpropagation through time (BPTT) is a fundamental concept that plays a crucial role in training these models. BPTT is a variation of the backpropagation algorithm specifically designed for sequential data processing. In RNNs, where connections between neurons form a directed cycle to retain memory of past inputs, BPTT unfolds the network across time steps to calculate gradients and update weights. This process involves propagating errors backwards through each time step of the unfolded network to adjust parameters and optimize the model’s performance. By effectively handling temporal dependencies and capturing long-range dependencies, BPTT enables RNNs in PyTorch to learn complex patterns and sequences efficiently during training.
Are there any common challenges or issues when training recurrent neural networks in PyTorch?
When training recurrent neural networks in PyTorch, there are several common challenges and issues that developers may encounter. One common challenge is the issue of vanishing or exploding gradients, which can affect the stability and convergence of the training process. This problem often arises in deep RNN architectures or when processing long sequences. Another challenge is the management of sequence lengths and batch sizes, as variable-length sequences require careful handling to ensure efficient training and memory usage. Additionally, overfitting can be a concern when working with RNNs, especially if the model is complex or the dataset is limited. Regularization techniques and hyperparameter tuning are often needed to address this issue effectively. By being aware of these challenges and implementing best practices, developers can optimize their RNN models in PyTorch for improved performance and robustness.
Is it possible to visualize and interpret the internal workings of a recurrent neural network implemented in PyTorch?
One frequently asked question regarding recurrent neural networks implemented in PyTorch is whether it is possible to visualize and interpret the internal workings of the model. While RNNs are known for their complex nature and black-box characteristics, there are techniques available to gain insights into how these networks make predictions. By visualizing activations, gradients, and attention mechanisms within the RNN layers, researchers and developers can better understand how information flows through the network and identify patterns learned during training. Additionally, tools such as tensorboardX and PyTorch’s built-in visualization capabilities can aid in interpreting the behavior of RNN models, offering valuable insights for model debugging, optimization, and performance enhancement.