Deconvolution Neural Network: Understanding the Architecture and Applications
Deconvolution neural networks (DNNs) have emerged as a powerful tool in the field of deep learning, offering unique capabilities for image processing, computer vision, and pattern recognition tasks. In this article, we will delve into the architecture of deconvolution neural networks and explore their wide-ranging applications.
Architecture of Deconvolution Neural Networks
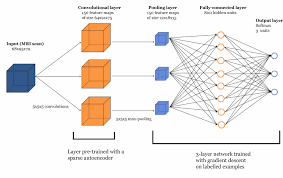
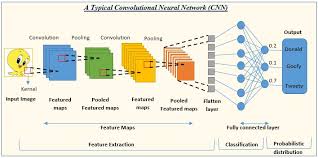
Deconvolution neural networks are a type of convolutional neural network (CNN) that operate in reverse to traditional convolutional layers. While convolutional layers perform feature extraction by applying filters to input data, deconvolution layers work to reconstruct or upsample data.
The key components of a deconvolution neural network include:
- Deconvolution Layers: These layers perform the inverse operation of convolutional layers by increasing the spatial resolution of feature maps.
- Activation Functions: Common activation functions such as ReLU (Rectified Linear Unit) are used to introduce non-linearity into the network.
- Pooling Layers: Deconvolution networks may also include pooling layers to downsample feature maps.
- Loss Function: A loss function is used to measure the error between predicted and ground truth values during training.
Applications of Deconvolution Neural Networks
The unique architecture of deconvolution neural networks lends itself to a variety of applications across different domains. Some notable applications include:
- Semantic Segmentation: DNNs are widely used for pixel-wise classification tasks in images, such as identifying objects within an image.
- Saliency Detection: DNNs can be applied to highlight regions of interest in images, aiding in visual attention modeling.
- Inpainting: DNNs are utilized for filling in missing or corrupted parts of images, restoring them to their original state.
- Spatial Transformer Networks: DNNs with spatial transformer modules can learn spatial transformations within an image, enabling geometric transformations like rotation and scaling.
In conclusion, deconvolution neural networks offer a versatile framework for tasks requiring upsampling or reconstruction of data. With their ability to capture intricate details and patterns in images, DNNs continue to drive advancements in computer vision and image processing applications.
Understanding Deconvolution Neural Networks: Key Questions Answered
- What is deconvolution in neural network?
- What’s the difference between deconvolution and convolution?
- Is deconvolution same as upsampling?
- Is deconvolution and transposed convolution same?
- What are the two types of deconvolution?
- What is the deconvolution method?
- What’s the difference between convolution and deconvolution?
What is deconvolution in neural network?
Deconvolution in a neural network refers to the process of reconstructing or upsampling data, typically in the context of deep learning models like convolutional neural networks (CNNs). Unlike traditional convolutional layers that perform feature extraction by applying filters to input data, deconvolution layers work in reverse to increase the spatial resolution of feature maps. This inverse operation allows deconvolution neural networks to reconstruct detailed information from lower-dimensional representations, making them valuable for tasks such as image segmentation, image generation, and feature visualization in deep learning applications.
What’s the difference between deconvolution and convolution?
In the realm of neural networks, a commonly asked question pertains to the distinction between deconvolution and convolution operations. While convolution involves filtering input data to extract features, deconvolution, on the other hand, focuses on reconstructing or upsampling data. In convolutional neural networks (CNNs), convolution layers are employed for feature extraction, while deconvolution layers play a role in reconstructing spatial information. Essentially, convolution reduces the spatial dimensions of data through filtering, whereas deconvolution works in reverse to increase spatial resolution. Understanding this fundamental difference is crucial for grasping the unique functionalities and applications of both operations within neural network architectures.
Is deconvolution same as upsampling?
The frequently asked question regarding deconvolution neural networks is whether deconvolution is the same as upsampling. In the context of neural networks, deconvolution is often used as a form of upsampling, but they are not exactly the same. Deconvolution layers in neural networks can be utilized for upsampling by increasing the spatial resolution of feature maps, effectively reconstructing or expanding the input data. While deconvolution can achieve upsampling, it involves additional operations beyond simple interpolation, such as learning filters and patterns from data. Therefore, while deconvolution can be a method of upsampling within neural networks, it encompasses more complex processes than traditional upsampling techniques.
Is deconvolution and transposed convolution same?
The frequently asked question about deconvolution neural networks often revolves around the distinction between deconvolution and transposed convolution. While these terms are sometimes used interchangeably in the literature, it is important to note that they are not exactly the same. Deconvolution in the context of neural networks generally refers to the process of upsampling or reconstructing data, while transposed convolution specifically refers to a mathematical operation that achieves this upsampling. Transposed convolution can be seen as a method for implementing deconvolution within neural network architectures, but they are not synonymous terms. Understanding this distinction can help clarify the role and functionality of these operations within the realm of deep learning and image processing tasks.
What are the two types of deconvolution?
In the realm of deconvolution neural networks, there are two primary types of deconvolution operations commonly used: transposed convolution and fractional stride convolution. Transposed convolution, also known as deconvolution, involves applying a learnable upsampling filter to increase the spatial resolution of feature maps. On the other hand, fractional stride convolution achieves upsampling by inserting zeros between input pixels and then convolving with a filter. Understanding the differences and applications of these two types of deconvolution is essential for effectively leveraging their capabilities in tasks such as image reconstruction, semantic segmentation, and generative modeling.
What is the deconvolution method?
The deconvolution method in the context of neural networks refers to a process that reverses or reconstructs the output of convolutional layers. Unlike traditional convolution operations that extract features from input data, deconvolution layers help in upscaling or increasing the spatial resolution of feature maps. This method plays a crucial role in tasks such as image segmentation, object detection, and image reconstruction, allowing neural networks to capture finer details and nuances within data. By employing deconvolution techniques, neural networks can enhance interpretability and generate high-quality outputs for various computer vision applications.
What’s the difference between convolution and deconvolution?
One frequently asked question in the realm of neural networks is: “What’s the difference between convolution and deconvolution?” Convolution and deconvolution are fundamental operations in deep learning, each serving distinct purposes. While convolution involves extracting features from input data through filters to create feature maps, deconvolution, on the other hand, focuses on reconstructing or upsampling data to recover spatial information lost during convolution. In essence, convolution is about feature extraction and downscaling, whereas deconvolution is geared towards reconstruction and upscaling. Understanding the nuances between these two operations is crucial for effectively utilizing them in neural network architectures for tasks such as image processing and computer vision.