Neural Network for Regression in Python
Neural networks have gained immense popularity in the field of machine learning due to their ability to learn complex patterns and relationships in data. In this article, we will explore how neural networks can be used for regression tasks in Python.
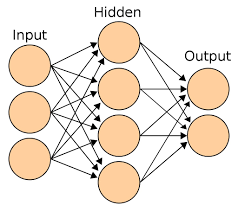
Regression is a type of supervised learning where the goal is to predict a continuous output variable based on one or more input variables. Neural networks, with their multiple layers of interconnected neurons, are well-suited for regression tasks as they can capture nonlinear relationships in the data.
Python provides several libraries that make it easy to implement neural networks for regression, with one of the most popular being TensorFlow. TensorFlow is an open-source machine learning library developed by Google that offers a high-level API for building and training neural networks.
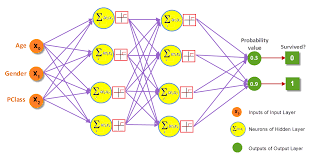
To create a neural network for regression in Python using TensorFlow, you first need to define the architecture of the network, including the number of layers, the number of neurons in each layer, and the activation functions. You then compile the model with an appropriate loss function and optimizer before training it on your data.
Once trained, you can use the neural network to make predictions on new data points. The model will output a continuous value that represents the predicted output variable based on the input variables.
Neural networks have proven to be powerful tools for regression tasks, especially when dealing with complex and high-dimensional data. By leveraging Python libraries such as TensorFlow, you can easily build and train neural networks to make accurate predictions on your regression problems.
In conclusion, neural networks offer a flexible and effective approach to regression tasks in Python. With their ability to learn from data and capture intricate patterns, they are valuable tools for tackling a wide range of real-world prediction problems.
8 Essential Tips for Building Effective Neural Networks for Regression in Python
- 1. Preprocess your data by normalizing or standardizing the features.
- 2. Choose an appropriate neural network architecture with hidden layers and activation functions.
- 3. Use mean squared error (MSE) or mean absolute error (MAE) as loss functions for regression tasks.
- 4. Split your dataset into training and testing sets to evaluate the model’s performance.
- 5. Regularize your neural network using techniques like L1 or L2 regularization to prevent overfitting.
- 6. Monitor the training process by visualizing metrics such as loss and validation accuracy.
- 7. Tune hyperparameters like learning rate, batch size, and number of epochs for optimal performance.
- 8. Consider using techniques like early stopping to prevent overfitting and save computational resources.
1. Preprocess your data by normalizing or standardizing the features.
To improve the performance of your neural network for regression tasks in Python, it is essential to preprocess your data by normalizing or standardizing the features. Normalizing or standardizing the features helps in bringing all input variables to a similar scale, which can prevent certain features from dominating the learning process. This preprocessing step can also aid in faster convergence during training and improve the overall stability and efficiency of your neural network model. By ensuring that your data is properly scaled, you can enhance the accuracy and effectiveness of your regression predictions using Python.
2. Choose an appropriate neural network architecture with hidden layers and activation functions.
When working on a neural network for regression in Python, it is crucial to carefully choose an appropriate architecture that includes hidden layers and activation functions. The number of hidden layers and the types of activation functions used can significantly impact the performance of the neural network in capturing complex patterns and relationships within the data. By selecting the right architecture, you can enhance the model’s ability to learn and make accurate predictions, ultimately improving the overall effectiveness of your regression task.
3. Use mean squared error (MSE) or mean absolute error (MAE) as loss functions for regression tasks.
When working with neural networks for regression tasks in Python, it is advisable to utilize mean squared error (MSE) or mean absolute error (MAE) as the loss functions. These metrics are commonly used in regression problems to measure the difference between predicted values and actual target values. By optimizing the neural network based on minimizing MSE or MAE during training, you can effectively guide the model to make more accurate predictions and improve its performance on regression tasks.
4. Split your dataset into training and testing sets to evaluate the model’s performance.
To ensure the accuracy and reliability of your neural network model for regression in Python, it is crucial to split your dataset into training and testing sets. By doing so, you can evaluate the performance of the model on unseen data and assess its ability to generalize well beyond the training data. This process helps in detecting overfitting or underfitting issues and allows you to fine-tune the model parameters for optimal results. Splitting the dataset into training and testing sets is a fundamental step in building robust and effective neural network models for regression tasks in Python.
5. Regularize your neural network using techniques like L1 or L2 regularization to prevent overfitting.
Regularizing your neural network using techniques like L1 or L2 regularization is crucial when working on regression tasks in Python. Overfitting, where the model performs well on training data but poorly on unseen data, can be a common issue in neural networks. By incorporating regularization methods such as L1 (Lasso) or L2 (Ridge) regularization, you can prevent the model from becoming too complex and overfitting to the training data. These techniques help to penalize large weights in the network, promoting simpler and more generalizable models that perform better on new data.
6. Monitor the training process by visualizing metrics such as loss and validation accuracy.
To optimize the performance of a neural network for regression in Python, it is crucial to monitor the training process closely. One effective way to do this is by visualizing key metrics such as loss and validation accuracy throughout the training phase. By tracking these metrics, you can gain valuable insights into how well the model is learning from the data and making predictions. Monitoring the loss function helps ensure that the model is minimizing errors, while observing validation accuracy provides an indication of how well the model generalizes to new, unseen data. Visualizing these metrics allows for timely adjustments and improvements to be made, ultimately leading to a more accurate and reliable neural network for regression tasks.
7. Tune hyperparameters like learning rate, batch size, and number of epochs for optimal performance.
When working with neural networks for regression in Python, it is crucial to tune hyperparameters such as the learning rate, batch size, and number of epochs to achieve optimal performance. The learning rate determines how quickly the model adapts to the data during training, while the batch size affects how many samples are processed before updating the model’s parameters. Additionally, adjusting the number of epochs controls how many times the entire dataset is passed through the network during training. By carefully fine-tuning these hyperparameters, you can enhance the neural network’s performance and improve its ability to accurately predict continuous output variables based on input data.
8. Consider using techniques like early stopping to prevent overfitting and save computational resources.
When working with neural networks for regression tasks in Python, it is crucial to consider implementing techniques like early stopping to prevent overfitting and optimize computational resources. Early stopping involves monitoring the model’s performance on a validation dataset during training and stopping the training process when the performance starts to degrade, thus preventing the model from memorizing noise in the training data. By incorporating early stopping into your neural network training process, you can improve generalization and efficiency, leading to more accurate predictions while conserving computational resources.