Image recognition technology has made significant strides in recent years, revolutionizing various industries and applications. One prominent player in this field is Convolutional Neural Networks (CNN), a type of deep learning algorithm designed to process visual data efficiently and accurately.
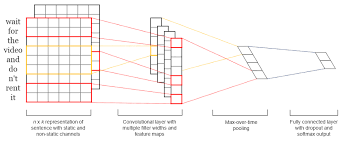
CNNs have gained widespread popularity for their ability to extract features from images through convolutional layers, pooling layers, and fully connected layers. This hierarchical structure allows CNNs to learn patterns and characteristics within images, making them well-suited for tasks such as object detection, image classification, and facial recognition.
One of the key strengths of CNNs lies in their ability to automatically learn and adapt to different types of visual data. By training on large datasets, CNNs can generalize patterns and make predictions on new, unseen images with impressive accuracy. This versatility has led to CNNs being used in a wide range of applications, including autonomous vehicles, medical imaging analysis, security systems, and more.
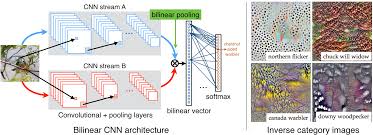
CNN-based image recognition systems have also shown remarkable performance in challenging tasks such as image segmentation and scene understanding. By leveraging the power of deep learning and neural networks, CNNs can analyze complex visual scenes and provide valuable insights that were once thought to be exclusive to human perception.
As research in image recognition continues to advance, CNNs are expected to play an increasingly vital role in shaping the future of artificial intelligence and computer vision. With ongoing improvements in model architectures, training techniques, and computational resources, CNN-based image recognition systems are poised to unlock new possibilities and drive innovation across various industries.
5 Essential Tips for Enhancing CNN Image Recognition Performance
- Preprocess images by resizing them to a fixed size before feeding into the CNN model.
- Use data augmentation techniques like rotation, flipping, and scaling to increase the diversity of training data.
- Fine-tune pre-trained CNN models on specific image recognition tasks for better performance.
- Regularize the CNN model using techniques like dropout or L2 regularization to prevent overfitting.
- Experiment with different CNN architectures (e.g., VGG, ResNet, Inception) to find the best model for your image recognition task.
Preprocess images by resizing them to a fixed size before feeding into the CNN model.
When working with CNN image recognition models, a helpful tip is to preprocess images by resizing them to a fixed size before feeding them into the model. By standardizing the image dimensions, you ensure that the CNN can effectively learn and extract features from the input data. Resizing images to a consistent size also helps optimize computational efficiency and improve the overall performance of the model during training and inference stages. This preprocessing step plays a crucial role in enhancing the accuracy and reliability of CNN-based image recognition systems.
Use data augmentation techniques like rotation, flipping, and scaling to increase the diversity of training data.
To enhance the performance of CNN image recognition models, it is recommended to employ data augmentation techniques such as rotation, flipping, and scaling. By applying these methods to the training data, the diversity and variability of the dataset can be increased, allowing the model to learn robust features and improve its generalization capabilities. Rotation helps the model recognize objects from different angles, flipping introduces variations in orientation, and scaling alters the size of objects in images. These techniques not only enrich the training data but also help prevent overfitting, ultimately leading to more accurate and reliable CNN image recognition results.
Fine-tune pre-trained CNN models on specific image recognition tasks for better performance.
To enhance the performance of image recognition tasks using CNN models, a valuable tip is to fine-tune pre-trained CNN models on specific datasets related to the desired recognition task. By leveraging the knowledge and features learned from a general dataset during pre-training, fine-tuning allows the model to adapt and specialize for more specific visual recognition tasks. This process helps improve accuracy and efficiency by tailoring the model’s parameters to better suit the nuances and complexities of the target dataset, ultimately leading to enhanced performance in image recognition tasks.
Regularize the CNN model using techniques like dropout or L2 regularization to prevent overfitting.
To enhance the performance and generalization of a CNN model in image recognition tasks, it is crucial to incorporate regularization techniques such as dropout or L2 regularization. These methods help prevent overfitting by introducing constraints during the training process, which discourage the model from memorizing noise or irrelevant patterns in the training data. Dropout randomly deactivates neurons during training, forcing the network to learn more robust and diverse features. On the other hand, L2 regularization penalizes large weight values, promoting simpler and smoother decision boundaries. By regularizing the CNN model effectively, it can improve its ability to generalize well to unseen data and achieve better performance in real-world applications.
Experiment with different CNN architectures (e.g., VGG, ResNet, Inception) to find the best model for your image recognition task.
To optimize your image recognition task using CNN, it is recommended to experiment with various architectures such as VGG, ResNet, and Inception to determine the most suitable model. Each of these architectures offers unique strengths and capabilities that can impact the performance and accuracy of your image recognition system. By testing different CNN models and comparing their results, you can identify the architecture that best aligns with your specific task requirements, dataset characteristics, and computational resources. This iterative process of exploration and evaluation will help you fine-tune your image recognition model for optimal performance and efficiency.