The Power of Object Detection Neural Networks
Object detection is a crucial task in computer vision that involves identifying and locating objects within an image or video. With the advancement of technology, object detection neural networks have become increasingly popular and powerful tools for automating this process.
Neural networks are artificial intelligence models inspired by the structure and function of the human brain. Object detection neural networks, in particular, are designed to analyze visual information and recognize objects based on their features and characteristics.
One of the key advantages of using neural networks for object detection is their ability to learn from vast amounts of labeled data. By training the network on a diverse set of images with annotated objects, it can gradually improve its accuracy and efficiency in detecting various objects in different contexts.
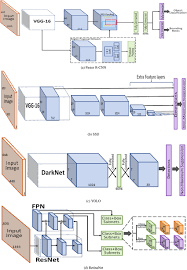
There are several types of object detection neural networks, each with its unique architecture and capabilities. For example, region-based convolutional neural networks (R-CNNs) divide an image into regions and then classify each region to determine the presence of objects. On the other hand, single-shot detectors (SSDs) can detect objects in real-time by predicting their bounding boxes and class labels simultaneously.
Object detection neural networks have a wide range of applications across industries, including autonomous driving, surveillance systems, medical imaging, retail analytics, and more. By accurately identifying and localizing objects in visual data, these networks can enhance decision-making processes, improve efficiency, and enable new possibilities for automation.
In conclusion, object detection neural networks represent a significant advancement in computer vision technology. Their ability to automatically detect objects in images and videos with high accuracy has opened up new opportunities for innovation and development across various fields. As research continues to progress in this area, we can expect even more sophisticated object detection models that further push the boundaries of what is possible in visual recognition.
8 Essential Tips for Enhancing Object Detection with Neural Networks
- Ensure your dataset is diverse and representative of the objects you want to detect.
- Preprocess your data by resizing images, normalizing pixel values, and augmenting with techniques like rotation and flipping.
- Choose a suitable neural network architecture like YOLO, SSD, or Faster R-CNN based on your requirements.
- Fine-tune pre-trained models to improve accuracy and reduce training time.
- Experiment with different anchor box sizes and aspect ratios for better object localization.
- Use techniques like Non-Maximum Suppression (NMS) to eliminate duplicate detections.
- Optimize hyperparameters such as learning rate, batch size, and optimizer choice for efficient training.
- Evaluate your model using metrics like precision, recall, and mAP to assess its performance.
Ensure your dataset is diverse and representative of the objects you want to detect.
Ensuring that your dataset is diverse and representative of the objects you want to detect is a critical tip for training an effective object detection neural network. A diverse dataset helps the neural network learn to recognize objects in various contexts, lighting conditions, and backgrounds, improving its ability to generalize and accurately detect objects in real-world scenarios. By including a wide range of examples that reflect the diversity of objects you expect the network to encounter, you can enhance its performance and reliability in detecting and localizing objects with precision.
Preprocess your data by resizing images, normalizing pixel values, and augmenting with techniques like rotation and flipping.
To enhance the performance of your object detection neural network, it is essential to preprocess your data effectively. This includes resizing images to a consistent size, normalizing pixel values to ensure uniformity, and augmenting the dataset with techniques such as rotation and flipping. By standardizing the input data in this way, you can improve the network’s ability to learn and generalize patterns, leading to more accurate and robust object detection results.
Choose a suitable neural network architecture like YOLO, SSD, or Faster R-CNN based on your requirements.
When implementing an object detection neural network, it is essential to carefully consider your specific requirements and objectives in order to choose the most suitable architecture. Options such as YOLO, SSD, or Faster R-CNN offer distinct advantages and are optimized for different scenarios. YOLO (You Only Look Once) is known for its real-time processing capabilities, making it ideal for applications where speed is crucial. SSD (Single Shot MultiBox Detector) excels in detecting multiple objects within a single frame efficiently. On the other hand, Faster R-CNN (Region-based Convolutional Neural Network) provides accurate object localization by dividing images into regions of interest. By selecting the appropriate neural network architecture based on your needs, you can optimize performance and achieve the desired outcomes in object detection tasks.
Fine-tune pre-trained models to improve accuracy and reduce training time.
Fine-tuning pre-trained models is a highly effective strategy in optimizing object detection neural networks. By starting with a pre-trained model that has already learned features from a large dataset, developers can significantly enhance both accuracy and efficiency in object detection tasks. Fine-tuning allows the model to adapt to specific characteristics of the new dataset, requiring less training time and computational resources compared to training from scratch. This approach not only improves the overall performance of the neural network but also enables faster deployment of robust object detection systems in various real-world applications.
Experiment with different anchor box sizes and aspect ratios for better object localization.
To enhance object localization accuracy in object detection neural networks, it is recommended to experiment with various anchor box sizes and aspect ratios. By adjusting the dimensions of anchor boxes, which serve as reference points for predicting object locations, the network can better adapt to objects of different scales and shapes within an image. This flexibility in anchor box sizes and aspect ratios allows for more precise and effective object localization, ultimately improving the overall performance of the object detection model.
Use techniques like Non-Maximum Suppression (NMS) to eliminate duplicate detections.
To enhance the accuracy and efficiency of object detection neural networks, it is essential to incorporate techniques such as Non-Maximum Suppression (NMS) to eliminate duplicate detections. NMS helps in refining the output of the neural network by suppressing multiple overlapping bounding boxes for the same object, ensuring that only the most relevant and accurate detection is retained. By implementing NMS, we can streamline the post-processing stage of object detection and improve the overall performance of the model in identifying and localizing objects within images or videos.
Optimize hyperparameters such as learning rate, batch size, and optimizer choice for efficient training.
To optimize the performance of an object detection neural network, it is essential to carefully tune hyperparameters such as the learning rate, batch size, and choice of optimizer. Adjusting these parameters can significantly impact the efficiency and effectiveness of the training process. A well-chosen learning rate ensures that the model converges to an optimal solution without getting stuck in local minima or diverging. The batch size affects the stability of the training process and can influence the speed at which the model learns. Additionally, selecting the right optimizer can help improve convergence speed and overall performance. By fine-tuning these hyperparameters, developers can enhance the training efficiency of object detection neural networks and achieve better results in detecting and localizing objects within images or videos.
Evaluate your model using metrics like precision, recall, and mAP to assess its performance.
To ensure the effectiveness of your object detection neural network model, it is essential to evaluate its performance using key metrics such as precision, recall, and mean Average Precision (mAP). Precision measures the accuracy of positive predictions made by the model, while recall evaluates the model’s ability to correctly identify all relevant instances. By calculating these metrics along with mAP, which provides an overall assessment of the model’s performance across different object classes, you can gain valuable insights into the strengths and weaknesses of your neural network and make informed decisions for further optimization and refinement.