Understanding Layers in Convolutional Neural Networks (CNN)
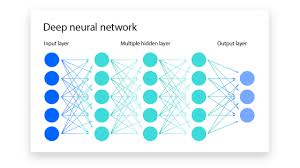
Convolutional Neural Networks (CNNs) have revolutionized the field of computer vision and image recognition. At the core of CNNs are layers, each serving a specific purpose in extracting features from input data.
Input Layer
The input layer receives the raw data, typically an image, and passes it to the next layer for processing.
Convolutional Layer
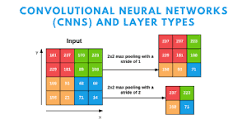
The convolutional layer applies filters to the input data to detect features like edges, textures, and patterns. These filters slide over the input data to create feature maps.
Activation Layer (ReLU)
The activation layer introduces non-linearity into the network by applying an activation function like ReLU (Rectified Linear Unit). This helps CNNs learn complex patterns and relationships in the data.
Pooling Layer
The pooling layer reduces the spatial dimensions of the feature maps while retaining important information. Common pooling techniques include max pooling and average pooling.
Fully Connected Layer
The fully connected layer connects every neuron from the previous layer to every neuron in its own layer. This layer helps in making predictions based on the extracted features.
Output Layer
The output layer produces the final prediction or classification based on the information learned by earlier layers.
In conclusion, understanding the different layers in a CNN is crucial for grasping how these networks process and analyze visual data. Each layer plays a unique role in transforming input data into meaningful outputs, making CNNs powerful tools for tasks like image recognition, object detection, and more.
Understanding the Benefits of CNN Layers: Enhancing Feature Learning and Efficiency
- Layers in CNNs enable hierarchical feature learning, allowing the network to extract complex patterns from input data.
- Different layers like convolutional and pooling layers help in reducing the spatial dimensions of data while preserving important features.
- Activation layers introduce non-linearity, enabling CNNs to learn and model intricate relationships in the data.
- CNN layers are designed for parallel processing, making them efficient for handling large volumes of visual data.
- The use of fully connected layers at the end of CNNs allows for making accurate predictions based on learned features.
- Each layer in a CNN contributes to the network’s ability to perform tasks like image classification, object detection, and semantic segmentation effectively.
Challenges of Layered Architectures in Convolutional Neural Networks
- Increased complexity
- Overfitting
- Computational cost
- Gradient vanishing or exploding
- Interpretability
Layers in CNNs enable hierarchical feature learning, allowing the network to extract complex patterns from input data.
Layers in Convolutional Neural Networks (CNNs) play a crucial role in enabling hierarchical feature learning, which empowers the network to extract intricate and complex patterns from the input data. By organizing the network into layers that progressively analyze and abstract information at different levels of complexity, CNNs can effectively identify and understand patterns within images or other types of data. This hierarchical approach to feature learning enhances the network’s ability to recognize subtle details and relationships, ultimately improving its performance in tasks such as image classification, object detection, and more.
Different layers like convolutional and pooling layers help in reducing the spatial dimensions of data while preserving important features.
One key advantage of using different layers in Convolutional Neural Networks (CNN) such as convolutional and pooling layers is their ability to effectively reduce the spatial dimensions of data while retaining crucial features. The convolutional layers apply filters to detect patterns and features in the input data, while the pooling layers help in downsampling the feature maps, focusing on essential information and discarding redundant details. This process not only helps in managing computational complexity but also ensures that important features are preserved throughout the network, leading to more efficient and accurate data analysis and pattern recognition.
Activation layers introduce non-linearity, enabling CNNs to learn and model intricate relationships in the data.
Activation layers play a crucial role in Convolutional Neural Networks (CNNs) by introducing non-linearity, which allows the network to learn and model complex relationships within the data. By applying activation functions like ReLU (Rectified Linear Unit), CNNs can capture intricate patterns and features that would be challenging to represent with linear functions alone. This non-linear transformation enables CNNs to extract meaningful information from input data, making them highly effective in tasks such as image recognition, object detection, and pattern classification.
CNN layers are designed for parallel processing, making them efficient for handling large volumes of visual data.
CNN layers are designed for parallel processing, making them efficient for handling large volumes of visual data. This parallel processing capability allows CNNs to analyze and extract features from images simultaneously across multiple layers, significantly speeding up the computation process. By leveraging parallelism, CNN layers can efficiently process complex visual data, making them ideal for tasks such as image recognition, object detection, and image classification where large amounts of data need to be processed quickly and accurately.
The use of fully connected layers at the end of CNNs allows for making accurate predictions based on learned features.
The incorporation of fully connected layers at the conclusion of Convolutional Neural Networks (CNNs) is a significant advantage, as it enables the network to generate precise predictions by leveraging the learned features extracted from earlier layers. By connecting every neuron from the preceding layer to every neuron in the fully connected layer, CNNs can effectively analyze and interpret complex patterns within the input data, ultimately enhancing the accuracy and reliability of the network’s output predictions.
Each layer in a CNN contributes to the network’s ability to perform tasks like image classification, object detection, and semantic segmentation effectively.
Each layer in a Convolutional Neural Network (CNN) plays a vital role in enhancing the network’s capacity to excel in tasks such as image classification, object detection, and semantic segmentation. From the input layer that receives raw data to the output layer that generates predictions, each intermediate layer contributes to extracting and learning intricate features from the input data. The convolutional layers detect patterns and structures, the activation layers introduce non-linearity for complex pattern recognition, and the pooling layers reduce spatial dimensions while preserving essential information. Together, these layers work in harmony to empower CNNs to efficiently tackle diverse visual recognition tasks with accuracy and precision.
Increased complexity
Increased complexity is a significant drawback of adding more layers to a Convolutional Neural Network (CNN). As the network grows in depth, the overall complexity also increases, leading to challenges in training and optimization. The deeper the network, the more difficult it becomes to effectively adjust the numerous parameters and prevent issues like overfitting. This heightened complexity can result in longer training times, higher computational requirements, and potential performance degradation if not managed carefully. Balancing the depth of layers in a CNN is crucial to avoid overwhelming the network with unnecessary complexity that hinders its efficiency and effectiveness.
Overfitting
One significant drawback of using many layers in Convolutional Neural Networks (CNNs) is the risk of overfitting. Overfitting occurs when a deep network learns to perform exceptionally well on the training data but struggles to generalize its predictions to unseen data. This phenomenon can lead to reduced accuracy and reliability in real-world applications, as the model may fail to make accurate predictions when faced with new or unfamiliar data. Therefore, striking a balance between model complexity and generalization is crucial in designing effective CNN architectures that can avoid the pitfalls of overfitting.
Computational cost
One significant drawback of using multiple layers in Convolutional Neural Networks (CNNs) is the increased computational cost associated with them. As the number of layers in a CNN grows, so does the demand for computational resources, resulting in longer training times and higher hardware requirements. This can pose a challenge for users with limited computing power or budget constraints, as they may struggle to efficiently train and deploy deep CNN models due to the substantial computational burden imposed by additional layers. The trade-off between model complexity and computational efficiency is a crucial consideration when designing CNN architectures to strike a balance between performance and practical feasibility.
Gradient vanishing or exploding
Gradient vanishing or exploding is a significant con associated with the layers in Convolutional Neural Networks (CNNs). When deeper networks are used, there is a risk of gradients either vanishing, becoming too small to effectively update the network parameters, or exploding, becoming too large and leading to unstable training. This phenomenon can hinder the learning process by making it challenging for the network to converge on optimal solutions. Addressing gradient vanishing or exploding is crucial in designing CNN architectures that can effectively train deep models while maintaining stability and efficiency in the learning process.
Interpretability
Interpretability is a significant con associated with the use of multiple layers in a Convolutional Neural Network (CNN). As the network grows deeper and more complex, understanding and interpreting how decisions are made within the network can become increasingly challenging. This lack of transparency and explainability can hinder the ability to pinpoint exactly why certain predictions are made, potentially limiting trust in the model’s outcomes and making it harder to debug or improve its performance.