Understanding Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs) are a class of deep neural networks that have proven highly effective in areas such as image recognition and classification. CNNs have been instrumental in many advancements in computer vision, which has applications in various fields including medical diagnosis, autonomous vehicles, and facial recognition systems.
What is a Convolutional Neural Network?
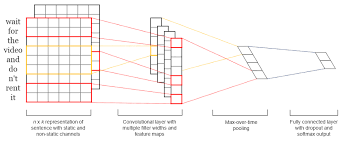
A CNN is a type of artificial neural network designed to process data that comes in the form of multiple arrays, such as color images composed of pixel values across three color channels (RGB). The architecture of a CNN is inspired by the visual cortex’s structure in animals and humans, where individual neurons respond to stimuli only in a restricted region of the visual field known as the receptive field. This idea is replicated in CNNs through the use of convolutional layers that process portions of the input data independently.
The Architecture of CNNs
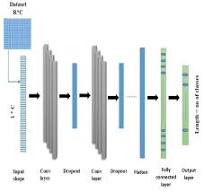
The typical architecture of a convolutional neural network includes several layers that transform the input data to produce an output that can be used for classification purposes. These layers include:
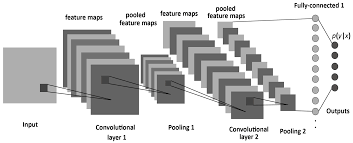
- Convolutional Layers: These are the core building blocks of a CNN. They apply a number of filters to the input for feature detection. A filter slides across the input data performing an element-wise multiplication and sums up the results into a single output pixel.
- Activation Function: Usually, after each convolution operation, an activation function is applied to introduce non-linear properties into the system. The Rectified Linear Unit (ReLU) function is commonly used.
- Pooling Layers: Also known as subsampling or downsampling, pooling reduces the dimensionality of each feature map while retaining important information. Max pooling, which selects the maximum element from each subregion of feature map, is frequently used.
- Fully Connected Layers: After several convolutional and pooling layers, the high-level reasoning in the neural network occurs via fully connected layers where every neuron is connected to every neuron in the previous layer.
The final layer uses an activation function such as softmax for classification tasks where it assigns probabilities for each class label.
The Advantages of Using CNNs
CNNs are particularly advantageous for processing visual data due to their ability to detect patterns with extreme variability (such as different angles or lighting conditions), and their robustness against distortions and simple geometric transformations. Some key advantages include:
- Spatial Hierarchies: CNNs can learn increasingly complex features at each layer; lower layers might detect edges while higher layers may identify more complex shapes or objects within an image.
- Parameter Sharing: Filters are applied across an entire input image, which means fewer parameters are required compared with fully connected networks on large images, leading to reduced computational cost.
- Sparse Interactions: By focusing on local spatial connections through small receptive fields, CNNs exploit spatial locality by enforcing a local connectivity pattern between neurons.
CNNs In Practice
In practice, training a convolutional neural network requires large datasets and significant computational power. However, once trained, they can be incredibly efficient. Applications range from analyzing visual imagery for diagnostic purposes in healthcare to powering real-time object recognition systems that are critical components in autonomous vehicles.
The Future Of Convolutional Neural Networks
The future developments around convolutional neural networks continue to push boundaries with researchers exploring new architectures like Capsule Networks (CapsNets) and experimenting with different approaches to improve performance further. The ongoing evolution ensures that CNNs will remain at the forefront of machine learning technologies for image analysis and beyond.
In conclusion, Convolutional Neural Networks represent one of today’s most significant advancements in artificial intelligence by providing machines with an almost human-like ability to recognize patterns within visual data—a technology with limitless potential applications across industries worldwide.
5 Proven Strategies to Optimize Convolutional Neural Networks for Enhanced Performance
- Start with pre-trained models for faster convergence
- Use data augmentation to increase the size of your training dataset
- Experiment with different architectures like VGG, ResNet, or Inception
- Fine-tune the hyperparameters such as learning rate and batch size for better performance
- Visualize intermediate layers to understand how features are being extracted
Start with pre-trained models for faster convergence
Starting with pre-trained models is a valuable tip when working with convolutional neural networks as it can significantly accelerate the training process and improve convergence. Pre-trained models are neural network architectures that have already been trained on large datasets, typically for tasks like image classification. By leveraging these pre-trained models and fine-tuning them on your specific dataset, you can benefit from the knowledge and features learned during the initial training phase. This approach not only saves time and computational resources but also helps in achieving better performance results, especially when working with limited data or computational power.
Use data augmentation to increase the size of your training dataset
Utilizing data augmentation is a valuable strategy when working with convolutional neural networks. By applying various transformations to your existing dataset, such as rotation, flipping, scaling, or adding noise, you can effectively increase the size of your training dataset. This not only helps prevent overfitting but also enhances the model’s ability to generalize and recognize patterns in new, unseen data. Data augmentation is a powerful technique that can improve the robustness and performance of convolutional neural networks, ultimately leading to more accurate and reliable results in image classification tasks.
Experiment with different architectures like VGG, ResNet, or Inception
When delving into the realm of convolutional neural networks, it is highly beneficial to experiment with various architectures such as VGG, ResNet, or Inception. Each of these architectures offers unique features and advantages that can significantly impact the performance and accuracy of your neural network model. By exploring different architectures, you can gain valuable insights into how different design choices affect the network’s ability to learn and generalize from data. This experimentation process not only enhances your understanding of CNNs but also equips you with the knowledge to select the most suitable architecture for specific tasks or datasets, ultimately leading to improved results in your machine learning endeavors.
Fine-tune the hyperparameters such as learning rate and batch size for better performance
To enhance the performance of a convolutional neural network, it is crucial to fine-tune hyperparameters like the learning rate and batch size. The learning rate determines how quickly the model adapts to the training data, while the batch size influences how many samples are processed before updating the model’s parameters. By experimenting with different values for these hyperparameters and finding the optimal combination, one can significantly improve the CNN’s accuracy and efficiency in processing visual data. Adjusting these settings allows for better training convergence and ultimately leads to a more effective neural network for image recognition tasks.
Visualize intermediate layers to understand how features are being extracted
Visualizing intermediate layers in a convolutional neural network is a valuable tip that can provide insights into how features are being extracted at different stages of the network. By examining the output of these intermediate layers, researchers and developers can gain a deeper understanding of the network’s inner workings and how it processes information. This visualization technique can help identify which features are being detected at each layer, enabling fine-tuning of the network architecture for better performance and more accurate results.