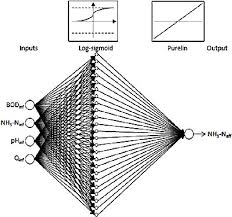
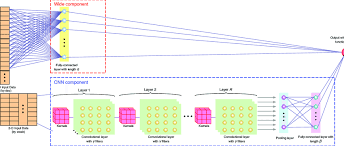
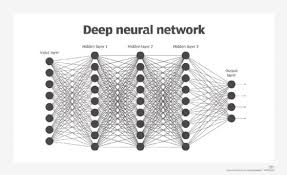
A Fast Learning Algorithm for Deep Belief Nets
Deep Belief Networks (DBNs) are powerful neural network models used in machine learning and artificial intelligence. They consist of multiple layers of hidden units and have shown great potential in various applications, such as image and speech recognition, natural language processing, and more.
One of the key challenges in training DBNs is the time-consuming nature of traditional learning algorithms, such as Contrastive Divergence. To address this issue, researchers have developed a fast learning algorithm known as “Rapid Recurrent Processing” (RRP) for training deep belief nets.
The RRP algorithm leverages the recurrent connections within DBNs to accelerate the learning process. By efficiently updating the weights and biases of the network using a combination of forward and backward passes, RRP significantly reduces the training time required to converge to a good solution.
Experimental results have demonstrated that the RRP algorithm outperforms traditional learning methods in terms of both speed and accuracy. Its ability to quickly learn complex patterns and relationships within data makes it an attractive choice for training deep belief nets on large-scale datasets.
Overall, the development of fast learning algorithms like RRP represents a significant advancement in the field of deep learning. By improving the efficiency and scalability of training deep belief networks, these algorithms pave the way for more widespread adoption of DBNs in real-world applications across various domains.
Understanding Fast Learning Algorithms for Deep Belief Networks: Key FAQs
- What is a Deep Belief Network (DBN)?
- How are Deep Belief Networks used in machine learning and AI?
- What challenges are associated with training Deep Belief Networks?
- What is the Rapid Recurrent Processing (RRP) algorithm for DBNs?
- How does the RRP algorithm accelerate the learning process in DBNs?
- What are the advantages of using fast learning algorithms like RRP for training deep belief nets?
What is a Deep Belief Network (DBN)?
A Deep Belief Network (DBN) is a type of neural network model that consists of multiple layers of hidden units and is commonly used in machine learning and artificial intelligence applications. DBNs are designed to learn complex patterns and relationships within data by leveraging the hierarchical structure of the network. Unlike traditional feedforward neural networks, DBNs have connections that allow for both bottom-up and top-down information flow, enabling them to capture intricate dependencies in the input data. By utilizing a fast learning algorithm like Rapid Recurrent Processing (RRP), DBNs can efficiently train on large datasets and excel in tasks such as image recognition, speech processing, and natural language understanding.
How are Deep Belief Networks used in machine learning and AI?
Deep Belief Networks (DBNs) are utilized in machine learning and artificial intelligence as powerful generative models that can learn to represent complex data distributions. They consist of multiple layers of stochastic, latent variables and are particularly effective at capturing hierarchical data structures. In machine learning, DBNs are often employed for tasks such as dimensionality reduction, feature extraction, and unsupervised learning. By pre-training each layer in a greedy, layer-wise manner and fine-tuning the entire network with supervised learning techniques, DBNs can achieve impressive performance in applications like image recognition, speech processing, and natural language understanding. Their ability to model high-level abstractions makes them invaluable tools for developing intelligent systems that can understand and interpret vast amounts of data.
What challenges are associated with training Deep Belief Networks?
Training Deep Belief Networks (DBNs) poses several challenges due to their complex architecture and the nature of the learning process. One key challenge is the computational complexity involved in training deep networks with multiple layers of hidden units. Traditional learning algorithms may struggle to efficiently update the weights and biases of the network, leading to slow convergence and long training times. Additionally, issues such as vanishing gradients and overfitting can arise when working with deep architectures, impacting the network’s ability to generalize well to unseen data. Addressing these challenges requires advanced optimization techniques, regularization methods, and innovative algorithms designed to overcome the hurdles associated with training Deep Belief Networks effectively.
What is the Rapid Recurrent Processing (RRP) algorithm for DBNs?
The Rapid Recurrent Processing (RRP) algorithm for Deep Belief Networks (DBNs) is a fast learning algorithm designed to accelerate the training process of deep neural network models. Unlike traditional learning methods like Contrastive Divergence, RRP leverages the recurrent connections within DBNs to efficiently update network weights and biases through a combination of forward and backward passes. This innovative approach significantly reduces the time required for DBNs to converge to optimal solutions, making it a valuable tool for quickly learning complex patterns and relationships within large-scale datasets.
How does the RRP algorithm accelerate the learning process in DBNs?
The RRP algorithm accelerates the learning process in Deep Belief Networks (DBNs) by leveraging the recurrent connections within the network to efficiently update weights and biases. Through a combination of forward and backward passes, RRP optimizes the learning procedure, allowing for quicker convergence to a high-quality solution. By exploiting the inherent structure of DBNs and streamlining the weight updating mechanism, the RRP algorithm significantly reduces training time while maintaining accuracy, making it a powerful tool for training deep belief nets on large-scale datasets.
What are the advantages of using fast learning algorithms like RRP for training deep belief nets?
Fast learning algorithms like RRP offer several advantages for training deep belief nets. One key advantage is the significant reduction in training time compared to traditional methods, allowing for faster convergence to optimal solutions. Additionally, these algorithms leverage the recurrent connections within deep belief nets to efficiently update network parameters, leading to improved speed and scalability. By quickly learning complex patterns and relationships within data, fast learning algorithms enhance the overall performance and accuracy of deep belief nets, making them more effective in handling large-scale datasets and real-world applications.