Exploring a Simple Neural Network Example
Neural networks are a fundamental concept in artificial intelligence and machine learning. They are designed to mimic the way the human brain works by processing information through interconnected nodes, or neurons. In this article, we will delve into a simple neural network example to understand how it functions.
Understanding the Basics
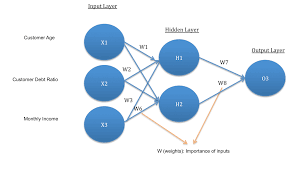
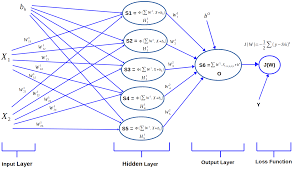
A neural network consists of layers of neurons that are interconnected through weighted connections. The input layer receives data, which is then processed through hidden layers before producing an output. Each neuron applies an activation function to the incoming data and passes the result to the next layer.
Example: XOR Gate
Let’s consider a simple example of training a neural network to act as an XOR gate. An XOR gate outputs true only when the inputs differ (one is true and the other is false). We can create a neural network with an input layer, a hidden layer, and an output layer to learn this behavior.
In this case, we need to define the structure of the neural network, initialize weights randomly, feed input data (0, 0), (0, 1), (1, 0), and (1, 1) with corresponding labels (0, 1, 1, 0), and train the network using backpropagation algorithm to adjust weights based on errors.
Conclusion
By exploring this simple neural network example, we have gained insights into how neural networks learn patterns from data and make predictions. Neural networks have revolutionized various fields such as image recognition, natural language processing, and more by enabling machines to perform complex tasks efficiently.
7 Essential Tips for Building a Simple Neural Network from Scratch
- Start by defining the input and output layers of the neural network.
- Choose an appropriate activation function for hidden layers, such as ReLU or Sigmoid.
- Randomly initialize the weights of the neural network to break symmetry.
- Implement forward propagation to compute the predicted output.
- Calculate the loss between predicted output and actual output using a suitable loss function like Mean Squared Error.
- Use backpropagation with gradient descent to update weights and minimize the loss.
- Repeat forward and backward passes through the network for multiple epochs to improve performance.
Start by defining the input and output layers of the neural network.
To begin exploring a simple neural network example, it is crucial to start by defining the input and output layers of the network. The input layer receives the data that needs to be processed, while the output layer generates the final results or predictions based on the processed information. By clearly defining these layers, we establish the foundation for how data flows through the network and how it ultimately influences the output produced by the neural network. This initial step sets the stage for building a structured and effective neural network that can learn from data and make accurate predictions.
Choose an appropriate activation function for hidden layers, such as ReLU or Sigmoid.
When implementing a simple neural network example, it is crucial to select the right activation function for the hidden layers. Popular choices like Rectified Linear Unit (ReLU) or Sigmoid can greatly impact the network’s performance. ReLU is known for its simplicity and effectiveness in handling vanishing gradient problems, while Sigmoid is commonly used for binary classification tasks due to its smooth output range between 0 and 1. By choosing an appropriate activation function, such as ReLU or Sigmoid, for the hidden layers, you can enhance the network’s learning capabilities and overall efficiency in processing complex data patterns.
Randomly initialize the weights of the neural network to break symmetry.
In the context of a simple neural network example, it is crucial to randomly initialize the weights of the network to break symmetry. Symmetry in weight initialization can lead to all neurons in a layer learning the same features, limiting the network’s capacity to learn diverse patterns from data. By assigning random values to the weights, each neuron starts with a unique set of parameters, allowing them to independently learn and adapt during the training process. This randomness helps prevent the network from getting stuck in suboptimal solutions and encourages robust learning of complex relationships within the data.
Implement forward propagation to compute the predicted output.
When working with a simple neural network example, it is crucial to implement forward propagation to compute the predicted output. Forward propagation involves passing the input data through the neural network layers, applying weights and activation functions at each step, and ultimately generating a prediction at the output layer. This process allows the neural network to learn from the input data and make accurate predictions based on the learned patterns. By mastering forward propagation, one can better understand how neural networks process information and produce meaningful outputs.
Calculate the loss between predicted output and actual output using a suitable loss function like Mean Squared Error.
In a simple neural network example, one crucial step is calculating the loss between the predicted output and the actual output using a suitable loss function like Mean Squared Error. This process involves measuring the disparity between what the model predicts and the ground truth data. By utilizing a loss function such as Mean Squared Error, which squares the difference between predicted and actual values and averages them, we can quantify how well our neural network is performing and adjust its parameters accordingly through techniques like backpropagation to minimize this loss.
Use backpropagation with gradient descent to update weights and minimize the loss.
In the realm of neural networks, employing backpropagation in conjunction with gradient descent is a crucial strategy for enhancing the learning process. By utilizing backpropagation, the network can calculate the gradients of the loss function with respect to each weight, enabling adjustments to be made in a way that minimizes the overall loss. With gradient descent, these gradients are utilized to update the weights iteratively, moving towards a configuration that optimizes the network’s performance. This iterative process of updating weights based on gradients allows neural networks to learn from data and improve their predictive capabilities effectively.
Repeat forward and backward passes through the network for multiple epochs to improve performance.
To improve the performance of a simple neural network example, it is essential to repeat forward and backward passes through the network for multiple epochs. By iterating over the dataset multiple times, the network can adjust its weights and learn from errors more effectively. This process allows the neural network to refine its predictions and enhance its ability to recognize patterns in the data, ultimately leading to improved performance and accuracy over time.