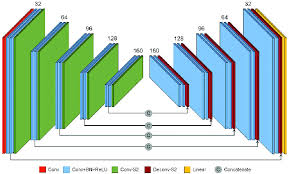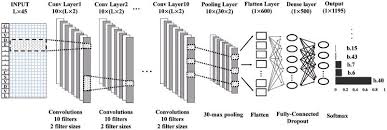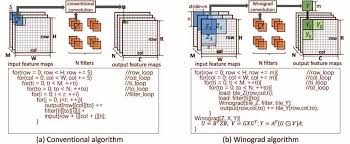
Convolutional Neural Networks (CNNs) have revolutionized the field of deep learning, particularly in image recognition and computer vision tasks. One key factor that contributes to the success of CNNs is the use of fast algorithms that optimize the computation process and improve efficiency.
Fast algorithms for CNNs play a crucial role in reducing training time, improving model performance, and enabling the deployment of deep learning models on resource-constrained devices. These algorithms focus on optimizing various aspects of convolutional operations, such as filter processing, feature map computation, and parameter updates.
One popular fast algorithm used in CNNs is the Fast Fourier Transform (FFT), which can accelerate the computation of convolutions by converting spatial convolutions into element-wise multiplications in the frequency domain. By leveraging FFT-based convolution, CNNs can achieve significant speedups without compromising accuracy.
Another important technique for optimizing CNNs is Winograd’s minimal filtering algorithm, which reduces the number of arithmetic operations required for convolution by transforming it into a series of matrix multiplications. This approach minimizes redundant computations and memory access, leading to faster inference and training times.
Furthermore, techniques like depthwise separable convolutions and group convolutions help reduce the computational complexity of CNNs by decomposing standard convolutions into smaller and more efficient operations. These methods not only speed up inference but also enable effective model compression and parameter sharing.
In addition to algorithmic optimizations, hardware accelerators like Graphics Processing Units (GPUs) and specialized Tensor Processing Units (TPUs) play a vital role in speeding up CNN computations. These dedicated hardware platforms leverage parallel processing capabilities to execute convolutional operations efficiently and handle large-scale neural network models with ease.
Overall, fast algorithms for convolutional neural networks are essential for unlocking the full potential of deep learning models in various applications. By continuously improving computational efficiency and performance optimization techniques, researchers and engineers can push the boundaries of CNN-based solutions and drive innovation in artificial intelligence.
8 Tips for Speeding Up Convolutional Neural Networks with Fast Algorithms
- Use GPU acceleration for faster computations.
- Utilize parallel processing to speed up convolutions.
- Apply techniques like pruning to reduce the number of parameters and computations.
- Implement efficient data augmentation methods to increase training speed and generalization.
- Use batch normalization to stabilize and accelerate training.
- Utilize depthwise separable convolutions for reducing computation.
- Leverage pre-trained models or transfer learning to save training time.
- Optimize hyperparameters such as learning rate, batch size, and optimizer choice for faster convergence.
Use GPU acceleration for faster computations.
Utilizing GPU acceleration is a crucial tip for speeding up computations in convolutional neural networks. Graphics Processing Units (GPUs) are highly efficient at performing parallel computations, making them ideal for handling the intensive matrix operations involved in CNNs. By harnessing the power of GPUs, neural network training and inference can be significantly accelerated, leading to faster model convergence and improved overall performance. GPU acceleration not only reduces training time but also enhances the scalability of deep learning models, enabling researchers and practitioners to tackle more complex tasks and deploy CNN-based solutions efficiently.
Utilize parallel processing to speed up convolutions.
By utilizing parallel processing techniques, convolutional neural networks can significantly accelerate the computation of convolutions. Parallel processing allows multiple computations to be performed simultaneously, leveraging the power of multi-core processors or specialized hardware accelerators like GPUs and TPUs. This approach enables CNNs to process convolutions in a highly efficient manner, reducing training and inference times while improving overall performance. By harnessing the capabilities of parallel processing, researchers and developers can unlock the full potential of fast algorithms for CNNs and enhance the scalability and effectiveness of deep learning models in various applications.
Apply techniques like pruning to reduce the number of parameters and computations.
Applying techniques like pruning is a powerful strategy to enhance the efficiency of convolutional neural networks by reducing the number of parameters and computations involved in model training and inference. Pruning involves identifying and removing redundant or less important connections within the network, leading to a more compact and streamlined architecture without compromising performance. By selectively pruning connections based on certain criteria, such as weight magnitude or activation values, practitioners can achieve significant reductions in model size and computational complexity, making CNNs more lightweight, faster, and suitable for deployment on resource-constrained devices.
Implement efficient data augmentation methods to increase training speed and generalization.
Implementing efficient data augmentation methods is a valuable tip for enhancing the training speed and generalization performance of convolutional neural networks. By augmenting the training data with transformations like rotation, scaling, flipping, and cropping, neural networks can learn from a more diverse set of examples and improve their ability to generalize to unseen data. Data augmentation not only accelerates the training process by providing a larger and more varied dataset but also helps prevent overfitting by exposing the model to different variations of the input data. This approach ultimately leads to faster convergence during training and better overall performance of CNNs in real-world applications.
Use batch normalization to stabilize and accelerate training.
One effective tip for optimizing the training process of convolutional neural networks is to incorporate batch normalization into the model architecture. Batch normalization helps stabilize and accelerate the training of CNNs by normalizing the input data within each mini-batch during training. This technique reduces internal covariate shift, making the network more robust and enabling faster convergence during optimization. By incorporating batch normalization layers into CNNs, researchers and practitioners can improve model performance, reduce overfitting, and achieve better generalization on various tasks, ultimately enhancing the efficiency and effectiveness of deep learning models.
Utilize depthwise separable convolutions for reducing computation.
By utilizing depthwise separable convolutions in convolutional neural networks, you can significantly reduce computation and enhance efficiency. This technique decomposes standard convolutions into separate depthwise and pointwise convolution layers, allowing for a more streamlined and resource-efficient computation process. By minimizing redundant operations and leveraging parameter sharing, depthwise separable convolutions not only accelerate inference and training times but also facilitate model compression without sacrificing performance. This approach proves to be a valuable strategy in optimizing CNNs for various applications where computational resources are limited or speed is a critical factor.
Leverage pre-trained models or transfer learning to save training time.
One effective tip for optimizing training time in convolutional neural networks is to leverage pre-trained models or transfer learning. By utilizing existing models that have been trained on large datasets, practitioners can benefit from the knowledge and feature representations learned by those models, saving significant time and computational resources. Transfer learning allows for fine-tuning the pre-trained model on a new dataset or task, enabling faster convergence and improved performance compared to training a model from scratch. This approach not only accelerates the training process but also enhances the generalization capabilities of the model, making it a valuable strategy for efficiently building and deploying CNNs in various applications.
Optimize hyperparameters such as learning rate, batch size, and optimizer choice for faster convergence.
Optimizing hyperparameters such as learning rate, batch size, and optimizer choice is a crucial tip for achieving faster convergence in convolutional neural networks. The learning rate controls the step size during optimization and adjusting it appropriately can help speed up training by finding the optimal model parameters more efficiently. Similarly, tuning the batch size affects the stability and efficiency of training, with larger batch sizes often leading to faster convergence but requiring more memory. Choosing the right optimizer, whether it’s SGD, Adam, or RMSprop, can also impact training speed and model performance. By fine-tuning these hyperparameters judiciously, researchers and practitioners can accelerate the convergence of CNNs and improve overall training efficiency.