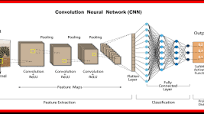
The Importance of Efficient Processing in Deep Neural Networks
Deep neural networks have revolutionized the field of artificial intelligence, enabling machines to perform complex tasks with human-like accuracy. However, the computational demands of training and running deep neural networks can be immense, requiring significant processing power and memory resources.
Efficient processing of deep neural networks is crucial for improving performance, reducing energy consumption, and enabling real-time applications. Here are some key strategies for optimizing the processing of deep neural networks:
Model Optimization
One way to improve efficiency is by optimizing the architecture of the neural network model. This involves reducing the number of parameters, layers, and operations while maintaining or even improving performance. Techniques such as pruning, quantization, and compact network design can help achieve this goal.
Hardware Acceleration
Utilizing specialized hardware accelerators, such as GPUs (Graphics Processing Units) or TPUs (Tensor Processing Units), can significantly speed up the training and inference processes of deep neural networks. These accelerators are designed to handle matrix operations efficiently, which are common in neural network computations.
Parallel Processing
Parallel processing techniques can be employed to distribute the workload across multiple processors or devices, enabling faster computation of neural network operations. Techniques like data parallelism and model parallelism can be used to leverage the power of parallel computing architectures.
Pruning and Quantization
Pruning involves removing unnecessary connections or parameters from a trained model, reducing its size without compromising performance. Quantization involves representing weights and activations with lower precision data types, such as 8-bit integers, to reduce memory usage and computational costs.
Transfer Learning
Transfer learning allows leveraging pre-trained models on similar tasks to accelerate training on new tasks with limited data. By fine-tuning a pre-trained model instead of training from scratch, computational resources can be saved while achieving good performance on new tasks.
In conclusion, efficient processing of deep neural networks is essential for unlocking their full potential in various applications. By implementing optimization techniques such as model pruning, hardware acceleration, parallel processing, and transfer learning, we can make deep learning more accessible and sustainable for a wide range of use cases.
8 Benefits of Efficient Deep Neural Network Processing: From Faster Computation to Increased Accuracy
- Improved performance
- Faster computation
- Reduced energy consumption
- Real-time applications
- Optimized resource utilization
- Enhanced scalability
- Cost-effective solutions
- Increased accuracy
Challenges in Efficient Deep Neural Network Processing: Expertise, Trade-offs, Costs, and Accuracy Concerns
- Complex implementation and tuning of optimization techniques may require specialized expertise.
- Optimizing deep neural networks for efficiency can sometimes lead to a trade-off in model performance.
- Hardware accelerators and parallel processing solutions can be costly to implement and maintain.
- Pruning and quantization techniques may introduce some level of information loss, affecting the accuracy of the model.
Improved performance
Efficient processing of deep neural networks leads to improved performance by enabling faster training and inference times, as well as enhancing the overall accuracy and reliability of the models. By optimizing computational resources and reducing processing overhead, deep neural networks can deliver more precise predictions and insights in a timely manner, making them more effective in various applications such as image recognition, natural language processing, and autonomous driving. This enhanced performance not only boosts productivity but also enhances user experience by providing quicker and more accurate results.
Faster computation
One significant advantage of efficient processing in deep neural networks is faster computation. By optimizing the architecture, utilizing hardware accelerators, implementing parallel processing techniques, and employing strategies like pruning and quantization, deep neural networks can perform computations more quickly. This speed improvement not only enhances the overall performance of the neural network but also enables real-time applications and reduces energy consumption, making deep learning more practical and accessible for a variety of use cases.
Reduced energy consumption
Efficient processing of deep neural networks significantly reduces energy consumption, which is a crucial advantage in both environmental and economic terms. As these networks require substantial computational power, optimizing their operations can lead to considerable energy savings. By minimizing the number of computations and utilizing hardware accelerators designed for efficiency, organizations can lower their carbon footprint and reduce operational costs. This is particularly important for data centers and edge devices where power efficiency directly impacts sustainability and profitability. Ultimately, reduced energy consumption not only supports greener technology initiatives but also enables the deployment of AI solutions in resource-constrained environments.
Real-time applications
Efficient processing of deep neural networks enables the implementation of real-time applications, where quick decision-making and response times are critical. By optimizing the computational efficiency of neural network models, tasks such as real-time speech recognition, image classification, video analysis, and autonomous driving can be performed with minimal latency. This capability opens up new possibilities for industries such as healthcare, finance, transportation, and more, where timely insights and actions based on data analysis are essential for success.
Optimized resource utilization
Efficient processing of deep neural networks leads to optimized resource utilization, which is a significant advantage in both economic and environmental terms. By streamlining the computational demands, organizations can reduce the need for extensive hardware infrastructure, thereby lowering operational costs. This optimization allows for more models to be run simultaneously on existing hardware, maximizing the use of available resources without additional investment. Furthermore, efficient processing minimizes energy consumption, contributing to a smaller carbon footprint and promoting sustainable practices in technology deployment. This not only enhances performance but also aligns with global efforts to reduce energy waste and environmental impact.
Enhanced scalability
Efficient processing of deep neural networks significantly enhances scalability, allowing models to handle larger datasets and more complex tasks without a proportional increase in computational resources. By optimizing the way neural networks are processed, it becomes feasible to deploy these models across various platforms, from powerful cloud servers to edge devices with limited processing power. This scalability ensures that as data volumes grow and application demands increase, the underlying systems can adapt and maintain high performance without requiring extensive infrastructure upgrades. Consequently, businesses and researchers can innovate and expand their AI capabilities more rapidly, reaching broader audiences and addressing more sophisticated challenges efficiently.
Cost-effective solutions
Efficient processing of deep neural networks leads to cost-effective solutions by significantly reducing the computational resources required for training and deploying models. By optimizing model architectures, utilizing specialized hardware accelerators, and implementing techniques like pruning and quantization, organizations can lower the energy consumption and hardware expenses associated with deep learning tasks. This not only makes advanced AI technologies accessible to smaller companies with limited budgets but also allows larger enterprises to scale their operations without incurring prohibitive costs. Ultimately, efficient processing enables businesses to leverage the power of deep neural networks while maintaining financial sustainability.
Increased accuracy
Efficient processing of deep neural networks can lead to increased accuracy in model predictions by enabling more sophisticated architectures and training techniques. When computational resources are optimized, it becomes feasible to experiment with deeper and more complex models that can capture intricate patterns in data. This allows for the incorporation of advanced features such as additional layers or novel activation functions that enhance the model’s ability to generalize from training data. Furthermore, efficient processing facilitates the use of larger datasets and more extensive hyperparameter tuning, both of which contribute to improved model accuracy. By reducing computational constraints, researchers and engineers can focus on refining models to achieve higher precision and reliability in various applications, from image recognition to natural language processing.
Complex implementation and tuning of optimization techniques may require specialized expertise.
Complex implementation and tuning of optimization techniques in deep neural networks can pose a significant challenge, as it often demands specialized expertise in machine learning, neural network architecture, and computational optimization. Fine-tuning parameters, selecting appropriate algorithms, and integrating various optimization strategies can be a daunting task that requires a deep understanding of the underlying principles. Without the necessary expertise, the process of optimizing deep neural networks for efficient processing may become time-consuming and error-prone, potentially hindering the realization of optimal performance gains. Specialized knowledge and experience are crucial to navigate the complexities involved in tuning these techniques effectively and ensuring that the resulting models deliver the desired outcomes.
Optimizing deep neural networks for efficiency can sometimes lead to a trade-off in model performance.
Optimizing deep neural networks for efficiency can sometimes lead to a trade-off in model performance. When focusing on reducing the computational complexity or size of a neural network, there is a risk of sacrificing accuracy or generalization ability. Techniques such as model pruning or quantization may result in a less expressive model that struggles to capture the intricacies of the data, leading to lower performance on certain tasks. It is crucial to strike a balance between efficiency and performance when optimizing deep neural networks to ensure that the trade-offs do not compromise the overall effectiveness of the model.
Hardware accelerators and parallel processing solutions can be costly to implement and maintain.
One significant drawback of efficient processing solutions for deep neural networks is the cost associated with implementing and maintaining hardware accelerators and parallel processing systems. Specialized hardware accelerators like GPUs or TPUs can be expensive to acquire, install, and integrate into existing infrastructure. Similarly, setting up and managing parallel processing solutions require additional resources and expertise, adding to the overall operational expenses. Moreover, ongoing maintenance and upgrades of these systems can further increase the financial burden on organizations looking to optimize their neural network processing efficiency.
Pruning and quantization techniques may introduce some level of information loss, affecting the accuracy of the model.
Pruning and quantization techniques, while effective in reducing the computational complexity of deep neural networks, come with a trade-off. These methods can lead to a certain level of information loss by removing unnecessary connections or representing weights with lower precision data types. This reduction in model complexity may impact the accuracy and performance of the neural network, especially in tasks that require high precision and fine-grained details. Careful consideration and balancing of efficiency gains with potential accuracy trade-offs are crucial when implementing pruning and quantization techniques in deep learning models to ensure optimal performance for specific use cases.