
The Power of Simple Neural Networks
Neural networks have revolutionized the field of artificial intelligence and machine learning, enabling computers to learn from data and make decisions in a way that mimics the human brain. Among the various types of neural networks, simple neural networks stand out for their effectiveness and versatility.
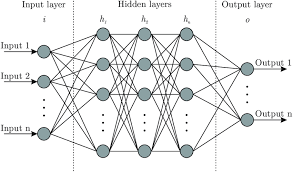
Simple neural networks, also known as feedforward neural networks, consist of layers of interconnected nodes called neurons. Each neuron receives input signals, processes them using weights and biases, and produces an output signal that is passed on to the next layer. The simplicity of this architecture allows for efficient training and implementation.
One of the key advantages of simple neural networks is their ability to learn complex patterns and relationships in data. By adjusting the weights and biases during training, the network can optimize its performance on a given task, such as image recognition or natural language processing. This adaptability makes simple neural networks well-suited for a wide range of applications.
Another strength of simple neural networks is their scalability. While more complex neural network architectures exist, such as convolutional neural networks and recurrent neural networks, simple neural networks can often achieve comparable results with fewer computational resources. This makes them ideal for tasks where efficiency is crucial.
In conclusion, simple neural networks represent a powerful tool in the realm of artificial intelligence, offering a balance between performance and simplicity. As researchers continue to explore new ways to improve these networks and push the boundaries of what they can achieve, we can expect simple neural networks to remain a cornerstone of machine learning for years to come.
5 Essential Tips for Building and Optimizing Simple Neural Networks
- Start with a simple neural network architecture, such as a single hidden layer with a few neurons.
- Normalize your input data to improve training performance and convergence.
- Use an appropriate activation function like ReLU in hidden layers to introduce non-linearity.
- Experiment with different learning rates and batch sizes to find the optimal values for your model.
- Regularize your neural network using techniques like L2 regularization or dropout to prevent overfitting.
Start with a simple neural network architecture, such as a single hidden layer with a few neurons.
When delving into the realm of neural networks, it is advisable to begin with a straightforward architecture, such as a single hidden layer containing just a few neurons. This minimalist approach allows for a clear understanding of the fundamental concepts and principles behind neural networks, making it easier to grasp the intricacies of how data is processed and patterns are learned. By starting with a simple neural network structure, one can build a solid foundation upon which more complex architectures can be explored and developed in the future.
Normalize your input data to improve training performance and convergence.
Normalizing input data is a crucial step in optimizing the training performance and convergence of simple neural networks. By scaling the input features to a consistent range, such as between 0 and 1 or -1 and 1, normalization helps prevent certain features from dominating the learning process. This ensures that the neural network can more effectively learn the underlying patterns in the data without being biased by variations in the scale of different features. Overall, normalizing input data is a key strategy to enhance the efficiency and accuracy of training simple neural networks.
Use an appropriate activation function like ReLU in hidden layers to introduce non-linearity.
When building a simple neural network, it is crucial to select the right activation function for the hidden layers to introduce non-linearity and enhance the network’s ability to learn complex patterns in data. One popular choice is the Rectified Linear Unit (ReLU) activation function, known for its simplicity and effectiveness in preventing the vanishing gradient problem. By using ReLU in hidden layers, the network can better capture intricate relationships within the data, leading to improved performance and accuracy in various machine learning tasks.
Experiment with different learning rates and batch sizes to find the optimal values for your model.
When working with a simple neural network, it is essential to experiment with different learning rates and batch sizes to determine the most effective values for your specific model. The learning rate controls how quickly the model adapts to the data during training, while the batch size determines how many samples are processed at once. By testing various combinations of learning rates and batch sizes, you can fine-tune your model’s performance and improve its accuracy and efficiency. Finding the optimal values for these parameters is a key step in maximizing the effectiveness of your simple neural network.
Regularize your neural network using techniques like L2 regularization or dropout to prevent overfitting.
To enhance the performance and generalization of your simple neural network, it is crucial to apply regularization techniques such as L2 regularization or dropout. These methods help prevent overfitting by adding constraints to the network’s parameters during training. L2 regularization penalizes large weights in the network, encouraging a simpler model that is less likely to memorize noise in the training data. Dropout randomly deactivates neurons during training, forcing the network to learn more robust and generalizable features. By incorporating these regularization techniques into your simple neural network, you can improve its ability to generalize well to unseen data and achieve better overall performance.

