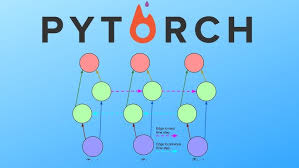
Exploring PyTorch Recurrent Neural Networks
Recurrent Neural Networks (RNNs) are a powerful class of neural networks that are designed to handle sequential data. In the world of deep learning, PyTorch has emerged as a popular framework for building and training neural networks, including RNNs.
PyTorch provides a user-friendly interface for implementing RNNs, making it easier for developers and researchers to work with sequential data. With PyTorch’s flexibility and efficiency, building complex RNN architectures becomes more accessible.
One of the key features of PyTorch’s RNN module is its ability to handle variable-length sequences. This flexibility allows RNNs to process data of different lengths, making them suitable for tasks such as natural language processing, time series analysis, and speech recognition.
By leveraging PyTorch’s automatic differentiation capabilities, developers can easily train RNN models and optimize them for various tasks. The dynamic computation graph in PyTorch simplifies the process of defining and training RNN architectures, enabling faster experimentation and prototyping.
In addition to traditional RNN architectures, PyTorch also offers variants like Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU), which are known for their ability to capture long-range dependencies in sequential data. These advanced RNN variants further enhance the modeling capabilities of PyTorch.
Overall, PyTorch’s support for recurrent neural networks opens up new possibilities in deep learning research and application development. Whether you are working on text analysis, time series forecasting, or any other sequential data task, PyTorch’s RNN capabilities provide a solid foundation for building robust and efficient neural network models.
9 Essential Tips for Mastering Recurrent Neural Networks with PyTorch
- 1. Understand the basics of recurrent neural networks (RNNs) before diving into PyTorch implementation.
- 2. Use nn.RNN or nn.LSTM modules in PyTorch to create RNN layers easily.
- 3. Pay attention to input shapes when working with RNNs in PyTorch.
- 4. Remember to initialize hidden states when using RNNs for sequential data processing.
- 5. Utilize GPU acceleration in PyTorch for faster training of RNN models.
- 6. Experiment with different hyperparameters like learning rate and batch size to optimize RNN performance.
- 7. Implement custom RNN architectures by subclassing nn.Module in PyTorch.
- 8. Visualize model outputs and gradients to debug RNN training processes effectively.
- 9. Stay updated with the latest advancements and best practices in PyTorch for working with recurrent neural networks.
1. Understand the basics of recurrent neural networks (RNNs) before diving into PyTorch implementation.
Before delving into implementing recurrent neural networks (RNNs) in PyTorch, it is crucial to have a solid understanding of the basics of RNNs. RNNs are a specialized class of neural networks designed to handle sequential data by capturing dependencies over time. By grasping the fundamental concepts behind RNNs, such as how they process sequential information and address challenges like vanishing gradients, developers can approach PyTorch implementation with a clearer perspective. This foundational knowledge not only enhances comprehension of RNN functionalities but also aids in effectively leveraging PyTorch’s features to build robust and efficient models for various sequential data tasks.
2. Use nn.RNN or nn.LSTM modules in PyTorch to create RNN layers easily.
To simplify the creation of RNN layers in PyTorch, it is recommended to utilize the nn.RNN or nn.LSTM modules provided by the framework. These modules offer a convenient way to implement recurrent neural network architectures without the need for manual coding of intricate details. By leveraging nn.RNN or nn.LSTM, developers can easily define and incorporate RNN layers into their models, streamlining the process of building sophisticated neural networks for tasks involving sequential data processing.
3. Pay attention to input shapes when working with RNNs in PyTorch.
When working with recurrent neural networks in PyTorch, it is crucial to pay close attention to input shapes. The input shape plays a significant role in how data is processed and passed through the network layers. Ensuring that the input shape is correctly defined and aligned with the requirements of the RNN architecture is essential for the model to learn effectively from sequential data. By maintaining proper input shapes, developers can optimize the performance and accuracy of their PyTorch RNN models, leading to more reliable results in tasks such as natural language processing, time series analysis, and speech recognition.
4. Remember to initialize hidden states when using RNNs for sequential data processing.
When utilizing PyTorch recurrent neural networks for processing sequential data, it is crucial to remember to initialize hidden states. Initializing hidden states ensures that the network starts with meaningful information and avoids potential issues such as vanishing gradients or exploding activations. By setting the initial hidden states appropriately, the RNN model can effectively capture dependencies across time steps and generate accurate predictions for tasks such as natural language processing, time series analysis, and more.
5. Utilize GPU acceleration in PyTorch for faster training of RNN models.
To optimize the training process of PyTorch recurrent neural network models, it is recommended to leverage GPU acceleration. By utilizing the computational power of GPUs, PyTorch can significantly speed up the training of RNN models, allowing for faster convergence and more efficient utilization of resources. This enhancement not only reduces training time but also enables researchers and developers to experiment with larger datasets and more complex RNN architectures, ultimately leading to improved model performance and scalability.
6. Experiment with different hyperparameters like learning rate and batch size to optimize RNN performance.
To optimize the performance of a PyTorch recurrent neural network, it is recommended to experiment with different hyperparameters such as learning rate and batch size. Adjusting the learning rate can impact the speed and quality of model training, while varying the batch size can influence the convergence and generalization of the RNN. By systematically tuning these hyperparameters and observing their effects on the RNN performance metrics, developers can fine-tune their models for better accuracy and efficiency in handling sequential data tasks.
7. Implement custom RNN architectures by subclassing nn.Module in PyTorch.
To implement custom RNN architectures in PyTorch, developers can leverage the flexibility of the framework by subclassing the nn.Module class. By creating a custom RNN module that inherits from nn.Module, users have full control over the architecture and behavior of their neural network. This approach allows for the implementation of tailored RNN structures, enabling researchers and developers to design models that suit specific requirements and tasks. With PyTorch’s modular design and customizable features, creating unique RNN architectures becomes a straightforward process, empowering users to explore innovative solutions in deep learning research and application development.
8. Visualize model outputs and gradients to debug RNN training processes effectively.
To enhance the effectiveness of training processes in PyTorch recurrent neural networks, it is advisable to utilize the tip of visualizing model outputs and gradients. By visualizing the outputs generated by the model during training, developers can gain insights into how the RNN is processing sequential data and identify any patterns or anomalies. Additionally, monitoring gradients can help in understanding how parameters are being updated during backpropagation, enabling better optimization and debugging of the RNN model. This approach not only aids in improving the performance of the RNN but also enhances the overall training process by providing valuable feedback for fine-tuning and troubleshooting.
9. Stay updated with the latest advancements and best practices in PyTorch for working with recurrent neural networks.
To maximize the effectiveness of your PyTorch recurrent neural network models, it is crucial to stay informed about the latest advancements and best practices in utilizing PyTorch for RNNs. By keeping up-to-date with new features, techniques, and optimizations within the framework, you can ensure that your RNN models are leveraging the most cutting-edge capabilities available. Regularly exploring new developments in PyTorch for working with recurrent neural networks will not only enhance the performance of your models but also keep you at the forefront of innovation in deep learning research and application.