Convolutional Neural Networks for Visual Recognition
Convolutional Neural Networks (CNNs) have revolutionized the field of computer vision and visual recognition in recent years. These deep learning models are specifically designed to process visual data, such as images and videos, and extract meaningful features for tasks like object detection, classification, and segmentation.
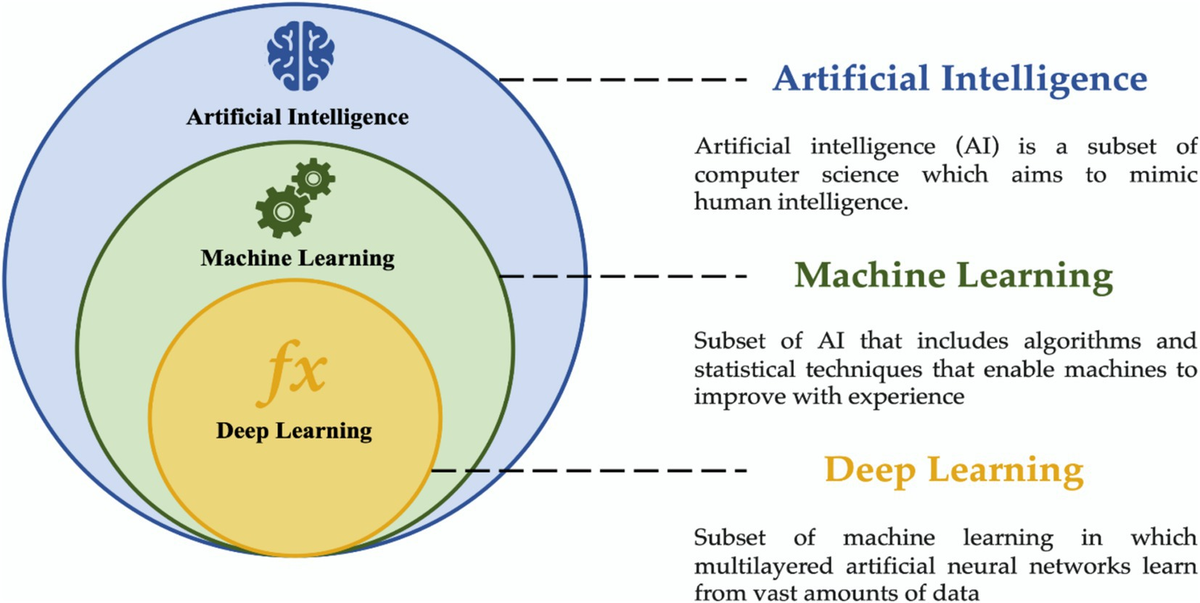
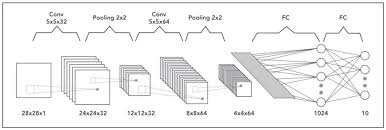
One of the key advantages of CNNs is their ability to automatically learn hierarchical representations of visual data. Through a series of convolutional layers, pooling layers, and fully connected layers, CNNs can capture intricate patterns and structures within an image, enabling them to make accurate predictions and classifications.
CNNs have been successfully applied in a wide range of applications, including facial recognition, autonomous driving, medical imaging analysis, and more. Their versatility and effectiveness have made them an indispensable tool for researchers and developers working in the field of computer vision.
Training a CNN involves feeding it with labeled training data and adjusting its parameters through backpropagation to minimize prediction errors. With the availability of large-scale datasets and powerful computing resources, CNNs can be trained to achieve state-of-the-art performance on various visual recognition tasks.
As research in deep learning continues to advance, CNNs are constantly evolving with new architectures, optimization techniques, and applications. The ongoing development of CNNs holds great promise for further enhancing visual recognition capabilities and pushing the boundaries of what is possible in computer vision.
Understanding Convolutional Neural Networks: Key FAQs on Visual Recognition
- What is a Convolutional Neural Network (CNN)?
- How do Convolutional Neural Networks process visual data?
- What are the key advantages of using CNNs for visual recognition?
- In what applications are Convolutional Neural Networks commonly used?
- How are Convolutional Neural Networks trained for visual recognition tasks?
- What are some popular architectures of Convolutional Neural Networks?
- How do researchers continue to advance the capabilities of CNNs for visual recognition?
What is a Convolutional Neural Network (CNN)?
A Convolutional Neural Network (CNN) is a specialized type of deep learning model designed specifically for processing visual data, such as images and videos. CNNs are composed of multiple layers, including convolutional layers, pooling layers, and fully connected layers, that work together to extract meaningful features from the input data. By automatically learning hierarchical representations of visual features, CNNs can effectively perform tasks like object detection, image classification, and segmentation with high accuracy. The architecture of CNNs is inspired by the visual processing system of the human brain, making them well-suited for a wide range of applications in computer vision and visual recognition tasks.
How do Convolutional Neural Networks process visual data?
Convolutional Neural Networks (CNNs) process visual data through a series of specialized layers designed to extract and learn features from images. The core concept behind CNNs is convolution, where filters are applied to small regions of an input image to detect patterns such as edges, textures, and shapes. These filters are learned during the training process, allowing the network to automatically identify relevant features for visual recognition tasks. Additionally, CNNs utilize pooling layers to downsample the extracted features and reduce computational complexity. By combining convolutional and pooling layers with fully connected layers for classification, CNNs can effectively process visual data and make accurate predictions based on learned features.
What are the key advantages of using CNNs for visual recognition?
When it comes to visual recognition, Convolutional Neural Networks (CNNs) offer several key advantages that make them a powerful tool in the field of computer vision. One major advantage is their ability to automatically learn hierarchical features from visual data, allowing them to capture intricate patterns and structures within images with high accuracy. CNNs excel at feature extraction and can adapt to different types of visual data, making them versatile for tasks like object detection, classification, and segmentation. Additionally, their deep architecture enables them to handle complex and large-scale datasets effectively, leading to state-of-the-art performance in various visual recognition tasks. Overall, the inherent capabilities of CNNs make them indispensable for researchers and developers seeking robust solutions for visual recognition challenges.
In what applications are Convolutional Neural Networks commonly used?
Convolutional Neural Networks (CNNs) are commonly used in a wide array of applications in the field of computer vision for visual recognition tasks. Some of the most common applications where CNNs excel include image classification, object detection, facial recognition, scene understanding, medical image analysis, autonomous driving systems, video analysis, and even in creative fields like art generation and style transfer. The hierarchical feature learning capabilities of CNNs make them particularly effective in tasks that involve processing visual data and extracting meaningful patterns and structures. Their versatility and robust performance have made CNNs a go-to solution for various real-world applications requiring accurate and efficient visual recognition capabilities.
How are Convolutional Neural Networks trained for visual recognition tasks?
Training Convolutional Neural Networks (CNNs) for visual recognition tasks involves a multi-step process that leverages labeled training data to optimize the network’s parameters for accurate predictions. Initially, the CNN is initialized with random weights, and as it processes training images through convolutional layers, pooling layers, and fully connected layers, it gradually learns to extract relevant features and patterns. Backpropagation is then used to calculate the gradients of the loss function with respect to the network’s weights, allowing for adjustments that minimize prediction errors. Through iterative optimization algorithms like stochastic gradient descent, the CNN fine-tunes its parameters to improve performance on the training data. With sufficient training iterations and appropriate regularization techniques, CNNs can learn complex visual representations and achieve high accuracy in various visual recognition tasks.
What are some popular architectures of Convolutional Neural Networks?
When it comes to Convolutional Neural Networks (CNNs) for visual recognition, there are several popular architectures that have gained widespread recognition for their effectiveness in various tasks. Some of the well-known CNN architectures include AlexNet, VGGNet, GoogLeNet (Inception), ResNet, and more. Each of these architectures is characterized by its unique design, layer configurations, and computational efficiency, making them suitable for different types of visual recognition tasks. Researchers and practitioners often choose a specific CNN architecture based on the complexity of the task at hand, the size of the dataset, and the desired level of accuracy and efficiency required for the application.
How do researchers continue to advance the capabilities of CNNs for visual recognition?
Researchers continue to advance the capabilities of Convolutional Neural Networks (CNNs) for visual recognition through ongoing innovation and exploration of new techniques and architectures. By experimenting with novel network designs, optimizing training algorithms, and leveraging larger and more diverse datasets, researchers aim to enhance the performance, efficiency, and generalization ability of CNNs. Additionally, advancements in areas such as transfer learning, attention mechanisms, and interpretability contribute to pushing the boundaries of CNNs for visual recognition tasks. Through continuous research and collaboration within the deep learning community, researchers strive to unlock new possibilities and further improve the effectiveness of CNNs in addressing complex visual recognition challenges.