The Power of Weka Multilayer Perceptron
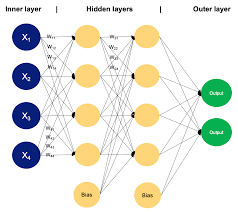
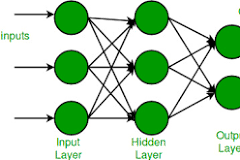
Weka Multilayer Perceptron is a powerful tool in the field of machine learning and artificial intelligence. It is a type of neural network that consists of multiple layers of interconnected nodes, each performing complex computations to learn patterns and make predictions.
One of the key strengths of Weka Multilayer Perceptron is its ability to handle complex non-linear relationships in data. By using multiple layers of nodes with nonlinear activation functions, it can learn intricate patterns and relationships that may not be captured by simpler models.
Moreover, Weka Multilayer Perceptron is known for its flexibility and adaptability. It can be applied to a wide range of tasks, including classification, regression, and pattern recognition. With proper tuning of parameters such as learning rate, number of hidden layers, and activation functions, it can achieve high levels of accuracy and performance.
Another advantage of Weka Multilayer Perceptron is its ability to generalize well to unseen data. Through the process of training on labeled data and testing on unseen data, it can make reliable predictions on new instances with good generalization capabilities.
In conclusion, Weka Multilayer Perceptron is a versatile and powerful tool in the realm of machine learning. Its ability to handle complex relationships, adapt to different tasks, and generalize effectively makes it a valuable asset for researchers and practitioners seeking to build accurate predictive models.
9 Essential Tips for Optimizing Weka’s Multilayer Perceptron
- Ensure your data is properly preprocessed before training the multilayer perceptron.
- Experiment with different numbers of hidden layers and neurons to find the best architecture for your dataset.
- Use cross-validation to evaluate the performance of the multilayer perceptron and avoid overfitting.
- Normalize or standardize your input features to improve the convergence and performance of the model.
- Monitor the learning curve to check for convergence and adjust parameters like learning rate accordingly.
- Consider using regularization techniques like L1 or L2 regularization to prevent overfitting.
- Visualize the decision boundaries created by the multilayer perceptron to understand its classification behavior.
- Tune hyperparameters such as learning rate, momentum, and batch size for optimal performance.
- Compare the performance of the multilayer perceptron with other machine learning models to ensure you are using the most suitable algorithm for your task.
Ensure your data is properly preprocessed before training the multilayer perceptron.
Before training the Weka Multilayer Perceptron, it is crucial to ensure that your data is properly preprocessed. Data preprocessing plays a vital role in the performance and accuracy of the model. Tasks such as handling missing values, normalizing features, and encoding categorical variables are essential steps to prepare the data for training. By preprocessing the data effectively, you can improve the quality of input information provided to the multilayer perceptron, leading to better learning outcomes and more reliable predictions.
Experiment with different numbers of hidden layers and neurons to find the best architecture for your dataset.
When working with Weka Multilayer Perceptron, it is crucial to experiment with various numbers of hidden layers and neurons to determine the optimal architecture for your specific dataset. By adjusting the number of hidden layers and neurons, you can fine-tune the model’s capacity to learn complex patterns and relationships within your data. Finding the right balance in architecture can significantly impact the performance and accuracy of your model, ultimately leading to more robust and reliable predictions. Therefore, thorough experimentation and optimization of the network’s structure are essential steps in maximizing the effectiveness of Weka Multilayer Perceptron for your machine learning tasks.
Use cross-validation to evaluate the performance of the multilayer perceptron and avoid overfitting.
When working with Weka Multilayer Perceptron, it is crucial to use cross-validation to assess the performance of the model and prevent overfitting. Cross-validation involves splitting the dataset into multiple subsets, training the model on a portion of the data, and evaluating its performance on the remaining unseen data. This technique helps in estimating how well the model will generalize to new data by testing it on different subsets. By using cross-validation, researchers and practitioners can gain insights into the model’s robustness and ensure that it does not memorize the training data but learns meaningful patterns that can be applied to unseen instances effectively.
Normalize or standardize your input features to improve the convergence and performance of the model.
To enhance the convergence and performance of your Weka Multilayer Perceptron model, it is advisable to normalize or standardize your input features. By scaling the input data to a common range, you can prevent certain features from dominating the learning process and ensure a more balanced impact on the model. This preprocessing step can help the neural network converge faster, improve its stability, and ultimately enhance its predictive accuracy.Normalization or standardization of input features is a valuable practice in optimizing the performance of Weka Multilayer Perceptron models.
Monitor the learning curve to check for convergence and adjust parameters like learning rate accordingly.
Monitoring the learning curve while using Weka Multilayer Perceptron is crucial for ensuring convergence and optimizing model performance. By observing how the model’s performance changes over time as it learns from the data, we can identify if the model is converging towards an optimal solution or if adjustments are needed. If the learning curve shows signs of plateauing or erratic behavior, it may indicate that the learning rate or other parameters need to be fine-tuned to improve convergence and accuracy. Regularly checking and analyzing the learning curve allows us to make informed decisions on adjusting parameters, ultimately leading to more effective and reliable predictions.
Consider using regularization techniques like L1 or L2 regularization to prevent overfitting.
When working with Weka Multilayer Perceptron, it is advisable to consider incorporating regularization techniques such as L1 or L2 regularization to prevent overfitting. By introducing regularization, you can effectively control the complexity of the model and reduce the risk of fitting noise in the training data. L1 regularization encourages sparsity in the model by penalizing large coefficients, while L2 regularization constrains the magnitude of the weights. These techniques help improve the generalization performance of the model and enhance its ability to make accurate predictions on unseen data.
Visualize the decision boundaries created by the multilayer perceptron to understand its classification behavior.
To gain a deeper insight into the classification behavior of the Weka Multilayer Perceptron, it is recommended to visualize the decision boundaries generated by the model. By visualizing these boundaries, one can better understand how the multilayer perceptron separates different classes in the input space. This visualization allows users to interpret and analyze how the model makes decisions and classifies data points, providing valuable insights into its classification capabilities and overall performance.
Tune hyperparameters such as learning rate, momentum, and batch size for optimal performance.
When working with Weka Multilayer Perceptron, it is crucial to tune hyperparameters like learning rate, momentum, and batch size to achieve optimal performance. These hyperparameters play a significant role in the training process of the neural network, affecting its convergence speed, stability, and overall accuracy. By carefully adjusting these parameters based on the specific characteristics of the dataset and task at hand, users can enhance the model’s learning capability and ensure that it performs at its best potential. Fine-tuning hyperparameters is a key step in maximizing the effectiveness of Weka Multilayer Perceptron for various machine learning tasks.
Compare the performance of the multilayer perceptron with other machine learning models to ensure you are using the most suitable algorithm for your task.
When working with Weka Multilayer Perceptron, it is essential to compare its performance with other machine learning models to determine the most suitable algorithm for your specific task. By conducting comparative analyses, you can evaluate the strengths and weaknesses of the multilayer perceptron in relation to alternative models, ensuring that you select the most effective approach for achieving optimal results. This practice not only helps in identifying the best-fitting algorithm for your data but also enhances the overall accuracy and efficiency of your predictive modeling process.