Understanding the Dense Layer in Neural Networks
Neural networks have become a cornerstone of modern artificial intelligence, powering applications from image recognition to natural language processing. At the heart of these networks are various types of layers that process and transform data. Among them, the dense layer, also known as a fully connected layer, plays a crucial role in many neural network architectures.
What is a Dense Layer?
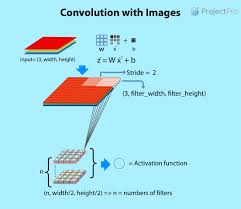
A dense layer is one where each neuron receives input from all neurons in the previous layer, making it “fully connected.” This means that every output value is computed as a weighted sum of inputs, followed by an activation function. The dense layer is responsible for learning global patterns in data by adjusting weights during training.
How Does a Dense Layer Work?
The operation of a dense layer can be broken down into several key steps:
- Weighted Sum: Each neuron takes inputs from all neurons in the previous layer and computes a weighted sum. This involves multiplying each input by its corresponding weight and adding them together.
- Bias Addition: A bias term is added to the weighted sum to allow for more flexibility in learning.
- Activation Function: The result is passed through an activation function, such as ReLU (Rectified Linear Unit) or sigmoid, which introduces non-linearity into the model. This non-linearity allows neural networks to learn complex patterns.
The Role of Weights and Biases
The weights and biases in a dense layer are parameters that are learned during training. Initially set randomly or using specific initialization techniques, they are updated iteratively using optimization algorithms like stochastic gradient descent (SGD). The goal is to minimize the difference between predicted outputs and actual outputs by adjusting these parameters.
Advantages of Dense Layers
The dense layer’s ability to connect every neuron with each neuron in the previous layer makes it versatile for learning complex relationships within data. It excels at capturing intricate patterns due to its comprehensive connectivity structure.
Limitations and Considerations
While powerful, dense layers can introduce challenges:
- Overfitting: Due to their large number of parameters, dense layers can easily overfit on small datasets. Regularization techniques like dropout or L2 regularization can help mitigate this issue.
- Computationally Intensive: The full connectivity requires significant computational resources, especially with large networks or input sizes.
Dense Layers in Practice
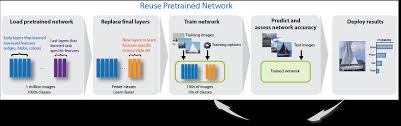
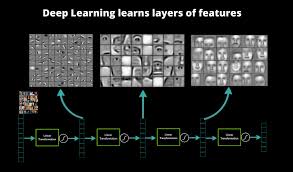
Dense layers are commonly used at the end of convolutional neural networks (CNNs) for tasks like classification. After feature extraction through convolutional layers, one or more dense layers are added to make predictions based on those features.
Conclusion
The dense layer remains an essential component of many neural network architectures due to its ability to learn complex representations. While it comes with certain challenges such as overfitting and computational demands, its versatility makes it invaluable across various AI applications. Understanding how dense layers work helps practitioners design more effective neural network models tailored to specific tasks.
Understanding Dense Layers in Neural Networks: Key Questions and Insights
- What is a dense layer in a neural network?
- How does a dense layer differ from other types of layers in neural networks?
- What is the purpose of using a dense layer in a neural network?
- How are weights and biases utilized in a dense layer?
- What role does the activation function play in a dense layer?
- What are the advantages of incorporating dense layers into neural network architectures?
- What challenges or limitations are associated with using dense layers?
- In what scenarios or applications are dense layers commonly used?
- How can one prevent overfitting when utilizing dense layers?
What is a dense layer in a neural network?
A dense layer in a neural network, also known as a fully connected layer, is a fundamental component that plays a vital role in processing and transforming data. In a dense layer, each neuron receives input from all neurons in the previous layer, making it fully connected. This connectivity allows the dense layer to learn global patterns in the data by computing weighted sums of inputs and applying activation functions. Essentially, a dense layer helps neural networks capture complex relationships within the data through its comprehensive connectivity structure.
How does a dense layer differ from other types of layers in neural networks?
In the realm of neural networks, a frequently asked question revolves around understanding how a dense layer differs from other types of layers. Unlike specialized layers such as convolutional or recurrent layers that are tailored for specific tasks like image recognition or sequential data processing, a dense layer stands out for its full connectivity. In a dense layer, each neuron receives input from every neuron in the preceding layer, enabling it to capture global patterns and relationships within the data. This comprehensive interconnection distinguishes dense layers as versatile components that excel at learning complex representations across various types of datasets and tasks in neural network architectures.
What is the purpose of using a dense layer in a neural network?
The purpose of using a dense layer in a neural network is to facilitate the learning of complex patterns and relationships within data. By connecting every neuron in a layer to every neuron in the subsequent layer, the dense layer enables the network to capture global dependencies and extract higher-level features from the input data. This comprehensive connectivity structure allows for the modeling of intricate relationships, making dense layers particularly effective in tasks that require understanding and processing complex information, such as image recognition, natural language processing, and predictive analytics.
How are weights and biases utilized in a dense layer?
In a dense layer of a neural network, weights and biases play crucial roles in the computation of output values. The weights represent the strength of connections between neurons in the current layer and neurons in the previous layer. During training, these weights are adjusted to minimize the difference between predicted outputs and actual outputs, allowing the network to learn from data. Biases, on the other hand, provide each neuron with an additional degree of freedom by allowing for shifts in the activation function. Together, weights and biases enable the dense layer to learn complex patterns and relationships within data by fine-tuning their values through iterative optimization algorithms like stochastic gradient descent.
What role does the activation function play in a dense layer?
The activation function in a dense layer of a neural network plays a crucial role in introducing non-linearity to the model. By applying an activation function to the output of each neuron, the network gains the ability to learn complex patterns and relationships in the data. Without activation functions, multiple stacked dense layers would essentially collapse into a single linear transformation, limiting the network’s capacity to capture intricate features. Different activation functions like ReLU, sigmoid, or tanh bring their unique properties to the network, allowing for diverse representations and enabling better learning of nonlinear relationships within the data. Ultimately, the choice of activation function in a dense layer significantly influences the network’s performance and its ability to model complex real-world phenomena effectively.
What are the advantages of incorporating dense layers into neural network architectures?
Incorporating dense layers into neural network architectures offers several advantages that enhance the model’s ability to learn and generalize from data. Dense layers, being fully connected, enable the network to capture complex relationships and patterns by allowing each neuron to interact with every neuron in the preceding layer. This comprehensive connectivity facilitates the learning of global patterns, making dense layers particularly effective for tasks requiring integration of information across the entire input space. Furthermore, dense layers provide flexibility in designing network architectures, as they can be used in various configurations and combined with other types of layers like convolutional or recurrent layers. Despite their computational intensity, the richness they add to model expressiveness often outweighs this drawback, making them a staple in many deep learning models.
What challenges or limitations are associated with using dense layers?
When it comes to using dense layers in neural networks, several challenges and limitations need to be considered. One common issue is the potential for overfitting, especially when dealing with small datasets. The large number of parameters in dense layers can lead to the model memorizing noise or irrelevant patterns instead of learning generalizable features. To address this, techniques like dropout or L2 regularization are often employed to prevent overfitting. Additionally, the computational intensity of dense layers can pose challenges, particularly in deep networks or with high-dimensional input data. Careful optimization and model design are crucial to effectively manage these challenges and maximize the performance of neural networks utilizing dense layers.
In what scenarios or applications are dense layers commonly used?
Dense layers in neural networks are commonly used in a wide range of scenarios and applications where capturing complex relationships in data is crucial. One common application of dense layers is in image classification tasks, where they are often employed at the end of convolutional neural networks (CNNs) to make predictions based on extracted features. Dense layers are also prevalent in natural language processing (NLP) tasks such as sentiment analysis, machine translation, and text generation, where they help model intricate linguistic patterns. Additionally, dense layers find utility in regression tasks, anomaly detection, and various other machine learning applications that require learning from high-dimensional data with complex interactions. Their versatility and ability to learn global patterns make dense layers a fundamental building block in designing effective neural network architectures for diverse real-world problems.
How can one prevent overfitting when utilizing dense layers?
Preventing overfitting when utilizing dense layers in a neural network is a common concern among practitioners. One effective strategy to address this issue is to incorporate regularization techniques, such as dropout or L2 regularization, into the model architecture. Dropout randomly deactivates a fraction of neurons during training, forcing the network to learn more robust and generalizable features. L2 regularization penalizes large weights in the model, encouraging simpler and smoother weight configurations. By applying these techniques judiciously, practitioners can mitigate the risk of overfitting in dense layers and improve the overall performance and generalization capabilities of the neural network.