The Power of MNIST Deep Learning in Machine Learning
When it comes to machine learning, the MNIST dataset is a household name. MNIST, short for Modified National Institute of Standards and Technology, is a collection of handwritten digits that has become a benchmark for testing and evaluating various machine learning algorithms, particularly in the field of deep learning.
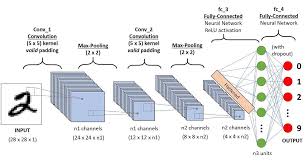
The MNIST dataset consists of 60,000 training images and 10,000 testing images of handwritten digits from 0 to 9. Each image is a grayscale 28×28 pixel square, making it relatively small compared to other datasets. Despite its simplicity, MNIST has proven to be a powerful tool for researchers and practitioners in the machine learning community.
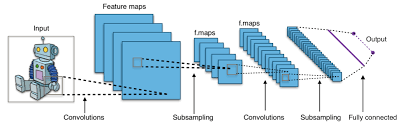
Deep learning models trained on the MNIST dataset have achieved remarkable accuracy rates in digit recognition tasks. Convolutional Neural Networks (CNNs) are commonly used for this purpose due to their ability to effectively capture spatial hierarchies in image data. By leveraging the hierarchical structure of CNNs, researchers have been able to push the boundaries of accuracy on the MNIST dataset.
One of the key advantages of using the MNIST dataset for deep learning research is its accessibility. The dataset is widely available and easy to work with, making it an ideal starting point for beginners looking to dive into the world of deep learning. Additionally, the relatively small size of the images allows for quick experimentation and iteration when developing and fine-tuning deep learning models.
Overall, the MNIST dataset serves as a cornerstone in the field of deep learning, providing researchers with a standardized benchmark for evaluating new algorithms and techniques. Its impact extends beyond just digit recognition tasks, serving as a springboard for advancements in image classification, object detection, and more.
As machine learning continues to evolve at a rapid pace, the lessons learned from working with the MNIST dataset will undoubtedly continue to inform and inspire new breakthroughs in artificial intelligence and beyond.
Understanding the MNIST Dataset: Key FAQs on Deep Learning and Digit Recognition
- What is the MNIST dataset?
- How many images are there in the MNIST dataset?
- Why is the MNIST dataset commonly used in deep learning?
- Which type of neural network is often used for digit recognition on the MNIST dataset?
- What are some common challenges when working with the MNIST dataset?
What is the MNIST dataset?
The MNIST dataset is a widely recognized collection of handwritten digits that serves as a fundamental benchmark in the field of deep learning. Comprising 60,000 training images and 10,000 testing images of digits ranging from 0 to 9, MNIST provides a standardized dataset for evaluating and comparing machine learning algorithms, particularly in the context of digit recognition tasks. Researchers often use convolutional neural networks (CNNs) to achieve high accuracy rates on the MNIST dataset, leveraging its accessibility and simplicity to explore and advance deep learning techniques for image classification and beyond.
How many images are there in the MNIST dataset?
The MNIST dataset, a widely recognized benchmark in machine learning, consists of a total of 70,000 handwritten digit images. This dataset includes 60,000 training images and 10,000 testing images, each depicting digits from 0 to 9 in a grayscale format. Researchers and practitioners often refer to the MNIST dataset for its accessibility and standardized nature, making it an essential resource for evaluating and developing deep learning models, particularly in tasks related to digit recognition.
Why is the MNIST dataset commonly used in deep learning?
The MNIST dataset is commonly used in deep learning for several reasons. Firstly, its simplicity and accessibility make it an ideal starting point for beginners to understand and experiment with deep learning concepts. The dataset’s standardized format of 28×28 pixel grayscale images of handwritten digits allows researchers and practitioners to quickly prototype and test various machine learning algorithms. Additionally, the MNIST dataset serves as a benchmark for evaluating the performance of new models, providing a common ground for comparing different approaches in digit recognition tasks. Overall, the widespread adoption of the MNIST dataset in deep learning can be attributed to its versatility, ease of use, and role as a foundational tool for advancing research in artificial intelligence.
Which type of neural network is often used for digit recognition on the MNIST dataset?
When it comes to digit recognition on the MNIST dataset, Convolutional Neural Networks (CNNs) are often the neural network architecture of choice. CNNs have proven to be highly effective in capturing spatial hierarchies in image data, making them well-suited for tasks like digit recognition where the input consists of pixel values arranged in a grid. By leveraging the convolutional and pooling layers in CNNs, researchers have been able to achieve impressive accuracy rates on the MNIST dataset, solidifying CNNs as a go-to solution for this particular type of image classification task.
What are some common challenges when working with the MNIST dataset?
When working with the MNIST dataset in deep learning, several common challenges may arise. One challenge is overfitting, where the model performs well on the training data but fails to generalize to unseen data. This can be mitigated through techniques like regularization and dropout. Another challenge is handling imbalanced datasets, as some digits may have fewer examples than others, leading to biased model performance. Data preprocessing and augmentation methods can help address this issue. Additionally, selecting an appropriate network architecture and hyperparameters to optimize model performance on the MNIST dataset can be a challenging task that requires careful experimentation and tuning.