The Power of Deep Convolutional Neural Networks
Deep Convolutional Neural Networks (CNNs) have revolutionized the field of artificial intelligence and machine learning in recent years. These sophisticated neural networks are designed to process visual data, making them particularly effective in tasks such as image recognition, object detection, and even facial recognition.
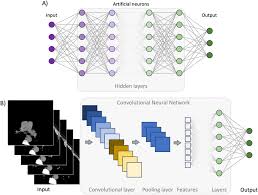
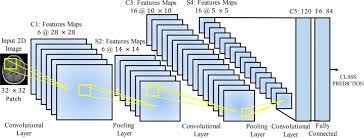
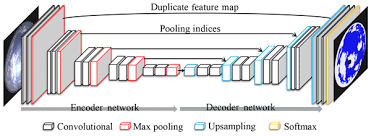
At the core of CNNs are convolutional layers that apply filters to input data, allowing the network to learn hierarchical representations of features at different levels of abstraction. By stacking multiple convolutional layers with non-linear activation functions, CNNs can extract intricate patterns and structures from raw input images.
One of the key advantages of deep CNNs is their ability to automatically learn features from data, eliminating the need for manual feature extraction. This not only simplifies the model-building process but also enables CNNs to achieve superior performance on complex visual tasks.
Moreover, deep CNNs leverage techniques such as pooling layers and fully connected layers to further enhance their ability to capture spatial hierarchies and make accurate predictions. Through extensive training on large datasets, CNNs can generalize well to unseen data and exhibit impressive levels of accuracy.
Applications of deep CNNs span a wide range of industries, including healthcare (medical image analysis), automotive (autonomous driving systems), security (surveillance systems), and more. Their versatility and effectiveness have made them indispensable tools for tackling real-world challenges that require advanced visual processing capabilities.
In conclusion, deep Convolutional Neural Networks represent a groundbreaking advancement in the field of artificial intelligence, offering unparalleled capabilities in visual data analysis and interpretation. As researchers continue to push the boundaries of deep learning technology, we can expect even more remarkable innovations and applications powered by these powerful neural networks.
Unveiling the Layers: A Guide to Deep Convolutional Neural Networks and Their Real-World Applications
- What are deep convolutional neural networks (CNNs) and how do they work?
- What are the key components of a deep convolutional neural network?
- How are deep CNNs different from traditional neural networks?
- What are the advantages of using deep convolutional neural networks for image recognition?
- How can I train a deep CNN model for a specific visual task?
- What are some common challenges faced when working with deep convolutional neural networks?
- What real-world applications benefit from the use of deep CNNs?
What are deep convolutional neural networks (CNNs) and how do they work?
Deep Convolutional Neural Networks (CNNs) are a class of artificial neural networks specifically designed for processing visual data, such as images and videos. These deep learning models consist of multiple layers, including convolutional layers that apply filters to input images to extract features, pooling layers that downsample the extracted features, and fully connected layers that make final predictions based on the learned features. By leveraging hierarchical representations of visual information, deep CNNs can effectively learn and recognize complex patterns and structures within images, enabling tasks such as image classification, object detection, and image segmentation. The success of deep CNNs lies in their ability to automatically learn meaningful features from raw pixel data through training on large datasets, making them powerful tools for a wide range of computer vision applications.
What are the key components of a deep convolutional neural network?
In deep convolutional neural networks, the key components include convolutional layers, pooling layers, activation functions, and fully connected layers. Convolutional layers apply filters to input data to extract features at different levels of abstraction. Pooling layers reduce the spatial dimensions of the feature maps to make the network more computationally efficient. Activation functions introduce non-linearity to the network, enabling it to learn complex patterns in the data. Fully connected layers connect every neuron in one layer to every neuron in the next layer, allowing the network to make final predictions based on learned features. These components work together seamlessly to enable deep CNNs to process visual data effectively and achieve high levels of accuracy in tasks such as image recognition and object detection.
How are deep CNNs different from traditional neural networks?
Deep Convolutional Neural Networks (CNNs) differ from traditional neural networks in their specialized architecture tailored for processing visual data. While traditional neural networks are designed for general-purpose tasks and operate on fully connected layers, CNNs leverage convolutional layers that apply filters to input images, allowing them to extract spatial hierarchies and learn features at different levels of abstraction. This hierarchical feature learning capability enables deep CNNs to excel in tasks such as image recognition, object detection, and facial recognition with higher accuracy and efficiency compared to traditional neural networks. Additionally, deep CNNs eliminate the need for manual feature extraction, making them more adept at handling complex visual data and achieving superior performance on challenging visual tasks.
What are the advantages of using deep convolutional neural networks for image recognition?
When it comes to image recognition, the advantages of using deep convolutional neural networks (CNNs) are undeniable. Deep CNNs excel in extracting intricate patterns and features from raw input images through their hierarchical architecture, allowing them to learn complex representations with remarkable accuracy. By automatically learning features from data without the need for manual extraction, deep CNNs streamline the model-building process and enhance performance on visual tasks. Their ability to generalize well to unseen data, coupled with techniques like pooling and fully connected layers, enables deep CNNs to capture spatial hierarchies effectively, making them ideal for tasks such as object detection, facial recognition, and scene understanding. In essence, the power of deep CNNs lies in their capacity to process visual data with precision and efficiency, making them indispensable tools for image recognition applications across various industries.
How can I train a deep CNN model for a specific visual task?
Training a deep Convolutional Neural Network (CNN) for a specific visual task involves several key steps to ensure optimal performance and accuracy. Firstly, you need to gather a labeled dataset that is relevant to your visual task, ensuring that it contains a diverse range of examples for the network to learn from. Next, you will preprocess the data by resizing, normalizing, and augmenting the images to improve generalization and robustness of the model. Then, you will define the architecture of your CNN, including the number of layers, filter sizes, activation functions, and pooling strategies based on the complexity of your task. During training, you will feed batches of images into the network, compute the loss function (such as cross-entropy), and update the weights using optimization algorithms like stochastic gradient descent or Adam. It is crucial to monitor the training process by evaluating metrics like accuracy and loss on a validation set to prevent overfitting. Fine-tuning hyperparameters and conducting regular model evaluations are essential for achieving high performance in training a deep CNN model for a specific visual task.
What are some common challenges faced when working with deep convolutional neural networks?
When working with deep Convolutional Neural Networks (CNNs), practitioners often encounter several common challenges. One challenge is the need for large amounts of labeled training data to effectively train deep CNN models, which can be time-consuming and resource-intensive to acquire. Another challenge is the risk of overfitting, where the model performs well on training data but fails to generalize to unseen data. Additionally, tuning hyperparameters such as learning rates and network architecture can be a complex and iterative process that requires careful experimentation. Addressing these challenges through proper data management, regularization techniques, and hyperparameter optimization is crucial for maximizing the performance and efficiency of deep CNNs in various applications.
What real-world applications benefit from the use of deep CNNs?
Deep Convolutional Neural Networks (CNNs) have found widespread applications across various industries due to their exceptional ability to process visual data effectively. Real-world applications that benefit from the use of deep CNNs include medical image analysis for diagnosing diseases from X-rays and MRIs, autonomous driving systems for identifying objects and obstacles on the road, surveillance systems for detecting and tracking individuals in security footage, and even in augmented reality applications for enhancing user experiences through object recognition and tracking. The versatility and accuracy of deep CNNs make them invaluable tools in solving complex visual tasks that require sophisticated pattern recognition and analysis capabilities.