Natural Language Processing Neural Network: Revolutionizing Language Understanding
In the realm of artificial intelligence, one groundbreaking technology that has revolutionized the field of natural language processing (NLP) is the neural network. By mimicking the human brain’s ability to process and understand language, NLP neural networks have opened up new possibilities for machines to comprehend and generate human language with remarkable accuracy and fluency.
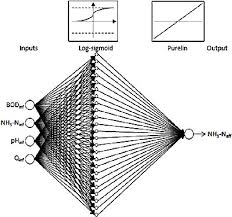
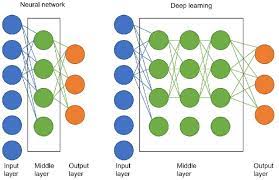
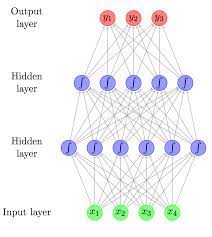
At its core, a neural network is a complex system of interconnected nodes or “neurons” that work together to process and analyze data. In the context of NLP, these networks are designed to handle textual data, such as sentences or documents, and extract meaningful information from them.
The power of NLP neural networks lies in their ability to learn patterns and relationships within language. Through a process called training, these networks are exposed to vast amounts of labeled text data, allowing them to recognize recurring patterns and make connections between words, phrases, and concepts.
One popular type of NLP neural network is the recurrent neural network (RNN). RNNs excel at processing sequential data by maintaining an internal memory that captures context from previous inputs. This memory allows RNNs to handle tasks like machine translation, sentiment analysis, text generation, and speech recognition with impressive accuracy.
Another significant advancement in NLP neural networks is the introduction of transformer models. Transformers leverage attention mechanisms that allow them to focus on different parts of a sentence or document simultaneously. This parallel processing capability enables transformers to capture long-range dependencies within text efficiently. The most notable example of a transformer model is the state-of-the-art language model known as GPT-3 (Generative Pre-trained Transformer 3), which has demonstrated remarkable proficiency in various language tasks.
The impact of NLP neural networks can be observed across various domains. In customer service applications, chatbots powered by these networks can provide instant responses by understanding user queries accurately. In healthcare, NLP models can analyze medical records and assist in diagnosing diseases or extracting valuable insights from research papers. In the legal field, these networks can aid in document analysis, contract review, and legal research.
However, it is important to note that NLP neural networks are not without challenges. One significant issue is the need for massive amounts of labeled training data to achieve optimal performance. Additionally, biases present in the training data can inadvertently be learned and perpetuated by these models, leading to biased outputs. Researchers are actively working on mitigating these challenges and ensuring fairness and inclusivity in NLP models.
As NLP neural networks continue to evolve, we can expect even more sophisticated language understanding capabilities. Advancements like zero-shot learning (where models can perform tasks they were not explicitly trained on) and few-shot learning (where models require minimal examples to learn new tasks) hold immense potential for expanding the versatility of NLP systems.
In conclusion, natural language processing neural networks have transformed the way machines comprehend and generate human language. With their ability to learn patterns and relationships within text data, these networks have propelled advancements in various industries. As researchers push the boundaries of NLP technology further, we can anticipate a future where machines effortlessly understand and communicate with us in a truly human-like manner.
8 Advantages of Natural Language Processing Neural Networks: A Comprehensive Overview
- Increased accuracy in text analysis, as the neural networks can learn from previous data and adjust accordingly.
- Faster processing of natural language data due to the ability of neural networks to parallelize tasks.
- Improved understanding of context and sentiment through deep learning techniques.
- Automated summarization and extraction of key information from large bodies of text.
- Automated generation of responses based on user input, such as in chatbots or virtual assistants.
- Improved accuracy in machine translation due to the ability for neural networks to recognize patterns across languages more effectively than traditional methods like statistical machine translation (SMT).
- Enhanced speech recognition capabilities with improved accuracy for recognizing words spoken in different accents or dialects, as well as recognizing complex sentences with multiple clauses or phrases spoken at once by a single speaker (e.g., “I want to order a pizza”).
- Improved image captioning capabilities through better understanding of visual content, such as generating captions that accurately describe what is seen in an image or video clip without needing additional input from humans
7 Drawbacks of Natural Language Processing Neural Networks
- High Cost
- Limited Understanding
- No Human Insight
- Difficulty Debugging
- Unpredictable Results
- Vulnerability To Attacks
- Tendency To Overfit Data
Increased accuracy in text analysis, as the neural networks can learn from previous data and adjust accordingly.
Natural Language Processing Neural Networks: Enhancing Text Analysis with Unprecedented Accuracy
In the ever-expanding world of natural language processing (NLP), one remarkable advantage of neural networks is their ability to significantly improve the accuracy of text analysis. By leveraging the power of machine learning, these NLP neural networks can learn from previous data and adjust their understanding accordingly, leading to more precise and reliable results.
Traditionally, text analysis tasks such as sentiment analysis, named entity recognition, and topic classification relied on rule-based approaches that required explicit instructions and predefined patterns. While these methods were effective to a certain extent, they often struggled with complex language structures, context-dependent meanings, and evolving linguistic patterns.
The introduction of NLP neural networks has changed the game. These networks can be trained on vast amounts of labeled text data, allowing them to capture intricate relationships between words and phrases. By analyzing this data and learning from it iteratively, neural networks can adapt their understanding based on the patterns they discover.
This adaptability is what sets NLP neural networks apart. Unlike rule-based systems that rely on fixed instructions, neural networks can dynamically adjust their parameters to better align with the intricacies of language usage. This enables them to handle various linguistic nuances such as sarcasm, idiomatic expressions, and context-specific meanings.
Moreover, NLP neural networks excel at contextual understanding. They can take into account not only individual words but also the surrounding words and phrases to derive accurate interpretations. By considering the broader context in which a word or phrase appears, these networks are better equipped to comprehend ambiguous statements or resolve syntactic ambiguities.
The increased accuracy in text analysis achieved by NLP neural networks has paved the way for numerous practical applications across industries. In customer service, companies can utilize sentiment analysis powered by these networks to gauge customer feedback accurately. In finance, these models can analyze news articles or social media posts for sentiment trends that impact investment decisions. In cybersecurity, they can identify and categorize potentially malicious text content with higher precision.
However, it is essential to acknowledge that the accuracy of NLP neural networks heavily relies on the quality and diversity of the training data. Biases present in the training data can also influence the results obtained by these models. Therefore, continuous efforts are being made to improve data collection practices and minimize bias to ensure fair and unbiased text analysis.
In conclusion, NLP neural networks have revolutionized text analysis by significantly increasing accuracy through their ability to learn from previous data. By leveraging machine learning techniques, these networks adapt their understanding of language dynamically, accounting for context and linguistic nuances. As we continue to refine these models and address challenges related to bias, NLP neural networks will play an increasingly vital role in unlocking deeper insights from textual data across various domains.
Faster processing of natural language data due to the ability of neural networks to parallelize tasks.
Natural Language Processing Neural Networks: Accelerating Language Data Processing
In the realm of natural language processing (NLP), one significant advantage of neural networks is their ability to parallelize tasks, resulting in faster processing of natural language data. This capability has revolutionized the way machines handle and analyze large volumes of textual information, enabling quicker and more efficient language understanding.
Traditional approaches to NLP often relied on sequential processing, where each task had to be executed one after the other. This sequential nature posed limitations on the speed at which data could be processed, hindering real-time applications and scalability. However, neural networks have overcome this limitation by leveraging parallel computing.
Neural networks are composed of multiple interconnected nodes or “neurons” that work simultaneously to process and analyze data. This parallelization allows for the distribution of computational workload across multiple cores or even GPUs, enabling faster execution of NLP tasks.
By dividing a large dataset into smaller subsets, these subsets can be processed independently in parallel by different parts of the neural network. This parallelization significantly reduces the overall processing time required for analyzing natural language data.
The ability to parallelize tasks has profound implications for various NLP applications. For instance, in machine translation systems, neural networks can process multiple sentences simultaneously, allowing for faster translation outputs. Similarly, in sentiment analysis applications that deal with large volumes of social media data, neural networks can swiftly classify sentiments across multiple posts concurrently.
Parallelization also enhances real-time applications such as chatbots or voice assistants. These systems need to process user queries or commands swiftly to provide instant responses. By utilizing neural networks’ parallel computing capabilities, these applications can handle numerous user interactions simultaneously without sacrificing performance.
Furthermore, the ability to parallelize tasks enables scaling up NLP models efficiently. As datasets grow larger and computational demands increase, traditional sequential approaches struggle to keep up with processing requirements. Neural networks’ parallelization allows for seamless scaling by distributing the workload across multiple processing units, ensuring efficient processing even with massive amounts of data.
However, it is important to note that the degree of parallelization achievable depends on various factors, such as the architecture of the neural network and the available computational resources. Additionally, not all NLP tasks can be parallelized to the same extent. Some tasks inherently require sequential processing due to dependencies between elements in the data.
In conclusion, one of the significant advantages of natural language processing neural networks is their ability to parallelize tasks, resulting in faster processing of natural language data. This parallel computing capability has accelerated various NLP applications, enabling real-time interactions and efficient analysis of large datasets. As researchers continue to advance neural network architectures and optimize parallelization techniques, we can anticipate even greater speed and efficiency in language data processing, opening doors to new possibilities in the field of NLP.
Improved understanding of context and sentiment through deep learning techniques.
Improved Understanding of Context and Sentiment: Unleashing the Power of Deep Learning in Natural Language Processing
In the realm of natural language processing (NLP), one significant advantage offered by neural networks is their ability to enhance the understanding of context and sentiment within text. Through the application of deep learning techniques, NLP neural networks have unlocked new possibilities for machines to grasp the intricacies of language, leading to more accurate interpretations and insightful analyses.
Context plays a crucial role in language comprehension. Words and phrases acquire meaning based on the surrounding words, sentences, and broader context. NLP neural networks excel at capturing these contextual nuances through their capacity for deep learning. By processing large volumes of labeled data, these networks learn to recognize patterns and relationships that exist within language structures.
Deep learning techniques, such as recurrent neural networks (RNNs) and transformers, enable NLP models to maintain an internal memory that captures context from previous inputs. This memory allows them to understand the flow of information within a sentence or document, making connections between words and phrases that contribute to a holistic understanding of the text.
With improved context understanding, NLP models can accurately interpret ambiguous statements or resolve word sense disambiguation problems. For example, consider a sentence like “She saw a bat.” Without proper context, it could be interpreted as either witnessing a flying mammal or using a sports equipment tool. However, by leveraging deep learning techniques, NLP models can discern the intended meaning based on surrounding words or broader textual cues.
Sentiment analysis is another area where deep learning has made significant strides in NLP. Sentiment analysis involves determining the emotional tone behind a piece of text—whether it is positive, negative, or neutral. Neural networks trained using deep learning techniques can grasp subtle linguistic nuances that indicate sentiment more effectively than traditional rule-based approaches.
Through exposure to vast amounts of labeled sentiment data during training, NLP neural networks learn to recognize sentiment-bearing words, phrases, and contextual cues. This enables them to accurately classify sentiment across a wide range of texts, from social media posts and customer reviews to news articles and product descriptions. The improved understanding of sentiment allows businesses to gain valuable insights into public opinion, customer satisfaction, and brand perception.
While deep learning techniques have significantly improved context understanding and sentiment analysis in NLP, challenges remain. Fine-tuning models to handle specific domains or languages effectively requires substantial labeled data and expertise. Additionally, biases present in training data can impact the accuracy and fairness of sentiment analysis results. Researchers are actively working on addressing these challenges to ensure more robust and unbiased NLP models.
In conclusion, the integration of deep learning techniques within NLP neural networks has propelled the field forward by enhancing the understanding of context and sentiment in textual data. By capturing contextual nuances through deep learning architectures like RNNs and transformers, these models can accurately interpret language structures and discern the emotional tone behind text. As research continues to advance in this area, we can expect further improvements in context-aware applications such as machine translation, chatbots, recommendation systems, and more nuanced sentiment analysis tools that better align with human understanding.
Automated summarization and extraction of key information from large bodies of text.
Automated Summarization and Extraction: Unleashing the Power of NLP Neural Networks
In today’s fast-paced world, where information overload is a constant challenge, extracting key insights and summarizing large bodies of text can be a time-consuming and daunting task. However, thanks to the advancements in Natural Language Processing (NLP) neural networks, automated summarization and extraction of essential information have become more efficient than ever before.
NLP neural networks have the remarkable ability to process vast amounts of textual data and distill it into concise summaries that capture the essence of the original content. By analyzing the structure, context, and meaning of sentences and paragraphs, these networks can identify crucial information, such as main ideas, important facts, or key arguments.
One popular technique employed by NLP neural networks for automated summarization is called “extractive summarization.” Instead of generating new sentences, extractive summarization selects relevant sentences from the original text and combines them to create a summary. This approach ensures that the summary remains faithful to the source material while condensing it into a more digestible format.
The benefits of automated summarization are numerous. For researchers and academics faced with an overwhelming amount of scholarly articles or research papers, NLP-powered summarization can save valuable time by providing condensed versions that highlight essential findings or arguments. Journalists can utilize these systems to quickly summarize news articles or press releases, enabling them to stay on top of current events efficiently.
Businesses also stand to gain from automated summarization. Analysts poring over lengthy reports or market research documents can use NLP neural networks to extract key data points or trends without having to read through every word. This enables faster decision-making processes based on relevant information.
Moreover, automated extraction goes beyond just creating summaries; it allows for pinpointing specific pieces of information within a document. By leveraging named entity recognition and other techniques, NLP neural networks can identify names, dates, locations, and other crucial details from text. This capability has significant applications in areas such as information retrieval, data mining, and knowledge management.
However, it’s important to note that automated summarization and extraction are still evolving fields. Challenges remain, such as handling ambiguous language, dealing with domain-specific terminology, and ensuring the accuracy of extracted information. Researchers are actively working on addressing these issues to enhance the reliability and precision of NLP-powered systems.
In conclusion, the automated summarization and extraction capabilities offered by NLP neural networks have revolutionized information processing. By condensing large bodies of text into concise summaries and extracting key insights automatically, these systems empower individuals and organizations to navigate through vast amounts of information more effectively. As technology continues to advance, we can expect even more sophisticated solutions that will streamline our access to knowledge in an increasingly data-driven world.
Automated generation of responses based on user input, such as in chatbots or virtual assistants.
Automated Generation of Responses: Empowering Chatbots and Virtual Assistants
In the realm of natural language processing (NLP), one remarkable advantage of neural networks is their ability to automate the generation of responses based on user input. This capability has paved the way for the development of highly interactive chatbots and virtual assistants that can engage in meaningful conversations with users, providing instant and personalized assistance.
Gone are the days when chatbots would provide generic and scripted responses. With NLP neural networks, these conversational agents have become more sophisticated, understanding context, nuances, and even emotions embedded within user queries. By leveraging vast amounts of training data, these networks can generate responses that are not only accurate but also human-like in their tone and style.
The automated generation of responses has significant implications across various domains. In customer service applications, chatbots equipped with NLP neural networks can handle a wide range of user inquiries efficiently. They can provide instant answers to frequently asked questions, guide users through troubleshooting processes, or even assist in making product recommendations based on individual preferences.
Virtual assistants powered by NLP neural networks have also become indispensable companions in our daily lives. These intelligent agents can help us manage our schedules, set reminders, answer general knowledge questions, play music or podcasts, and even control smart home devices – all through natural language interactions. By automating response generation, virtual assistants have become invaluable tools for increasing productivity and simplifying everyday tasks.
The benefits extend beyond mere convenience. The automated response generation capability allows chatbots and virtual assistants to handle a large volume of user interactions simultaneously without compromising quality. This scalability makes them ideal for businesses dealing with high customer engagement levels or organizations aiming to provide 24/7 support services.
Furthermore, NLP neural networks enable chatbots and virtual assistants to continuously improve their performance over time. Through a process called reinforcement learning, these systems receive feedback from users regarding the accuracy and relevance of their responses. This feedback loop allows the neural networks to adapt and fine-tune their models, ensuring that subsequent interactions yield even better outcomes.
While automated response generation brings immense value, it is crucial to strike a balance between automation and human intervention. In complex or sensitive situations, the involvement of human operators may still be necessary to ensure accurate and empathetic responses. Striving for this balance is essential to provide users with a seamless experience that combines the efficiency of automation with the empathy and understanding of human interaction.
In conclusion, the automated generation of responses powered by NLP neural networks has transformed chatbots and virtual assistants into powerful conversational agents. Their ability to understand user input and generate contextually appropriate and personalized responses has revolutionized customer service, personal productivity, and assistance in various domains. As these technologies continue to advance, we can anticipate even more natural and engaging interactions with our digital companions in the future.
Improved accuracy in machine translation due to the ability for neural networks to recognize patterns across languages more effectively than traditional methods like statistical machine translation (SMT).
Improved Accuracy in Machine Translation: The Power of Natural Language Processing Neural Networks
Machine translation has come a long way in breaking down language barriers and facilitating global communication. One significant advancement that has greatly enhanced the accuracy of machine translation is the use of natural language processing (NLP) neural networks. These networks have proven to be highly effective in recognizing patterns across languages, surpassing traditional methods like statistical machine translation (SMT).
One key advantage of NLP neural networks is their ability to capture and understand the intricate nuances of language. Traditional approaches like SMT relied heavily on statistical models that mapped phrases from one language to another based on probabilities derived from large bilingual corpora. While SMT provided a foundation for machine translation, it often struggled with handling complex sentence structures, idiomatic expressions, and context-dependent translations.
In contrast, NLP neural networks excel at recognizing patterns and relationships within language data. By training on vast amounts of multilingual text, these networks acquire a deep understanding of syntax, grammar, and semantics across languages. This enables them to generate more accurate translations by capturing the contextual meaning behind words and phrases.
The strength of NLP neural networks lies in their ability to learn from diverse examples and generalize patterns across languages effectively. Unlike SMT models that rely on pre-defined rules or alignments between source and target languages, neural networks can adapt dynamically to different language pairs without explicitly programming language-specific rules. This flexibility allows them to handle a wide range of translation tasks with improved accuracy.
Furthermore, NLP neural networks have shown remarkable proficiency in handling rare or unseen words or phrases during translation. Traditional methods often struggled with out-of-vocabulary terms or low-frequency words that were not present in their training data. Neural networks can overcome this limitation by leveraging distributed word representations (word embeddings) that capture semantic similarities between words regardless of frequency or rarity.
With their enhanced pattern recognition capabilities and ability to capture context-dependent translations, NLP neural networks have significantly improved the accuracy of machine translation. They have paved the way for more fluent and natural translations, enabling individuals and businesses to communicate effectively across language barriers.
As researchers continue to refine NLP models and explore innovative techniques like incorporating contextual information through transformer architectures, we can expect even greater improvements in the accuracy and quality of machine translation. The future holds immense potential for bridging language gaps and fostering global understanding, all thanks to the power of natural language processing neural networks.
Enhanced speech recognition capabilities with improved accuracy for recognizing words spoken in different accents or dialects, as well as recognizing complex sentences with multiple clauses or phrases spoken at once by a single speaker (e.g., “I want to order a pizza”).
Enhanced Speech Recognition with NLP Neural Networks: Breaking Language Barriers
One remarkable advantage of natural language processing (NLP) neural networks is their ability to enhance speech recognition capabilities. With improved accuracy, these networks can effectively recognize words spoken in different accents or dialects, as well as decipher complex sentences with multiple clauses or phrases spoken at once by a single speaker. This breakthrough has the potential to break down language barriers and revolutionize the way we interact with technology.
Accents and dialects add richness and diversity to our global linguistic landscape, but they can pose challenges for traditional speech recognition systems. NLP neural networks have overcome this hurdle by training on vast amounts of diverse speech data, allowing them to learn the intricacies of various accents and dialects. As a result, these networks can now accurately transcribe spoken words regardless of regional variations in pronunciation or intonation.
Moreover, NLP neural networks excel at understanding complex sentences that contain multiple clauses or phrases spoken consecutively. In the past, recognizing such sentences accurately was a daunting task for speech recognition systems. However, with the power of neural networks, machines can now parse and comprehend intricate sentence structures seamlessly. For instance, a sentence like “I want to order a pizza” may seem simple to humans but involves multiple clauses and phrases that need to be correctly identified by machines.
The impact of enhanced speech recognition goes far beyond convenience; it opens up new possibilities for communication and accessibility. Individuals with different accents or dialects can now interact effortlessly with voice-enabled devices, without having to modify their speech patterns or compromise on accuracy. This inclusivity extends to various industries such as customer service, where automated voice assistants equipped with NLP neural networks can understand diverse customer queries more accurately than ever before.
Additionally, improved speech recognition capabilities benefit fields like transcription services, language learning applications, and even law enforcement agencies that rely on accurate voice-to-text conversions for investigations or evidence gathering. The increased accuracy of NLP neural networks ensures that critical information is captured precisely, even in situations where multiple clauses or phrases are spoken rapidly.
While NLP neural networks have made significant strides in enhancing speech recognition, challenges still exist. Variations in accents and dialects are vast and ever-evolving, making it crucial to continuously train and refine these networks with diverse data sources. Additionally, ensuring fairness and inclusivity in speech recognition systems remains an ongoing research focus to prevent biases from influencing the accuracy of transcriptions.
In conclusion, the enhanced speech recognition capabilities provided by NLP neural networks have revolutionized our ability to communicate with machines effectively. By accurately recognizing words spoken in different accents or dialects and deciphering complex sentences with multiple clauses or phrases, these networks have broken down language barriers and opened up new possibilities for accessibility and inclusivity. As research continues to advance this technology, we can look forward to a future where seamless communication between humans and machines transcends linguistic differences.
Improved image captioning capabilities through better understanding of visual content, such as generating captions that accurately describe what is seen in an image or video clip without needing additional input from humans
Improved Image Captioning: A Breakthrough in Visual Understanding with NLP Neural Networks
Natural Language Processing (NLP) neural networks have not only revolutionized language understanding but have also made significant strides in enhancing the comprehension of visual content. One remarkable pro of NLP neural networks is their ability to generate accurate and meaningful captions that describe the contents of images or video clips without any additional input from humans.
Traditionally, generating captions for images has been a challenging task for machines. However, with the advancements in NLP neural networks, machines can now better understand the visual elements present in an image and generate captions that accurately depict what is seen.
By leveraging the power of deep learning and large-scale training data, NLP neural networks can learn to associate words and phrases with specific visual features extracted from images. These networks analyze various aspects such as objects, scenes, colors, shapes, and spatial relationships within an image to generate descriptive captions automatically.
This breakthrough in image captioning has numerous practical applications. In the field of accessibility, it enables visually impaired individuals to gain a better understanding of visual content shared online. By generating detailed descriptions of images or video clips, NLP neural networks allow these individuals to access information that was previously inaccessible to them.
Moreover, improved image captioning capabilities have also found applications in content creation and organization. Social media platforms can automatically generate relevant captions for user-uploaded images, making it easier for users to search and categorize their visual content. Additionally, news agencies and media organizations can utilize this technology to automatically caption images or videos in real-time during broadcasts or live events.
Furthermore, this advancement has implications for industries such as e-commerce and advertising. Accurate image captions enable better product descriptions by highlighting key features or attributes visible in product images. This enhances the overall customer experience by providing more detailed information about products without relying solely on manual input.
Despite these significant advancements, challenges still exist in perfecting image captioning with NLP neural networks. Ensuring that the generated captions are contextually accurate and free from biases remains an ongoing area of research. Additionally, handling complex scenes or abstract concepts within images can pose difficulties for the networks, requiring further improvements in training methodologies.
Nonetheless, the improved image captioning capabilities offered by NLP neural networks hold immense potential for enhancing visual understanding and accessibility across various domains. As researchers continue to refine these models and explore new techniques, we can anticipate even more accurate and nuanced descriptions of visual content in the future.
In conclusion, NLP neural networks have revolutionized image captioning by enabling machines to better understand and describe visual content. This breakthrough has opened up new possibilities for accessibility, content organization, e-commerce, and beyond. With continued advancements in this field, we can look forward to a future where machines effortlessly generate captions that accurately depict what is seen in images or video clips, enriching our understanding of the visual world around us.
High Cost
High Cost: A Challenge in Natural Language Processing Neural Networks
While natural language processing (NLP) neural networks have revolutionized the field of language understanding, they do come with certain challenges. One significant drawback is the high cost associated with developing and maintaining these powerful systems.
NLP neural networks demand vast amounts of data for training purposes. To achieve optimal performance, models require extensive labeled datasets that accurately represent the target language and domain. Acquiring and curating such datasets can be a time-consuming and costly endeavor. Additionally, the process of labeling data often requires human annotators, further adding to the expenses.
Moreover, training NLP neural networks requires substantial computing power. Complex architectures like recurrent neural networks (RNNs) or transformer models involve millions or even billions of parameters that need to be fine-tuned during training. This necessitates access to high-performance hardware, such as graphics processing units (GPUs) or specialized tensor processing units (TPUs), which can be expensive to procure and maintain.
The cost implications extend beyond development to deployment and maintenance as well. Once trained, NLP neural networks need continuous monitoring, updates, and improvements to adapt to evolving language patterns and user needs. This ongoing maintenance requires dedicated resources, including skilled professionals who can fine-tune models or address issues that arise during real-world usage.
For smaller organizations or individuals with limited budgets, these high costs may pose a significant barrier to entry into the world of NLP. The financial investment required may outweigh the potential benefits for some projects or applications.
However, it is worth noting that efforts are being made to address this challenge. Open-source frameworks and pre-trained models have emerged in recent years, making it more accessible for developers to leverage existing resources without starting from scratch. Cloud-based services also offer more affordable options for utilizing NLP capabilities without heavy upfront investments in infrastructure.
As technology continues to advance and research progresses in this field, we can hope for cost-effective solutions that democratize access to NLP neural networks. Innovations such as transfer learning and federated learning show promise in reducing the data and computational requirements, making these systems more accessible to a wider range of users.
In conclusion, the high cost associated with developing and maintaining NLP neural networks is a significant con that cannot be overlooked. However, with advancements in open-source frameworks and alternative learning approaches, there is potential for cost-effective solutions that will make these powerful language processing capabilities more accessible to all.
Limited Understanding
Limited Understanding: The Achilles’ Heel of Natural Language Processing Neural Networks
While natural language processing (NLP) neural networks have made remarkable strides in language understanding, they still face a significant limitation: their inability to comprehend new words or phrases that they haven’t been explicitly trained on. This limitation poses a challenge when it comes to handling evolving language, specialized terminology, or domain-specific jargon.
NLP neural networks learn from vast amounts of labeled data during their training phase. They capture patterns and relationships within the text data to develop a model of language understanding. However, this means that their knowledge is restricted to the vocabulary and linguistic structures present in the training data.
When faced with unfamiliar words or phrases, these networks may struggle to provide accurate interpretations or generate meaningful responses. For example, if a network trained on general news articles encounters technical terms from the field of medicine, it may fail to comprehend their specific meanings and context.
This limited understanding can have practical implications in various applications. In customer support chatbots, for instance, users may encounter frustration if the bot fails to comprehend industry-specific terms or acronyms related to their queries. In machine translation systems, rare or domain-specific words can be challenging for the system to accurately translate without proper training.
Addressing this limitation requires continuous efforts from researchers and developers. One approach involves expanding the training data by incorporating more diverse sources that cover a wider range of vocabulary and topics. Another technique is leveraging transfer learning, where models pretrained on large-scale datasets are fine-tuned on specific tasks or domains using smaller labeled datasets.
Furthermore, ongoing research focuses on developing methods that enable neural networks to generalize better and infer meaning from context when encountering unfamiliar words. Incorporating external knowledge sources such as ontologies or semantic databases could also assist in expanding their understanding beyond training data limitations.
As NLP neural networks continue to advance, it is essential for developers and researchers to address this con effectively. By improving their ability to comprehend new words and phrases, these networks can become even more versatile and reliable in understanding and processing human language.
While the limited understanding of NLP neural networks remains a challenge, it is crucial to acknowledge the immense progress they have made in breaking down language barriers. As technology evolves, we can look forward to more sophisticated solutions that bridge this gap, enabling machines to understand and communicate with us more effectively, regardless of the ever-changing nature of human language.
No Human Insight
No Human Insight: The Limitation of Natural Language Processing Neural Networks
While natural language processing (NLP) neural networks have made remarkable strides in understanding and generating human language, they do possess certain limitations. One notable drawback is their lack of human insight, which can result in the missing of subtle nuances that humans effortlessly grasp during conversations or while reading texts.
Unlike humans, neural networks lack intuition – the innate ability to understand context, emotions, and cultural references that shape our interpretation of language. This limitation becomes apparent when dealing with sarcasm, irony, wordplay, or other forms of linguistic subtleties that rely heavily on context and shared knowledge.
Neural networks operate on statistical patterns learned from vast amounts of training data. They excel at recognizing common patterns and making predictions based on statistical probabilities. However, they struggle with grasping the underlying meaning behind words or phrases that may deviate from these patterns.
This limitation can have consequences in various applications. For instance, in sentiment analysis tasks where determining the sentiment behind a piece of text is crucial, NLP neural networks might misinterpret sarcastic remarks as genuine expressions. Similarly, in customer service chatbots or virtual assistants, these systems might fail to pick up on subtle cues and provide appropriate responses.
Furthermore, cultural differences play a significant role in language understanding. Neural networks trained on specific datasets might struggle to comprehend idioms or references unique to a particular culture or region. This can lead to inaccurate translations or misinterpretations when dealing with multilingual tasks.
Addressing this limitation requires a combination of techniques and approaches. Researchers are actively exploring ways to incorporate contextual information into NLP models by leveraging external knowledge sources such as encyclopedias or leveraging pre-trained language models like BERT (Bidirectional Encoder Representations from Transformers). These efforts aim to enhance the comprehension capabilities of neural networks by providing them with a broader context for interpretation.
While NLP neural networks have undoubtedly enhanced language processing capabilities, it is essential to acknowledge their limitations. The absence of human insight poses challenges in accurately capturing the nuances and subtleties that are inherent in human communication. As researchers continue to push the boundaries of NLP technology, finding ways to bridge this gap between statistical patterns and human intuition will be a key focus, leading to more robust and comprehensive language understanding systems.
Difficulty Debugging
Difficulty Debugging: Unraveling the Complexity of Neural Networks
While natural language processing neural networks have brought unprecedented advancements in language understanding, they are not without their challenges. One significant drawback is the difficulty in debugging these intricate systems. The complex nature of neural networks, with their numerous layers and components, can pose a formidable obstacle for developers when it comes to identifying errors or making changes swiftly and efficiently.
Neural networks consist of interconnected nodes that process and analyze data. Each layer within the network performs specific operations on the input data, gradually transforming it into meaningful output. However, this intricate structure can make it challenging to pinpoint where exactly an error or issue may arise.
When debugging a neural network, developers often encounter several hurdles. Firstly, the sheer number of layers and connections makes it difficult to trace the flow of information and understand how inputs are transformed at each stage. This complexity can lead to difficulties in identifying which specific layer or component is causing the problem.
Furthermore, neural networks rely heavily on mathematical operations and optimization algorithms during training. Any miscalculations or errors in these calculations can have cascading effects throughout the network, making it even more challenging to isolate and rectify issues.
Additionally, debugging becomes more demanding as neural networks grow larger and more sophisticated. Deep learning architectures, such as convolutional neural networks (CNNs) or recurrent neural networks (RNNs), amplify this complexity further. The intricate interactions between layers and the high dimensionality of data make it arduous to understand how different parts of the network contribute to its overall behavior.
Moreover, debugging becomes particularly cumbersome when dealing with models that have been pre-trained on vast amounts of data. These models often incorporate numerous parameters that have been fine-tuned during training processes. Identifying which parameters are causing issues or need adjustment becomes a daunting task due to their sheer volume.
Despite these challenges, researchers and developers are actively working towards improving debugging techniques for neural networks. Tools and methodologies are being developed to visualize the inner workings of networks, allowing for better insights into their behavior. Additionally, techniques like gradient-based attribution methods are being explored to understand how changes in specific components affect the network’s output.
In conclusion, while natural language processing neural networks have revolutionized language understanding, they present challenges in terms of debugging. The intricate structure and numerous components within these networks make it difficult for developers to quickly and efficiently identify errors or make changes. However, ongoing research and advancements in debugging techniques hold promise for mitigating these difficulties and enhancing the overall efficiency and reliability of neural networks in the future.
Unpredictable Results
Natural language processing neural networks are powerful tools that can be used to process and understand natural language. However, they can also produce unpredictable results due to their complexity and lack of transparency as to how decisions are made internally within the system.
Neural networks are composed of interconnected layers of neurons, which process data in a way that mimics the human brain. This means that they can learn from experience and adapt their behavior as needed. However, this also means that it is difficult to predict what results will be produced by a neural network because the network is constantly learning and evolving.
In addition, neural networks lack transparency when it comes to how decisions are made internally within the system. This means that even if someone understands the overall structure of a neural network, they may not be able to understand why certain decisions were made or why certain results were produced. This lack of transparency can lead to unpredictable results that may not make sense or may not be desirable.
Overall, natural language processing neural networks are powerful tools but due to their complexity and lack of transparency as to how decisions are made internally within the system, they can produce unpredictable results. It is important for those using these systems to understand these risks so that they can make informed decisions about using them in their applications.
Vulnerability To Attacks
Vulnerability to Attacks: The Achilles’ Heel of Natural Language Processing Neural Networks
While natural language processing (NLP) neural networks have revolutionized language understanding, they are not impervious to vulnerabilities. One significant con of these networks is their susceptibility to attacks, particularly in the form of adversarial examples.
Adversarial examples refer to carefully crafted inputs that are designed to deceive neural networks into producing incorrect outputs or misclassifying data. These inputs can be as subtle as imperceptible perturbations added to an input text or image. What makes this issue concerning is that these adversarial attacks can fool the neural network with high confidence levels, making it difficult for humans or traditional security measures like firewalls and antivirus software to detect them easily.
The vulnerability of NLP neural networks to adversarial attacks raises concerns in various domains where accurate and reliable outputs are crucial. For instance, in the field of cybersecurity, malicious actors could exploit these vulnerabilities to bypass security systems that rely on NLP models for threat detection or malware analysis. Similarly, in autonomous vehicles that utilize NLP for voice commands or natural language interaction, adversarial attacks could potentially manipulate the system’s behavior and compromise safety.
Addressing this vulnerability is a complex challenge. Researchers are actively exploring techniques such as defensive distillation, which involves training models on both clean and adversarial examples to enhance their robustness against attacks. Adversarial training, where models are trained with intentionally generated adversarial examples, is another approach aimed at improving resilience.
However, achieving complete robustness against adversarial attacks remains an ongoing pursuit. As new attack strategies emerge and adversaries become more sophisticated, it becomes crucial to continually develop effective defense mechanisms and evaluate the security of NLP neural networks.
In conclusion, while NLP neural networks have propelled advancements in language understanding, their vulnerability to adversarial attacks cannot be overlooked. The potential for misclassification or incorrect outputs with high confidence levels poses challenges in domains where reliability is paramount. As the field progresses, it is essential to invest in research and development to enhance the security and resilience of NLP neural networks, ensuring their reliability and trustworthiness in real-world applications.
Tendency To Overfit Data
Tendency to Overfit Data: A Challenge in Natural Language Processing Neural Networks
While natural language processing (NLP) neural networks have made significant strides in understanding and generating human language, they are not without their challenges. One such challenge is the tendency to overfit data, which can lead to poor generalization performance on unseen data sets.
Overfitting occurs when a model becomes too specialized in the training data it has been exposed to. In the context of NLP neural networks, this means that if too much training data is provided, the model may become overly focused on specific patterns and examples within that data. As a result, when faced with new or unseen data, the model may struggle to generalize and provide accurate predictions or interpretations.
The issue of overfitting arises due to the complexity and flexibility of neural networks. These models have a large number of parameters that allow them to learn intricate relationships within the training data. However, this flexibility can also make them highly sensitive to noise or irrelevant patterns present in the training set.
To mitigate overfitting, techniques such as regularization and early stopping are commonly employed. Regularization methods introduce additional constraints during training to prevent excessive specialization on specific examples. Early stopping involves monitoring the model’s performance on a validation set during training and stopping when performance starts to decline.
Another approach is to carefully curate and balance the training data set. By ensuring diversity in terms of topics, styles, and sources, one can reduce the risk of overfitting caused by an abundance of similar examples.
It is important for researchers and developers working with NLP neural networks to be mindful of this challenge and take appropriate steps to address it. Evaluating models on unseen test sets or using cross-validation techniques can provide insights into their generalization capabilities.
Despite its drawbacks, it is worth noting that overfitting is not an inherent flaw in NLP neural networks but rather a consequence of improper training practices or inadequate data representation. As the field of NLP advances, researchers continue to develop novel techniques and architectures that improve generalization performance and reduce overfitting tendencies.
In conclusion, while NLP neural networks have the potential to transform language processing, the challenge of overfitting should be considered. By implementing appropriate regularization techniques, carefully curating training data, and evaluating models on unseen data sets, we can mitigate the impact of overfitting and ensure more robust and reliable NLP systems.