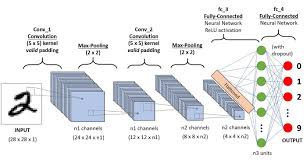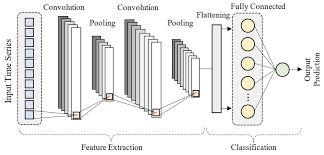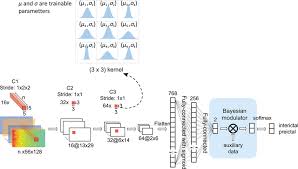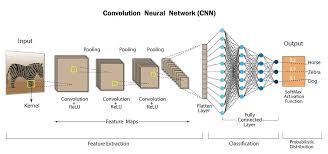
Convolutional Neural Networks (CNNs) have revolutionized the field of image recognition and computer vision. One significant advancement in this realm is the development of Fully Convolutional Neural Networks (FCNs), which have proven to be highly effective in tasks such as semantic segmentation, object detection, and image classification.
Unlike traditional CNNs that are designed for image classification tasks, FCNs are capable of producing pixel-wise predictions by preserving spatial information throughout the network. This is achieved by replacing fully connected layers with convolutional layers, allowing the network to accept input images of any size and produce output maps at a corresponding resolution.
The architecture of FCNs typically consists of an encoder-decoder structure, where the encoder extracts features from the input image through a series of convolutional and pooling layers. The decoder then upsamples these features back to the original input resolution using transposed convolutions or other upsampling techniques.
One key component of FCNs is skip connections, which enable the network to combine low-level and high-level features during upsampling, resulting in more precise segmentation masks and improved performance. By incorporating skip connections, FCNs can capture both fine-grained details and global context in the output predictions.
FCNs have been successfully applied in various computer vision tasks, including semantic segmentation for autonomous driving, medical image analysis, and video processing. Their ability to generate dense predictions efficiently makes them a valuable tool for extracting detailed information from images and videos.
In conclusion, Fully Convolutional Neural Networks represent a significant advancement in deep learning architectures for image analysis. Their ability to perform pixel-wise predictions while preserving spatial information has opened up new possibilities in computer vision applications, paving the way for more accurate and robust solutions in diverse fields.
7 Essential Tips for Optimizing Fully Convolutional Neural Networks
- Use skip connections to preserve spatial information
- Apply appropriate padding to maintain input size through layers
- Utilize upsampling layers for increasing spatial resolution
- Employ batch normalization for faster convergence and better generalization
- Use proper activation functions like ReLU to introduce non-linearity
- Consider pre-trained models for transfer learning in specific tasks
- Regularize the network with techniques like dropout to prevent overfitting
Use skip connections to preserve spatial information
To enhance the performance and accuracy of Fully Convolutional Neural Networks (FCNs), it is advisable to incorporate skip connections in the architecture. Skip connections play a crucial role in preserving spatial information throughout the network, allowing for more precise segmentation and better feature extraction. By integrating skip connections, FCNs can effectively combine low-level and high-level features during upsampling, resulting in more detailed and contextually rich output predictions. This strategy not only improves the network’s ability to capture fine-grained details but also enhances its overall performance in tasks such as semantic segmentation and object detection.
Apply appropriate padding to maintain input size through layers
When working with Fully Convolutional Neural Networks, it is crucial to apply appropriate padding to maintain the input size as the data passes through different layers of the network. By carefully selecting the padding strategy, such as zero-padding or same-padding, you can ensure that the spatial dimensions of the input data are preserved throughout the network architecture. This helps in retaining important spatial information and enables the network to generate accurate and reliable predictions without losing valuable details during the convolutional operations. Proper padding not only aids in maintaining consistency in input size but also plays a vital role in enhancing the overall performance and effectiveness of Fully Convolutional Neural Networks in various image processing tasks.
Utilize upsampling layers for increasing spatial resolution
To enhance the spatial resolution of Fully Convolutional Neural Networks, it is crucial to leverage upsampling layers effectively. By incorporating upsampling layers in the decoder part of the network, low-resolution feature maps can be upsampled to match the original input image size. This process helps maintain spatial details and improve the network’s ability to generate accurate pixel-wise predictions. Through strategic utilization of upsampling layers, Fully Convolutional Neural Networks can achieve higher spatial resolution outputs, enabling more precise segmentation and object detection in various computer vision tasks.
Employ batch normalization for faster convergence and better generalization
Batch normalization is a crucial technique when training Fully Convolutional Neural Networks, as it helps to accelerate convergence and improve the model’s generalization capabilities. By normalizing the input data within each mini-batch during training, batch normalization ensures that the network learns more efficiently and effectively. This results in faster convergence of the training process and better generalization to unseen data, ultimately leading to improved performance and robustness of the model.
Use proper activation functions like ReLU to introduce non-linearity
To enhance the performance of a Fully Convolutional Neural Network, it is crucial to incorporate appropriate activation functions such as Rectified Linear Unit (ReLU) to introduce non-linearity. By using ReLU, the network can efficiently model complex relationships within the data by allowing for the representation of non-linear patterns. This helps in capturing intricate features in images and improving the network’s ability to learn and make accurate predictions. Additionally, ReLU activation function aids in preventing the vanishing gradient problem during training, ensuring more stable and effective optimization of the network parameters.
Consider pre-trained models for transfer learning in specific tasks
When working with Fully Convolutional Neural Networks, it is beneficial to consider utilizing pre-trained models for transfer learning in specific tasks. Pre-trained models, trained on large datasets for general tasks like image classification, can serve as a valuable starting point for fine-tuning on a smaller dataset tailored to a specific task. By leveraging the knowledge and learned features from pre-trained models, transfer learning can help improve the performance and efficiency of Fully Convolutional Neural Networks in tasks such as semantic segmentation, object detection, and image recognition.
Regularize the network with techniques like dropout to prevent overfitting
To enhance the performance and generalization of a Fully Convolutional Neural Network, it is crucial to implement regularization techniques such as dropout. By incorporating dropout, which randomly deactivates certain neurons during training, the network becomes less likely to rely on specific features or patterns in the data, thus mitigating the risk of overfitting. This regularization method encourages the network to learn more robust and generalized representations, leading to improved performance on unseen data and better overall model reliability.