3D Convolutional Neural Networks for Human Action Recognition
Human action recognition is a challenging task in computer vision that involves identifying and classifying human actions or activities from video data. With the increasing availability of video content on the internet and the growing demand for automated video analysis, there is a need for efficient and accurate methods to recognize human actions in videos.
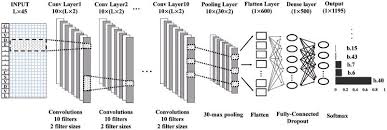
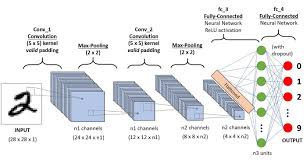
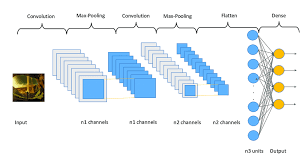
One of the most powerful approaches to tackle this problem is through the use of 3D Convolutional Neural Networks (CNNs). Unlike traditional 2D CNNs that operate on individual frames of a video, 3D CNNs are designed to capture spatiotemporal information by considering both spatial and temporal dimensions simultaneously.
By incorporating 3D convolutions into neural network architectures, researchers have been able to achieve remarkable results in human action recognition tasks. These networks can automatically learn features that are relevant for distinguishing different actions based on how they evolve over time in a video sequence.
The key advantage of 3D CNNs lies in their ability to model motion patterns and temporal dependencies in videos, making them well-suited for tasks such as action recognition, gesture recognition, and activity detection. This capability enables them to capture complex motion dynamics and variations in human actions more effectively than traditional methods.
Researchers continue to explore and refine 3D CNN architectures, experimenting with different network designs, training strategies, and data augmentation techniques to improve performance on challenging action recognition datasets. With ongoing advancements in deep learning and computer vision research, the future looks promising for the development of even more sophisticated models for human action recognition using 3D CNNs.
8 Essential Tips for Enhancing Human Action Recognition with 3D Convolutional Neural Networks
- Use 3D convolutional layers to capture spatial and temporal features simultaneously.
- Consider using pre-trained models such as C3D or I3D for transfer learning.
- Augment your dataset with transformations like flipping, scaling, and cropping to improve generalization.
- Implement techniques like dropout and batch normalization to prevent overfitting.
- Experiment with different network architectures and hyperparameters to find the optimal configuration.
- Utilize techniques like early stopping during training to avoid model overfitting.
- Fine-tune the model on your specific action recognition task for better performance.
- Evaluate the model using metrics like accuracy, precision, recall, and F1 score.
Use 3D convolutional layers to capture spatial and temporal features simultaneously.
To enhance the accuracy of human action recognition in video data, it is recommended to leverage 3D convolutional layers within neural network architectures. By utilizing these layers, the model can effectively capture both spatial and temporal features simultaneously. This approach enables the network to analyze how actions evolve over time in a video sequence, allowing for a more comprehensive understanding of complex motion patterns and variations in human activities. The integration of 3D convolutions plays a crucial role in enhancing the performance of the model by enabling it to learn and extract relevant spatiotemporal features essential for accurate action recognition.
Consider using pre-trained models such as C3D or I3D for transfer learning.
When working on human action recognition tasks using 3D convolutional neural networks, it is highly beneficial to consider utilizing pre-trained models like C3D or I3D for transfer learning. These pre-trained models have already been trained on large-scale video datasets and have learned valuable spatiotemporal features that can be transferred to new action recognition tasks. By leveraging the knowledge encoded in these pre-trained models, researchers and practitioners can expedite the training process, improve model performance, and achieve better results with limited data. Transfer learning with established 3D CNN architectures like C3D or I3D can be a strategic approach to enhance the efficiency and effectiveness of human action recognition systems.
Augment your dataset with transformations like flipping, scaling, and cropping to improve generalization.
To enhance the generalization capabilities of your 3D Convolutional Neural Network for human action recognition, consider augmenting your dataset with transformations such as flipping, scaling, and cropping. By introducing variations in the training data through these transformations, the network can learn to recognize actions more robustly and accurately across different scenarios and conditions. This data augmentation technique helps the model generalize better to unseen examples, improving its performance and reliability in real-world applications.
Implement techniques like dropout and batch normalization to prevent overfitting.
To enhance the performance and generalization of 3D Convolutional Neural Networks for human action recognition, it is advisable to incorporate techniques such as dropout and batch normalization. Dropout helps prevent overfitting by randomly deactivating a certain percentage of neurons during training, forcing the network to learn more robust features. On the other hand, batch normalization normalizes the input of each layer, making the training process more stable and accelerating convergence. By integrating these techniques into the network architecture, researchers can improve the model’s ability to generalize well on unseen data and achieve better accuracy in recognizing human actions from video sequences.
Experiment with different network architectures and hyperparameters to find the optimal configuration.
To enhance the performance of 3D Convolutional Neural Networks for human action recognition, it is crucial to experiment with various network architectures and hyperparameters to discover the most effective configuration. By exploring different combinations of layers, filters, kernel sizes, and other parameters, researchers can fine-tune the network to better capture spatiotemporal features in video data and improve classification accuracy. This iterative process of optimization allows for the identification of the optimal configuration that maximizes the network’s ability to recognize and classify human actions with precision and efficiency.
Utilize techniques like early stopping during training to avoid model overfitting.
To enhance the training process of 3D Convolutional Neural Networks for human action recognition, it is advisable to incorporate techniques such as early stopping. By implementing early stopping during training, the model can prevent overfitting by monitoring its performance on a validation set and halting the training process when further optimization no longer leads to improved generalization. This approach helps ensure that the model does not memorize the training data but instead learns meaningful patterns that can accurately recognize human actions in unseen video sequences.
Fine-tune the model on your specific action recognition task for better performance.
Fine-tuning the 3D convolutional neural network model on a specific action recognition task can significantly enhance its performance. By fine-tuning the model, you can adapt its learned features to better align with the nuances and characteristics of the target dataset, leading to improved accuracy and robustness in recognizing human actions. This process allows the model to specialize and optimize its parameters for the specific task at hand, ultimately resulting in more precise and reliable action recognition outcomes.
Evaluate the model using metrics like accuracy, precision, recall, and F1 score.
When working with 3D Convolutional Neural Networks for human action recognition, it is essential to evaluate the model’s performance using a range of metrics such as accuracy, precision, recall, and F1 score. These metrics provide valuable insights into how well the model is able to correctly classify human actions in videos. Accuracy measures the overall correctness of the predictions, while precision quantifies the proportion of correctly predicted positive instances out of all predicted positive instances. Recall, on the other hand, calculates the proportion of correctly predicted positive instances out of all actual positive instances. The F1 score combines precision and recall into a single metric, providing a balanced assessment of the model’s performance in terms of both false positives and false negatives. By analyzing these metrics, researchers can gain a comprehensive understanding of the effectiveness and reliability of their 3D CNN models for human action recognition tasks.