Neural Network Classification in Python
Neural networks have revolutionized the field of machine learning, particularly in the area of classification tasks. By leveraging the power of neural networks, developers can build sophisticated models that can classify data with high accuracy. In this article, we will explore how to implement neural network classification in Python.
Python provides a rich ecosystem of libraries and tools for working with neural networks. One popular library for building neural network models is TensorFlow, which offers a high-level API for constructing and training neural networks. Another widely used library is Keras, which provides a user-friendly interface for building neural network models.
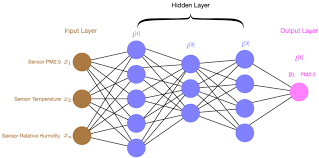
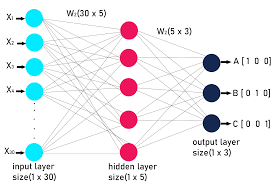
To implement neural network classification in Python, you first need to define your neural network architecture. This includes specifying the number of layers, the number of neurons in each layer, and the activation functions to use. For classification tasks, the output layer typically uses a softmax activation function to produce probability scores for each class.
Next, you need to compile your model by specifying the loss function and optimization algorithm to use during training. Common loss functions for classification tasks include categorical crossentropy and binary crossentropy. The optimization algorithm, such as Adam or SGD, is responsible for updating the weights of the neural network during training.
Once your model is compiled, you can train it on your dataset using the fit() method. During training, the model adjusts its weights based on the input data and corresponding labels to minimize the loss function. After training is complete, you can evaluate the performance of your model on a separate test dataset using metrics such as accuracy or precision-recall curves.
In conclusion, implementing neural network classification in Python involves defining your model architecture, compiling it with appropriate settings, training it on your data, and evaluating its performance. By leveraging powerful libraries like TensorFlow and Keras, developers can easily create robust neural network models for a wide range of classification tasks.
9 Essential Tips for Enhancing Neural Network Classification in Python
- Preprocess your data by normalizing or standardizing it to improve model performance.
- Split your dataset into training and testing sets to evaluate the model’s performance accurately.
- Choose an appropriate activation function for the hidden layers, such as ReLU or sigmoid.
- Experiment with different architectures (number of layers and neurons) to find the optimal structure for your problem.
- Regularize your model using techniques like dropout or L2 regularization to prevent overfitting.
- Batch normalization” can help speed up training and improve convergence in neural networks.
- Monitor the training process by visualizing metrics like loss and accuracy using tools like TensorBoard.
- Use early stopping to prevent overfitting by monitoring validation loss during training.
- Experiment with different optimizers like Adam, RMSprop, or SGD to find the one that works best for your model.
Preprocess your data by normalizing or standardizing it to improve model performance.
To improve the performance of your neural network classification model in Python, it is essential to preprocess your data by normalizing or standardizing it. Normalizing the data involves scaling the features to a consistent range, typically between 0 and 1, which helps prevent certain features from dominating others. On the other hand, standardizing the data involves transforming the features to have a mean of 0 and a standard deviation of 1, which can help the model converge faster during training. By applying these preprocessing techniques to your data before feeding it into the neural network, you can enhance the model’s performance and achieve more accurate classification results.
Split your dataset into training and testing sets to evaluate the model’s performance accurately.
To accurately evaluate the performance of a neural network classification model in Python, it is crucial to split the dataset into training and testing sets. By separating the data into these two distinct sets, developers can train the model on one portion and then assess its performance on unseen data from the testing set. This approach helps in detecting overfitting and ensures that the model generalizes well to new data. Splitting the dataset allows for a more reliable evaluation of the model’s accuracy, enabling developers to make informed decisions about its effectiveness in real-world applications.
Choose an appropriate activation function for the hidden layers, such as ReLU or sigmoid.
When working on neural network classification tasks in Python, it is crucial to select the right activation function for the hidden layers. Popular choices include Rectified Linear Unit (ReLU) and sigmoid functions. ReLU is commonly used for its simplicity and effectiveness in dealing with the vanishing gradient problem, while sigmoid can be useful for binary classification problems due to its output range between 0 and 1. Choosing an appropriate activation function for the hidden layers can significantly impact the performance and convergence of your neural network model, so it is essential to carefully consider the characteristics of your data and the nature of your classification task before making a decision.
Experiment with different architectures (number of layers and neurons) to find the optimal structure for your problem.
To enhance the performance of your neural network classification model in Python, it is recommended to experiment with different architectures by varying the number of layers and neurons. By exploring a range of configurations, you can find the optimal structure that best suits your specific problem. Adjusting the architecture allows you to fine-tune the model’s capacity to capture complex patterns in the data, leading to improved accuracy and generalization. Through systematic experimentation and evaluation of different neural network structures, you can discover the configuration that maximizes performance and effectively addresses the nuances of your classification task.
Regularize your model using techniques like dropout or L2 regularization to prevent overfitting.
Regularizing your neural network model using techniques like dropout or L2 regularization is crucial in preventing overfitting. Overfitting occurs when a model learns the training data too well, resulting in poor generalization to unseen data. Dropout randomly disables some neurons during training, forcing the network to learn more robust features. On the other hand, L2 regularization adds a penalty term to the loss function, discouraging overly complex models. By incorporating these regularization techniques into your neural network classification model in Python, you can improve its ability to generalize and make more accurate predictions on new data.
Batch normalization” can help speed up training and improve convergence in neural networks.
Batch normalization is a useful technique in neural network classification using Python that can significantly enhance the training process and boost convergence. By normalizing the input data within each mini-batch during training, batch normalization helps stabilize and speed up the learning process of neural networks. This technique reduces internal covariate shift, making it easier for the model to learn and converge to an optimal solution more efficiently. Overall, incorporating batch normalization into neural network models can lead to faster training times and improved performance on classification tasks.
Monitor the training process by visualizing metrics like loss and accuracy using tools like TensorBoard.
Monitoring the training process is crucial when working on neural network classification in Python. By visualizing key metrics such as loss and accuracy using tools like TensorBoard, developers can gain valuable insights into how their model is performing during training. Tracking these metrics allows for early detection of potential issues, fine-tuning of hyperparameters, and overall optimization of the neural network to achieve better classification results. TensorBoard provides interactive visualizations that make it easy to analyze the training progress and make informed decisions to improve the model’s performance.
Use early stopping to prevent overfitting by monitoring validation loss during training.
To prevent overfitting in neural network classification using Python, a helpful tip is to utilize early stopping by monitoring validation loss throughout the training process. By implementing early stopping, the model can automatically halt training when the validation loss stops improving, thus preventing the model from memorizing noise in the training data and improving its generalization capabilities. This technique helps ensure that the neural network does not overfit to the training data and performs well on unseen data, ultimately enhancing the model’s overall performance and reliability.
Experiment with different optimizers like Adam, RMSprop, or SGD to find the one that works best for your model.
To enhance the performance of your neural network classification model in Python, it is recommended to experiment with various optimizers such as Adam, RMSprop, or SGD. Different optimizers have unique characteristics and can impact the training process and final accuracy of the model. By testing different optimizers and observing their effects on the model’s performance, you can determine which one works best for your specific dataset and architecture. This iterative approach allows you to optimize the training process and achieve better results in neural network classification tasks.