Image segmentation neural networks are a powerful tool in the field of computer vision that enable the precise identification and delineation of objects within an image. This technology plays a crucial role in various applications, such as medical image analysis, autonomous driving, and object recognition in robotics.
Unlike traditional image classification tasks that assign a single label to an entire image, image segmentation neural networks segment an image into multiple regions or pixels and assign labels to each segment based on the characteristics of the objects present. This allows for more detailed analysis and understanding of the visual content within an image.
One common type of neural network used for image segmentation is the U-Net architecture, which consists of an encoder-decoder structure with skip connections. The encoder captures high-level features from the input image, while the decoder reconstructs the segmented output by upsampling and combining features from different layers to preserve spatial information.
Image segmentation neural networks are trained on labeled datasets where each pixel or region is annotated with the corresponding object class. During training, the network learns to predict accurate segmentations by minimizing a loss function that measures the difference between predicted and ground truth segmentations.
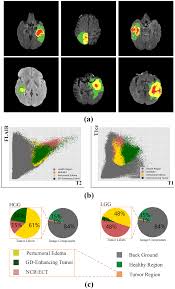
The applications of image segmentation neural networks are diverse and impactful. In medical imaging, these networks are used for tumor detection, organ segmentation, and disease diagnosis. In autonomous driving systems, they help identify pedestrians, vehicles, and road markings for safe navigation. In robotics, they enable precise object manipulation and interaction in complex environments.
As research in computer vision advances, so do the capabilities of image segmentation neural networks. Ongoing developments focus on improving accuracy, efficiency, and robustness of these networks to handle challenging real-world scenarios. With continued innovation and collaboration across academia and industry, image segmentation neural networks are poised to drive further advancements in visual understanding and artificial intelligence.
Understanding Image Segmentation: Exploring CNN Applications and Top Algorithms
- Can CNN be used for image segmentation?
- Why CNN is used for image segmentation?
- What is image segmentation neural network?
- What is the best algorithm for image segmentation?
Can CNN be used for image segmentation?
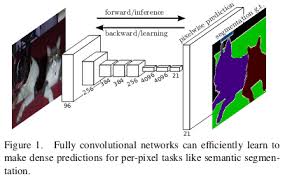
Yes, Convolutional Neural Networks (CNNs) can indeed be used for image segmentation tasks. CNNs have proven to be highly effective in various computer vision applications, including image segmentation. By leveraging the hierarchical feature extraction capabilities of CNNs, researchers and practitioners have developed architectures specifically designed for image segmentation, such as Fully Convolutional Networks (FCNs) and U-Net.
Why CNN is used for image segmentation?
Convolutional Neural Networks (CNNs) are commonly used for image segmentation due to their ability to effectively capture spatial hierarchies and learn intricate patterns within images. CNNs are well-suited for tasks like image segmentation because of their inherent architecture, which includes convolutional layers that extract features at different scales and depths. These layers enable CNNs to automatically learn meaningful representations from raw pixel data, allowing them to identify objects, boundaries, and textures within images. Additionally, the use of pooling layers helps reduce spatial dimensions while preserving important features, making CNNs efficient for processing large-scale image data in segmentation tasks. Overall, the hierarchical and adaptive nature of CNNs makes them a powerful choice for image segmentation applications where precise object delineation and accurate pixel-wise labeling are essential.
What is image segmentation neural network?
Image segmentation neural network is a sophisticated technology used in computer vision that involves dividing an image into distinct regions or pixels to accurately identify and label objects within the image. Unlike traditional image classification methods, image segmentation neural networks provide detailed information about the spatial layout of objects, enabling precise analysis and understanding of visual content. These networks, such as the popular U-Net architecture, employ encoder-decoder structures with skip connections to capture fine details and preserve spatial relationships during segmentation. By training on annotated datasets and minimizing loss functions, image segmentation neural networks learn to generate accurate segmentations for a wide range of applications, from medical imaging to autonomous driving and robotics.
What is the best algorithm for image segmentation?
When it comes to image segmentation, the choice of algorithm depends on various factors such as the specific characteristics of the images, the complexity of the objects to be segmented, and the desired level of accuracy and efficiency. There is no one-size-fits-all answer to the question of the best algorithm for image segmentation, as different algorithms have their strengths and limitations. Some popular algorithms used for image segmentation include U-Net, Mask R-CNN, FCN (Fully Convolutional Network), and SegNet. Each algorithm has its own unique architecture and features that make it suitable for different types of segmentation tasks. It is essential to carefully evaluate the requirements of a particular project and experiment with different algorithms to determine which one best meets the specific needs and objectives of the image segmentation task at hand.