The Role of Convolutional Neural Networks (CNN) in Image Processing
Convolutional Neural Networks (CNN) have revolutionized the field of image processing and computer vision. CNNs are a type of deep learning algorithm specifically designed to analyze visual data, making them ideal for tasks such as image recognition, object detection, and image classification.
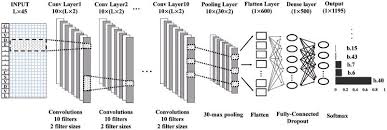
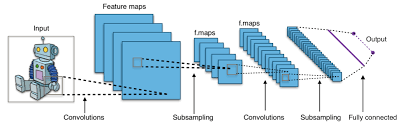
One of the key features of CNNs is their ability to automatically learn and extract features from images. This is achieved through a process known as convolution, where the network applies filters or kernels to the input image to detect patterns such as edges, textures, and shapes.
By stacking multiple convolutional layers followed by pooling layers and fully connected layers, CNNs can learn hierarchical representations of visual information. This enables them to recognize complex patterns and objects within images with high accuracy.
CNNs have been widely used in various applications, including facial recognition systems, autonomous vehicles, medical imaging analysis, and more. They have significantly improved the performance of image processing tasks compared to traditional methods.
Furthermore, CNNs can be fine-tuned or retrained on specific datasets to adapt to different domains or tasks. This flexibility makes them versatile tools for a wide range of image processing applications.
In conclusion, Convolutional Neural Networks play a crucial role in advancing the field of image processing by enabling automated feature extraction, pattern recognition, and high-level understanding of visual data. As technology continues to evolve, CNNs are expected to drive further innovations in image analysis and computer vision.
8 Essential Tips for Effective CNN Image Processing
- Normalize the pixel values of images before feeding them into the CNN
- Use data augmentation techniques to increase the diversity of your training dataset
- Experiment with different CNN architectures such as VGG, ResNet, and Inception
- Fine-tune pre-trained CNN models on your specific dataset for better performance
- Monitor the training process by visualizing metrics like loss and accuracy over epochs
- Regularize your CNN model using techniques like dropout or L2 regularization to prevent overfitting
- Utilize transfer learning by leveraging features learned from a large dataset for a similar task
- Optimize hyperparameters such as learning rate, batch size, and optimizer choice for improved results
Normalize the pixel values of images before feeding them into the CNN
Normalizing the pixel values of images before feeding them into a Convolutional Neural Network (CNN) is a crucial preprocessing step in image processing. By scaling the pixel values to a common range, such as [0, 1] or [-1, 1], we ensure that the network receives consistent input data, which helps in improving training stability and convergence. Normalization also helps in reducing the impact of varying pixel intensity levels across different images, making the CNN more robust and effective in extracting meaningful features. This simple yet powerful tip can significantly enhance the performance of CNNs in tasks such as image classification, object detection, and image segmentation.
Use data augmentation techniques to increase the diversity of your training dataset
Utilizing data augmentation techniques is a valuable tip in CNN image processing as it helps enhance the diversity and richness of the training dataset. By applying transformations such as rotation, flipping, scaling, and cropping to the existing images, data augmentation can effectively increase the variability of the dataset without collecting new data. This process enables the CNN model to learn from a wider range of visual patterns and variations, leading to improved generalization and robustness in image recognition tasks. Incorporating data augmentation techniques is a smart strategy to boost the performance and accuracy of CNN models in handling real-world image data with different orientations, lighting conditions, and backgrounds.
Experiment with different CNN architectures such as VGG, ResNet, and Inception
To enhance your skills in CNN image processing, it is recommended to experiment with various architectures like VGG, ResNet, and Inception. Each of these CNN models offers unique features and performance characteristics that can significantly impact the results of image analysis tasks. By exploring different architectures and understanding their strengths and weaknesses, you can gain valuable insights into how to optimize your image processing workflows and achieve better accuracy in tasks such as object recognition, classification, and feature extraction.
Fine-tune pre-trained CNN models on your specific dataset for better performance
Fine-tuning pre-trained Convolutional Neural Network (CNN) models on your specific dataset can significantly enhance performance in image processing tasks. By leveraging the knowledge and features learned from a general dataset, fine-tuning allows the model to adapt and specialize to the unique characteristics of your data. This process helps the CNN better recognize patterns and objects relevant to your specific domain, leading to improved accuracy and efficiency in image classification, object detection, and other visual recognition tasks.
Monitor the training process by visualizing metrics like loss and accuracy over epochs
Monitoring the training process of Convolutional Neural Networks (CNN) by visualizing metrics such as loss and accuracy over epochs is a crucial tip in image processing. By keeping track of these metrics, developers can gain insights into how well the model is learning and improving over time. Analyzing the trends in loss and accuracy helps in identifying potential issues, fine-tuning hyperparameters, and optimizing the training process to achieve better performance. This practice not only ensures the effectiveness of the CNN model but also facilitates informed decision-making for enhancing its capabilities in image recognition tasks.
Regularize your CNN model using techniques like dropout or L2 regularization to prevent overfitting
Regularizing your CNN model using techniques like dropout or L2 regularization is essential in preventing overfitting. Overfitting occurs when a model performs well on training data but fails to generalize to new, unseen data. By incorporating regularization methods into your CNN architecture, you can help the model learn more robust and generalizable features, improving its performance on unseen data. Dropout randomly disables a fraction of neurons during training, forcing the network to learn redundant representations and reducing the risk of overfitting. Similarly, L2 regularization adds a penalty term to the loss function, discouraging overly complex models and promoting simpler and more generalizable solutions. By implementing these techniques, you can enhance the performance and reliability of your CNN model for various image processing tasks.
Utilize transfer learning by leveraging features learned from a large dataset for a similar task
To enhance the efficiency and effectiveness of CNN image processing, a valuable tip is to implement transfer learning. By leveraging features extracted from a large dataset for a similar task, transfer learning allows for the reusability of pre-trained models and accelerates the learning process for new datasets. This approach not only saves time and computational resources but also improves the performance of CNNs by transferring knowledge from one domain to another, ultimately enhancing the accuracy and robustness of image processing tasks.
Optimize hyperparameters such as learning rate, batch size, and optimizer choice for improved results
Optimizing hyperparameters, such as the learning rate, batch size, and choice of optimizer, is a crucial tip in CNN image processing to achieve enhanced results. The learning rate determines how quickly or slowly a model learns during training, while the batch size affects the efficiency of parameter updates. Additionally, selecting the right optimizer can significantly impact the convergence speed and overall performance of the CNN model. By fine-tuning these hyperparameters based on the specific dataset and task at hand, researchers and practitioners can improve the accuracy and efficiency of their image processing algorithms.