Deep Recurrent Neural Networks: Unleashing the Power of Sequential Data Processing
Deep recurrent neural networks (RNNs) have emerged as a groundbreaking technology in the field of artificial intelligence and machine learning. Unlike traditional feedforward neural networks, RNNs are designed to handle sequential data by retaining memory of past inputs. This unique capability makes them ideal for tasks such as natural language processing, speech recognition, and time series analysis.
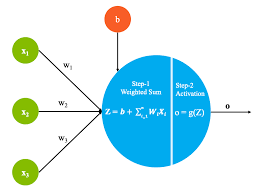
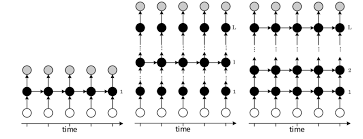
At the core of a deep RNN is the concept of recurrence, where the output of a hidden layer is fed back into the network as input for the next time step. This feedback loop enables RNNs to capture temporal dependencies in data, allowing them to model complex sequences and patterns more effectively than other types of neural networks.
One key advantage of deep RNNs is their ability to process variable-length sequences, making them versatile for tasks that involve sequential data of different lengths. By stacking multiple recurrent layers on top of each other, deep RNNs can learn hierarchical representations of data, extracting high-level features from raw input signals.
In recent years, deep RNNs have been successfully applied to a wide range of applications, including machine translation, sentiment analysis, and music generation. Their flexibility and adaptability make them a powerful tool for handling diverse types of sequential data with remarkable accuracy and efficiency.
Despite their strengths, deep RNNs are not without challenges. One common issue is vanishing or exploding gradients during training, which can hinder learning in deep networks with many layers. Researchers have developed techniques such as long short-term memory (LSTM) and gated recurrent units (GRU) to address these problems and improve the stability of training in deep RNN architectures.
As research in deep learning continues to advance, deep recurrent neural networks remain at the forefront of innovation in sequential data processing. Their ability to capture long-range dependencies and learn intricate patterns from sequential data make them an indispensable tool for solving complex real-world problems across various domains.
8 Essential Tips for Optimizing Deep Recurrent Neural Networks
- Use gated units like LSTMs or GRUs to combat vanishing/exploding gradients.
- Consider using bidirectional RNNs to capture information from both past and future contexts.
- Experiment with different activation functions like tanh or ReLU for better performance.
- Regularize your model with techniques like dropout or weight decay to prevent overfitting.
- Carefully tune hyperparameters such as learning rate and batch size for optimal training.
- Preprocess input data by normalizing or standardizing it to improve convergence speed.
- Monitor training progress using metrics like loss and accuracy to diagnose issues early on.
- Visualize model internals (e.g., activations, gradients) to gain insights into its behavior.
Use gated units like LSTMs or GRUs to combat vanishing/exploding gradients.
To address the challenge of vanishing or exploding gradients in deep recurrent neural networks, it is recommended to utilize gated units such as Long Short-Term Memory (LSTM) or Gated Recurrent Units (GRU). These specialized units are designed to control the flow of information within the network, allowing it to retain important information over long sequences and mitigate the issues of gradient instability during training. By incorporating LSTM or GRU units into the architecture of a deep RNN, practitioners can effectively combat the challenges associated with vanishing/exploding gradients and improve the overall stability and performance of the network.
Consider using bidirectional RNNs to capture information from both past and future contexts.
When working with deep recurrent neural networks, it is beneficial to consider using bidirectional RNNs to enhance the model’s ability to capture information from both past and future contexts. By incorporating bidirectional connections, the network can effectively analyze sequential data in both directions, allowing it to leverage information from preceding and subsequent time steps. This approach enables the model to gain a more comprehensive understanding of the input sequence and improve its performance in tasks that require capturing dependencies across the entire sequence.
Experiment with different activation functions like tanh or ReLU for better performance.
To enhance the performance of deep recurrent neural networks, it is recommended to experiment with different activation functions such as tanh or ReLU. Activation functions play a crucial role in shaping the behavior and learning capabilities of neural networks. By testing various activation functions, researchers and practitioners can determine which one best suits the specific characteristics of their data and model architecture. Tanh and ReLU are popular choices known for their effectiveness in improving network convergence speed and overall performance. Through careful experimentation and evaluation, selecting the most suitable activation function can significantly enhance the efficiency and accuracy of deep recurrent neural networks in handling sequential data processing tasks.
Regularize your model with techniques like dropout or weight decay to prevent overfitting.
To enhance the performance and generalization of your deep recurrent neural network model, it is crucial to apply regularization techniques such as dropout or weight decay. Overfitting, a common issue in deep learning models, occurs when the model performs well on training data but fails to generalize to unseen data. By incorporating dropout, which randomly deactivates a fraction of neurons during training, or weight decay, which penalizes large weights in the network, you can prevent overfitting and improve the model’s ability to generalize effectively. These regularization techniques help ensure that your deep recurrent neural network learns meaningful patterns from data without memorizing noise or irrelevant details, leading to more robust and reliable performance in real-world applications.
Carefully tune hyperparameters such as learning rate and batch size for optimal training.
To maximize the effectiveness of a deep recurrent neural network, it is crucial to meticulously adjust hyperparameters like the learning rate and batch size during training. The learning rate determines how quickly the model adapts to the data, while the batch size affects the stability and efficiency of the optimization process. By carefully tuning these hyperparameters, researchers and practitioners can enhance the network’s performance, accelerate convergence, and ultimately achieve optimal training results for tasks involving sequential data processing.
Preprocess input data by normalizing or standardizing it to improve convergence speed.
To enhance the convergence speed of a deep recurrent neural network, it is advisable to preprocess the input data by normalizing or standardizing it. This preprocessing step helps to scale the input features to a consistent range, which can improve the efficiency of the training process. By normalizing or standardizing the input data, we can mitigate issues related to varying scales and distributions of features, leading to more stable and faster convergence of the network during training.
Monitor training progress using metrics like loss and accuracy to diagnose issues early on.
Monitoring training progress using metrics like loss and accuracy is a crucial tip when working with deep recurrent neural networks. By keeping a close eye on these metrics during the training process, developers can quickly diagnose any issues that may arise and take corrective actions early on. Loss metrics provide insights into how well the model is performing and how much it is deviating from the desired output, while accuracy metrics measure the model’s overall performance in terms of correct predictions. By analyzing these metrics regularly, developers can fine-tune their models, adjust hyperparameters, and optimize training strategies to ensure better performance and faster convergence towards the desired outcomes.
Visualize model internals (e.g., activations, gradients) to gain insights into its behavior.
Visualizing the internals of a deep recurrent neural network, such as activations and gradients, can provide valuable insights into its behavior and performance. By examining how the network processes and transforms data at different layers, researchers and developers can better understand how information flows through the model and identify potential bottlenecks or areas for improvement. Visualizations of activations can reveal patterns and representations learned by the network, while visualizing gradients can help diagnose issues like vanishing or exploding gradients during training. Overall, gaining a visual understanding of a deep RNN’s internals can guide optimization efforts and lead to more effective model design and training strategies.