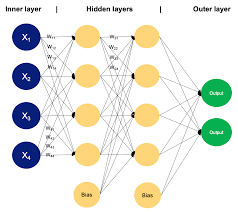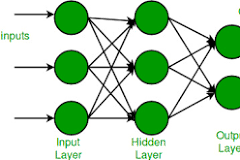
In the field of artificial intelligence and machine learning, the multilayer perceptron algorithm stands out as a powerful and versatile tool for solving complex problems. This algorithm, inspired by the structure and function of the human brain, is a type of artificial neural network that consists of multiple layers of interconnected nodes, or neurons.
At its core, the multilayer perceptron algorithm is designed to learn from input data and make predictions or classifications based on that data. Each neuron in the network receives input signals, processes them using a set of weights and biases, and produces an output signal that is passed on to the next layer of neurons.
One of the key strengths of the multilayer perceptron algorithm is its ability to learn complex patterns and relationships in data through a process known as training. During training, the algorithm adjusts the weights and biases of its neurons in response to feedback provided by a set of labeled training examples. This iterative process allows the algorithm to improve its performance over time and make more accurate predictions.
Another important feature of the multilayer perceptron algorithm is its flexibility and scalability. By adjusting the number of layers, neurons, and activation functions in the network, researchers and developers can tailor the algorithm to suit a wide range of applications, from image recognition and natural language processing to financial forecasting and medical diagnosis.
Despite its power and versatility, the multilayer perceptron algorithm is not without its challenges. Training a deep neural network with multiple layers can be computationally intensive and require large amounts of labeled data. Overfitting, where the model performs well on training data but poorly on unseen data, is also a common issue that researchers must address.
Nevertheless, with ongoing advances in hardware technology, optimization techniques, and deep learning frameworks, the multilayer perceptron algorithm continues to push the boundaries of what is possible in artificial intelligence. As researchers continue to explore new architectures and algorithms inspired by biological neural networks, we can expect even greater breakthroughs in machine learning in the years to come.
7 Essential Tips for Optimizing Multilayer Perceptron Algorithms
- Ensure the input features are properly normalized for better performance.
- Choose an appropriate activation function for the hidden layers, such as ReLU or sigmoid.
- Experiment with different numbers of hidden layers and neurons to find the optimal architecture.
- Use techniques like dropout regularization to prevent overfitting in the model.
- Monitor the training process by keeping track of loss and accuracy metrics.
- Consider tuning hyperparameters like learning rate and batch size for improved convergence.
- Evaluate the model using cross-validation to assess its generalization performance.
Ensure the input features are properly normalized for better performance.
One crucial tip for optimizing the performance of the multilayer perceptron algorithm is to ensure that the input features are properly normalized. Normalizing the input data helps to bring all features to a similar scale, preventing certain features from dominating the learning process due to their larger magnitudes. By normalizing the input features, we can improve the convergence speed of the algorithm, enhance its stability during training, and ultimately achieve better performance in terms of accuracy and generalization on unseen data. This simple yet effective preprocessing step can have a significant impact on the overall effectiveness of a multilayer perceptron model.
Choose an appropriate activation function for the hidden layers, such as ReLU or sigmoid.
When working with the multilayer perceptron algorithm, it is crucial to choose an appropriate activation function for the hidden layers to ensure optimal performance. Common choices for activation functions include Rectified Linear Unit (ReLU) and sigmoid. ReLU is known for its simplicity and effectiveness in handling the vanishing gradient problem, which can occur during training when gradients become too small to update the weights effectively. On the other hand, sigmoid functions are useful for producing output values within a specific range, making them suitable for tasks like binary classification. By selecting the right activation function for the hidden layers, researchers and developers can enhance the learning capabilities of the multilayer perceptron algorithm and improve its overall accuracy and efficiency.
Experiment with different numbers of hidden layers and neurons to find the optimal architecture.
When working with the multilayer perceptron algorithm, it is crucial to experiment with different numbers of hidden layers and neurons to discover the optimal architecture for your specific task. By varying the complexity of the network through adjusting the number of layers and neurons, you can fine-tune the model to achieve better performance and accuracy. Finding the right balance between model complexity and computational efficiency is key to maximizing the algorithm’s effectiveness in solving complex problems and making accurate predictions based on input data.
Use techniques like dropout regularization to prevent overfitting in the model.
When working with the multilayer perceptron algorithm, it is crucial to employ techniques like dropout regularization to prevent overfitting in the model. Overfitting occurs when a model learns the details and noise in the training data to the extent that it negatively impacts its performance on unseen data. Dropout regularization helps address this issue by randomly ignoring a fraction of neurons during training, forcing the network to learn more robust and generalizable features. By incorporating dropout regularization into the training process, researchers can improve the model’s ability to generalize well to new data and enhance its overall performance.
Monitor the training process by keeping track of loss and accuracy metrics.
When working with the multilayer perceptron algorithm, it is crucial to monitor the training process by keeping track of loss and accuracy metrics. Loss metrics provide insight into how well the model is performing during training by measuring the difference between predicted outputs and actual targets. On the other hand, accuracy metrics give a clear indication of the model’s overall performance in making correct predictions. By regularly monitoring these metrics throughout the training process, developers can identify potential issues, fine-tune model parameters, and ensure that the multilayer perceptron algorithm is learning effectively and producing accurate results.
Consider tuning hyperparameters like learning rate and batch size for improved convergence.
When working with the multilayer perceptron algorithm, it is crucial to consider tuning hyperparameters such as the learning rate and batch size to enhance convergence and optimize performance. The learning rate determines how quickly the model adapts to the training data, while the batch size specifies the number of training examples used in each iteration. By carefully adjusting these hyperparameters through experimentation and validation, researchers can fine-tune the algorithm’s behavior, improve training efficiency, and achieve better convergence towards accurate predictions or classifications.
Evaluate the model using cross-validation to assess its generalization performance.
When working with the multilayer perceptron algorithm, it is crucial to evaluate the model using cross-validation to assess its generalization performance. Cross-validation is a technique that helps determine how well a model will perform on unseen data by splitting the dataset into multiple subsets for training and testing. By using cross-validation, researchers can gain insights into the model’s ability to generalize to new data and identify any potential issues such as overfitting. This approach provides a more robust assessment of the multilayer perceptron algorithm’s performance and helps ensure its reliability in real-world applications.