Neural networks have revolutionized the field of artificial intelligence, enabling machines to learn complex patterns and make intelligent decisions. One common type of neural network architecture is the one hidden layer neural network, which strikes a balance between simplicity and effectiveness.
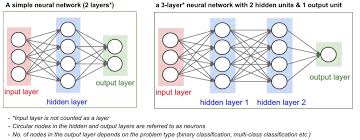
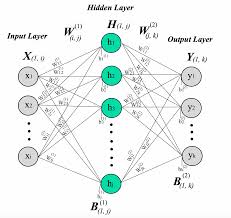
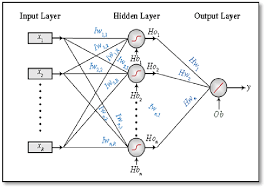
As the name suggests, a one hidden layer neural network consists of three layers: an input layer, a hidden layer, and an output layer. The input layer receives the raw data or features, which are then processed by the hidden layer through a series of weighted connections and activation functions. Finally, the output layer produces the desired prediction or classification based on the processed information.
The hidden layer is where the magic happens in a one hidden layer neural network. This layer allows the network to learn complex patterns and relationships within the data by adjusting the weights of connections during training. By using activation functions like sigmoid or ReLU, the hidden layer introduces non-linearity into the model, enabling it to capture intricate patterns that linear models cannot.
One key advantage of a one hidden layer neural network is its simplicity and interpretability. With only one hidden layer, the model is easier to train and understand compared to deeper architectures with multiple layers. This makes it ideal for tasks where transparency and explainability are important.
Despite its simplicity, a one hidden layer neural network can still achieve impressive results across various applications such as image recognition, natural language processing, and predictive analytics. By striking a balance between complexity and performance, this architecture serves as a versatile tool in the hands of machine learning practitioners.
In conclusion, the one hidden layer neural network represents a fundamental building block in modern artificial intelligence systems. Its ability to learn intricate patterns while maintaining simplicity makes it a valuable asset in tackling diverse challenges across different domains.
5 Essential Tips for Optimizing a Single Hidden Layer Neural Network
- Choose the appropriate activation function for the hidden layer, such as ReLU or Sigmoid.
- Ensure the number of neurons in the hidden layer is neither too few (underfitting) nor too many (overfitting).
- Initialize the weights and biases of the neural network properly to prevent vanishing or exploding gradients.
- Regularize the model using techniques like L1 or L2 regularization to avoid overfitting.
- Monitor the training process by visualizing metrics like loss and accuracy to assess model performance.
Choose the appropriate activation function for the hidden layer, such as ReLU or Sigmoid.
When working with a one hidden layer neural network, selecting the right activation function for the hidden layer is crucial for the model’s performance. Popular choices like ReLU (Rectified Linear Unit) or Sigmoid can significantly impact how the network learns and processes information. ReLU is known for its simplicity and effectiveness in handling vanishing gradient problems, making it a common choice for hidden layers. On the other hand, Sigmoid is useful when dealing with binary classification tasks due to its output range between 0 and 1. By carefully considering the nature of the data and the task at hand, choosing an appropriate activation function for the hidden layer can enhance the network’s ability to capture complex patterns and make accurate predictions.
Ensure the number of neurons in the hidden layer is neither too few (underfitting) nor too many (overfitting).
When designing a one hidden layer neural network, it is crucial to carefully consider the number of neurons in the hidden layer to achieve optimal performance. Having too few neurons may result in underfitting, where the model lacks the capacity to capture complex patterns in the data, leading to poor accuracy and generalization. On the other hand, having too many neurons can lead to overfitting, where the model memorizes the training data instead of learning underlying patterns, causing it to perform poorly on unseen data. Finding the right balance in the number of neurons is essential for ensuring that the neural network can effectively learn from the data and make accurate predictions.
Initialize the weights and biases of the neural network properly to prevent vanishing or exploding gradients.
Properly initializing the weights and biases of a one hidden layer neural network is crucial to prevent issues like vanishing or exploding gradients during training. By setting initial values that are neither too small nor too large, we can ensure that the network learns effectively without encountering numerical instability. This careful initialization strategy helps the model converge faster and more reliably, ultimately leading to better performance and more accurate predictions.
Regularize the model using techniques like L1 or L2 regularization to avoid overfitting.
To enhance the performance and generalization of a one hidden layer neural network, it is crucial to apply regularization techniques such as L1 or L2 regularization. By incorporating regularization into the model training process, overfitting can be mitigated effectively. L1 regularization encourages sparsity in the network by penalizing large weights, while L2 regularization prevents extreme weight values by adding a penalty term based on the sum of squared weights. These techniques help to control the complexity of the model and improve its ability to generalize well to unseen data, ultimately leading to more robust and reliable predictions.
Monitor the training process by visualizing metrics like loss and accuracy to assess model performance.
Monitoring the training process of a one hidden layer neural network is essential for assessing model performance and ensuring successful learning. By visualizing key metrics such as loss and accuracy during training, developers can gain valuable insights into how well the model is learning from the data. Tracking these metrics allows for timely adjustments to the model’s parameters and architecture, ultimately leading to improved performance and better decision-making in optimizing the neural network for desired outcomes.