The Power of Multilayer Perceptron Networks
Artificial neural networks have revolutionized the field of machine learning, and one of the most popular and powerful types is the Multilayer Perceptron (MLP) network. MLPs are versatile and effective in solving complex problems across various domains.
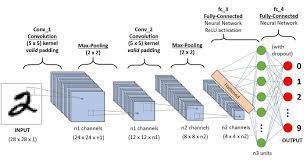
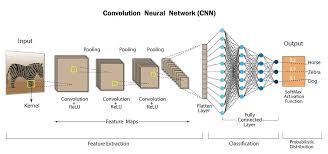
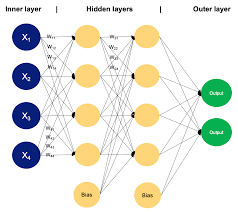
At the core of an MLP network are multiple layers of interconnected nodes, each performing weighted computations to process input data and produce output. The layers include an input layer, one or more hidden layers, and an output layer. The hidden layers enable the network to learn intricate patterns and relationships within the data.
One key strength of MLP networks is their ability to approximate any continuous function, making them universal function approximators. This flexibility allows MLPs to handle a wide range of tasks, such as classification, regression, pattern recognition, and more.
Training an MLP involves feeding it with labeled data and adjusting the weights of connections through a process called backpropagation. This iterative learning method helps the network improve its predictions over time by minimizing errors between predicted and actual outputs.
MLP networks excel in tasks that require nonlinear relationships and can handle high-dimensional data effectively. They have been successfully applied in image recognition, natural language processing, financial forecasting, and many other real-world applications.
In conclusion, Multilayer Perceptron networks represent a powerful tool in the realm of artificial intelligence and machine learning. Their capability to learn complex patterns and generalize well to new data makes them invaluable for tackling challenging problems across diverse fields.
6 Essential Tips for Optimizing Multilayer Perceptron Networks
- Use an appropriate activation function for each layer, such as ReLU for hidden layers and softmax for the output layer.
- Normalize input data to improve convergence and training speed.
- Experiment with different numbers of layers and neurons to find the optimal architecture for your specific problem.
- Regularize the network using techniques like dropout or L2 regularization to prevent overfitting.
- Monitor training progress by tracking metrics like loss and accuracy to ensure the network is learning effectively.
- Consider using batch normalization to stabilize and speed up training.
Use an appropriate activation function for each layer, such as ReLU for hidden layers and softmax for the output layer.
When working with a multilayer perceptron network, it is crucial to select the right activation functions for each layer to ensure optimal performance. For hidden layers, the Rectified Linear Unit (ReLU) activation function is commonly used due to its ability to handle non-linearities effectively and prevent the vanishing gradient problem. On the other hand, the softmax activation function is ideal for the output layer when dealing with classification tasks, as it normalizes the output into a probability distribution over multiple classes. By choosing appropriate activation functions for each layer, such as ReLU for hidden layers and softmax for the output layer, you can enhance the network’s learning capabilities and improve its accuracy in making predictions.
Normalize input data to improve convergence and training speed.
Normalizing input data is a crucial tip for enhancing the convergence and training speed of a multilayer perceptron network. By scaling input features to a similar range, the network can more effectively learn the underlying patterns in the data without being skewed by varying magnitudes. This normalization process helps prevent certain features from dominating the learning process and ensures that the model converges faster and more accurately during training. Overall, normalizing input data is a simple yet powerful technique that can significantly boost the performance of a multilayer perceptron network.
Experiment with different numbers of layers and neurons to find the optimal architecture for your specific problem.
To harness the full potential of a multilayer perceptron network, it is essential to experiment with varying numbers of layers and neurons to discover the optimal architecture tailored to your specific problem. By systematically adjusting the structure of the network, you can fine-tune its capacity to capture intricate patterns and relationships within your data. This iterative process of exploration and refinement allows you to optimize the performance of the network and enhance its ability to effectively tackle the unique challenges presented by your problem domain.
Regularize the network using techniques like dropout or L2 regularization to prevent overfitting.
Regularizing the multilayer perceptron network using techniques like dropout or L2 regularization is essential to prevent overfitting. Overfitting occurs when a model learns the noise and details of the training data too well, leading to poor generalization on unseen data. Dropout randomly deactivates some neurons during training, forcing the network to learn more robust features. On the other hand, L2 regularization adds a penalty term to the loss function based on the magnitude of weights, discouraging overly complex models. By incorporating these regularization techniques, the multilayer perceptron network can achieve better performance and generalization on new data.
Monitor training progress by tracking metrics like loss and accuracy to ensure the network is learning effectively.
Monitoring the training progress of a multilayer perceptron network is crucial for ensuring its effectiveness in learning. By tracking metrics such as loss and accuracy during the training process, developers can gain insights into how well the network is performing and make necessary adjustments to improve its learning capabilities. Monitoring these metrics allows for early detection of potential issues, helps in fine-tuning the network’s parameters, and ultimately leads to a more efficient and successful training process.
Consider using batch normalization to stabilize and speed up training.
When working with a multilayer perceptron network, it is beneficial to consider incorporating batch normalization techniques to enhance the stability and accelerate the training process. Batch normalization helps in normalizing the input of each layer by adjusting and scaling the activations. This not only aids in mitigating issues like vanishing or exploding gradients but also contributes to faster convergence during training. By incorporating batch normalization into your multilayer perceptron network, you can improve its performance, efficiency, and overall training effectiveness.