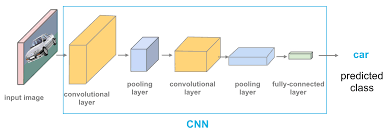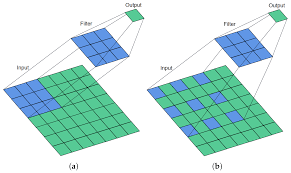
A dilated convolutional neural network (DCNN) is a type of convolutional neural network that incorporates dilated convolutions to increase the receptive field of the network without significantly increasing the number of parameters. This innovative architecture has been widely adopted in various computer vision tasks, such as image segmentation, object detection, and image classification.
Traditional convolutional neural networks use standard convolutions with a fixed kernel size and stride. However, these standard convolutions have limitations in capturing long-range dependencies in the input data. Dilated convolutions, also known as atrous convolutions, address this issue by introducing gaps between kernel elements, effectively expanding the receptive field of each layer.
By using dilated convolutions in a neural network architecture, researchers and developers can design models that can capture contextual information over larger spatial areas while maintaining computational efficiency. This is particularly beneficial for tasks that require understanding global context, such as semantic segmentation in images or processing sequential data with long-range dependencies.
The key advantage of dilated convolutions is their ability to increase the receptive field exponentially with each additional dilation factor. This allows DCNNs to effectively integrate information from distant parts of the input data without the need for pooling layers or significantly increasing the number of parameters in the network.
In summary, dilated convolutional neural networks offer a powerful solution for capturing long-range dependencies in input data while maintaining computational efficiency. By leveraging dilated convolutions in neural network architectures, researchers and developers can enhance the performance of their models in various computer vision tasks and pave the way for further advancements in deep learning applications.
Understanding Dilated Convolutional Neural Networks: Key FAQs Answered
- What is a dilated causal convolution?
- What is the difference between dilated convolution and deconvolution?
- What is dilated causal convolution?
- What is a good kernel size for CNN?
- What is dilated convolutional neural network?
- What is the difference between convolution and dilated convolution?
- What is true about atrous convolution?
What is a dilated causal convolution?
A dilated causal convolution is a variation of dilated convolutions commonly used in sequence modeling tasks, such as natural language processing and time series analysis. In a dilated causal convolution, the dilation factor is applied in a causal manner, meaning that the output at each time step only depends on previous time steps and not future ones. This ensures that the model maintains a sense of temporal order and does not introduce information leakage from future time steps. By incorporating dilated causal convolutions into neural network architectures, researchers can effectively capture long-range dependencies in sequential data while preserving the integrity of the temporal relationships within the input sequences.
What is the difference between dilated convolution and deconvolution?
In the context of convolutional neural networks, the key difference between dilated convolution and deconvolution lies in their fundamental operations. Dilated convolution, also known as atrous convolution, involves expanding the receptive field of a network by introducing gaps between kernel elements. This allows the network to capture long-range dependencies in the input data without significantly increasing parameters. On the other hand, deconvolution, or transposed convolution, is used for upsampling and increasing the spatial resolution of feature maps. While both operations play crucial roles in neural network architectures, dilated convolution focuses on expanding the receptive field for better context awareness, whereas deconvolution is primarily used for upsampling and reconstruction tasks.
What is dilated causal convolution?
Dilated causal convolution is a specific type of convolution operation that incorporates both dilation and causality in the context of neural networks. In this setting, “causal” refers to the restriction that the output at any time step can only depend on previous time steps and not future ones. By introducing dilation, which involves skipping input elements in the convolution kernel, dilated causal convolution allows neural networks to capture long-range dependencies in sequential data while maintaining the causal structure. This technique is commonly used in tasks such as time series analysis, natural language processing, and audio processing, where preserving temporal order and capturing contextual information are crucial for accurate predictions and understanding of the data.
What is a good kernel size for CNN?
When determining the optimal kernel size for a convolutional neural network (CNN), there is no one-size-fits-all answer as it largely depends on the specific task and dataset at hand. In general, smaller kernel sizes (e.g., 3×3) are commonly used in CNNs as they allow for capturing fine-grained features and details in the input data. On the other hand, larger kernel sizes (e.g., 5×5 or 7×7) can help capture more global patterns and structures in the data. It is essential to experiment with different kernel sizes during model training and validation to find the most suitable one that balances between capturing local details and global context for optimal performance.
What is dilated convolutional neural network?
A dilated convolutional neural network, also known as DCNN, is a specialized type of convolutional neural network that incorporates dilated convolutions to expand the receptive field of the network without significantly increasing the number of parameters. By introducing gaps between kernel elements, dilated convolutions allow the network to capture contextual information over larger spatial areas, making it particularly effective in tasks that require understanding global context in input data. This innovative architecture has gained popularity in various computer vision applications for its ability to efficiently integrate information from distant parts of the input data, thereby improving the model’s performance in tasks such as image segmentation, object detection, and image classification.
What is the difference between convolution and dilated convolution?
In the context of neural networks, the main difference between convolution and dilated convolution lies in how they process input data. Traditional convolution applies a filter to neighboring pixels in a sequential manner, capturing local information within a limited receptive field. On the other hand, dilated convolution introduces gaps between kernel elements, allowing the network to capture information from a wider spatial area without significantly increasing parameters. This dilation factor effectively expands the receptive field of each layer, enabling the network to learn long-range dependencies and contextual information more efficiently. By understanding this distinction, practitioners can leverage dilated convolutions to enhance the performance of their models in tasks that require capturing global context and spatial relationships within input data.
What is true about atrous convolution?
Atrous convolution, also known as dilated convolution, is a technique used in convolutional neural networks to increase the receptive field of the network without adding more parameters. Unlike traditional convolutions that have a fixed kernel size and stride, atrous convolutions introduce gaps between kernel elements to effectively expand the receptive field. This allows the network to capture contextual information over larger spatial areas while maintaining computational efficiency. Atrous convolution is particularly useful for tasks that require understanding global context and long-range dependencies in the input data, making it a valuable tool in various computer vision applications.