Understanding MNIST Neural Networks
In the world of machine learning and artificial intelligence, the MNIST dataset is a benchmark that has become synonymous with digit recognition. The acronym MNIST stands for the Modified National Institute of Standards and Technology database. It consists of 70,000 images of handwritten digits from 0 to 9, each image being a 28×28 pixel grayscale image.
The Importance of MNIST
The MNIST dataset is widely used for training and testing in the field of machine learning because it offers a simple yet challenging problem: digit recognition. This makes it an excellent starting point for those new to neural networks and deep learning. By working with this dataset, researchers and developers can test their algorithms on a well-understood problem before moving on to more complex tasks.
Building an MNIST Neural Network
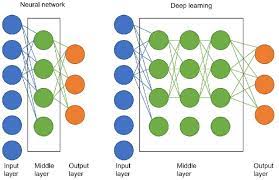
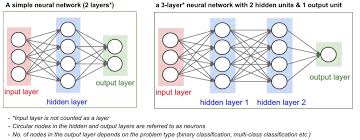
A neural network designed to recognize digits in the MNIST dataset typically consists of several layers:
- Input Layer: This layer has 784 neurons, one for each pixel in the 28×28 image.
- Hidden Layers: These layers perform feature extraction through various mathematical transformations. A common architecture includes one or two hidden layers with neurons ranging from 128 to 512.
- Output Layer: This layer has 10 neurons, each representing one digit (0-9). The neuron with the highest activation indicates the network’s prediction.
Activation Functions
The choice of activation function plays a crucial role in how well a neural network performs. Commonly used activation functions include ReLU (Rectified Linear Unit) for hidden layers and Softmax for the output layer. ReLU helps introduce non-linearity into the model, allowing it to learn complex patterns. Softmax converts raw model outputs into probabilities that sum up to one, making it easier to interpret which digit is being predicted.
Training Process
The training process involves feeding the network with input images and corresponding labels, then adjusting weights through backpropagation based on error calculations. The goal is to minimize this error using optimization algorithms like Stochastic Gradient Descent (SGD) or Adam.
# Example code snippet
import tensorflow as tf
from tensorflow.keras import layers, models
# Load and preprocess data
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Build model
model = models.Sequential([
layers.Flatten(input_shape=(28, 28)),
layers.Dense(128, activation='relu'),
layers.Dropout(0.2),
layers.Dense(10)
])
# Compile model
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# Train model
model.fit(x_train, y_train, epochs=5)
# Evaluate model
model.evaluate(x_test, y_test)
Conclusion
The MNIST neural network serves as an excellent introduction to deep learning concepts such as convolutional operations, activation functions, backpropagation algorithms, and more. By mastering this relatively simple task first through hands-on practice and experimentation with different architectures or hyperparameters settings; one can build confidence before tackling more advanced challenges within AI research fields!
9 Essential Tips for Building an Effective MNIST Neural Network
- Preprocess the MNIST images by normalizing pixel values to be between 0 and 1.
- Split the dataset into training and testing sets to evaluate the model’s performance.
- Choose an appropriate neural network architecture for image classification tasks, such as CNNs.
- Experiment with different activation functions like ReLU and softmax for hidden layers and output layer respectively.
- Use techniques like dropout regularization to prevent overfitting on the training data.
- Optimize hyperparameters like learning rate, batch size, and number of epochs through experimentation.
- Monitor the model’s performance using metrics like accuracy, loss, precision, recall, and F1 score.
- Visualize the training process with tools like TensorBoard to analyze trends and make improvements.
- Consider implementing data augmentation techniques to increase the diversity of training examples.
Preprocess the MNIST images by normalizing pixel values to be between 0 and 1.
To enhance the performance of your MNIST neural network, it is recommended to preprocess the MNIST images by normalizing pixel values to be between 0 and 1. This normalization step ensures that all pixel values fall within the same range, making it easier for the neural network to learn and make accurate predictions. By scaling the pixel values down to a range of 0 to 1, you can improve the convergence speed of the training process and help prevent issues such as vanishing or exploding gradients.
Split the dataset into training and testing sets to evaluate the model’s performance.
To ensure an accurate evaluation of the model’s performance in training a MNIST neural network, it is crucial to split the dataset into separate training and testing sets. By doing so, we can train the model on one portion of the data and then assess its effectiveness on unseen data from the testing set. This practice helps to gauge how well the model generalizes to new data and provides valuable insights into its ability to make accurate predictions. Splitting the dataset allows us to validate the model’s performance objectively and make informed decisions about its optimization for better results.
Choose an appropriate neural network architecture for image classification tasks, such as CNNs.
When working on image classification tasks like recognizing handwritten digits in the MNIST dataset, it is crucial to select a suitable neural network architecture. Convolutional Neural Networks (CNNs) are particularly well-suited for such tasks due to their ability to effectively capture spatial hierarchies and patterns within images. By leveraging CNNs, with their convolutional and pooling layers, researchers and developers can enhance the model’s performance in accurately classifying images. Choosing an appropriate neural network architecture, such as CNNs, can significantly impact the efficiency and accuracy of image classification tasks like those found in the MNIST dataset.
Experiment with different activation functions like ReLU and softmax for hidden layers and output layer respectively.
To enhance the performance of your MNIST neural network, it is recommended to experiment with different activation functions for the hidden layers and output layer. Utilizing Rectified Linear Unit (ReLU) activation function for the hidden layers can introduce non-linearity, enabling the network to learn complex patterns effectively. On the other hand, employing Softmax activation function for the output layer can convert raw model outputs into probabilities, facilitating easier interpretation of predicted digits. By exploring various activation functions and observing their impact on model accuracy, you can optimize your neural network’s performance in digit recognition tasks.
Use techniques like dropout regularization to prevent overfitting on the training data.
To prevent overfitting on the training data when working with the MNIST neural network, it is crucial to employ techniques like dropout regularization. Dropout regularization involves randomly “dropping out” a fraction of neurons during training, which helps prevent the network from becoming too reliant on specific features or patterns in the training data. By introducing this element of randomness, dropout regularization encourages the network to learn more robust and generalizable representations, ultimately improving its performance on unseen data.
Optimize hyperparameters like learning rate, batch size, and number of epochs through experimentation.
To enhance the performance of an MNIST neural network, it is essential to optimize key hyperparameters such as the learning rate, batch size, and number of epochs through systematic experimentation. Adjusting the learning rate can significantly impact the model’s convergence speed and accuracy, while optimizing the batch size can influence the stability of training and generalization capability. Furthermore, exploring different numbers of epochs allows for finding the right balance between underfitting and overfitting. By iteratively fine-tuning these hyperparameters based on empirical results, one can effectively improve the neural network’s overall effectiveness in digit recognition tasks using the MNIST dataset.
Monitor the model’s performance using metrics like accuracy, loss, precision, recall, and F1 score.
To ensure the effectiveness and reliability of a MNIST neural network model, it is essential to monitor its performance using various metrics. Metrics such as accuracy, loss, precision, recall, and F1 score provide valuable insights into how well the model is performing in terms of classification accuracy, error rate, true positive rate, false positive rate, and overall balance between precision and recall. By regularly evaluating these metrics during training and testing phases, developers can fine-tune the model’s parameters and architecture to enhance its predictive capabilities and optimize its performance on digit recognition tasks.
Visualize the training process with tools like TensorBoard to analyze trends and make improvements.
Visualizing the training process of an MNIST neural network using tools like TensorBoard can provide valuable insights into the model’s performance and behavior. By analyzing trends such as loss and accuracy over epochs, researchers and developers can identify patterns, anomalies, and areas for improvement. Visual representations of metrics and model architecture help in making informed decisions to optimize the neural network’s performance, fine-tune hyperparameters, and enhance overall training efficiency. This iterative process of analysis and adjustment based on visual feedback plays a crucial role in refining the MNIST neural network for better digit recognition accuracy.
Consider implementing data augmentation techniques to increase the diversity of training examples.
Consider implementing data augmentation techniques when working with the MNIST neural network to enhance the diversity of training examples. Data augmentation involves applying various transformations to the existing dataset, such as rotation, scaling, or flipping, to create new and slightly modified versions of the original images. By introducing these variations, the model becomes more robust and better equipped to generalize patterns across different variations of the same digit. This approach can help improve the network’s performance and accuracy by providing a richer and more diverse set of training data for learning.