Convolutional Neural Network (CNN) in Natural Language Processing (NLP)
In the realm of Natural Language Processing (NLP), Convolutional Neural Networks (CNNs) have emerged as a powerful tool for tackling various language-related tasks. Originally developed for computer vision, CNNs have proven their versatility by being successfully applied to NLP problems, revolutionizing the field and achieving state-of-the-art results in many areas.
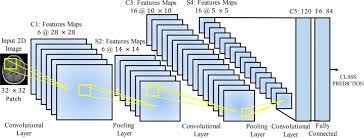
So, what exactly is a Convolutional Neural Network in the context of NLP? In simple terms, it is a type of neural network architecture that utilizes convolutional layers to process and analyze sequential data, such as text or speech.
One of the main advantages of CNNs lies in their ability to automatically learn relevant features from raw input data. This feature extraction process is crucial for understanding the underlying patterns and structures within textual data. By applying convolutional filters over input sequences, CNNs can capture local patterns and dependencies between words or characters.
In NLP tasks like sentiment analysis, text classification, or named entity recognition, CNNs excel at learning hierarchical representations. The initial layers capture low-level features like individual characters or word n-grams, while deeper layers learn more complex features that span across multiple words or phrases. This hierarchical approach allows CNNs to effectively model both local and global dependencies within the text.
Moreover, CNNs are known for their ability to handle variable-length inputs through padding and pooling operations. Padding ensures that all input sequences have a consistent length, while pooling reduces the dimensionality of feature maps by selecting the most salient information. These operations enable CNNs to efficiently process texts of different lengths without losing important contextual information.
When it comes to training CNN models for NLP tasks, large labeled datasets play a crucial role. By leveraging these datasets and employing techniques like transfer learning or pre-training on massive corpora like Wikipedia or Twitter, CNN models can generalize well across various domains and languages.
CNNs have shown remarkable success in a wide range of NLP applications. They have been used for sentiment analysis, text classification, document summarization, question answering, machine translation, and more. Their ability to capture local and global dependencies, combined with their scalability and efficiency, makes them a popular choice among researchers and practitioners.
However, like any other machine learning model, CNNs also face challenges. The lack of interpretability is one such challenge. Understanding how CNNs make predictions or which features they consider important can be difficult due to their complex architecture. Additionally, handling out-of-vocabulary words or rare linguistic phenomena can pose challenges when working with CNNs.
In conclusion, Convolutional Neural Networks have become a powerful tool in the field of Natural Language Processing. Their ability to automatically learn relevant features from raw input data and capture both local and global dependencies has led to state-of-the-art results in various NLP tasks. With ongoing research and advancements in the field, CNNs are expected to continue pushing the boundaries of what is possible in language understanding and generation.
Frequently Asked Questions about Convolutional Neural Networks (CNNs) for Natural Language Processing (NLP)
- What is a convolutional neural network (CNN) for natural language processing (NLP)?
- How does a CNN work for NLP?
- What are the advantages of using a CNN for NLP?
- How is a CNN different from other deep learning models used for NLP?
- What datasets are commonly used to train and evaluate CNNs for NLP applications?
- Are there any challenges associated with using a CNN for NLP tasks?
What is a convolutional neural network (CNN) for natural language processing (NLP)?
A Convolutional Neural Network (CNN) for Natural Language Processing (NLP) is a type of neural network architecture originally developed for computer vision tasks that has been adapted to process textual data. CNNs have shown great success in analyzing and understanding sequential data, such as text or speech, by leveraging their ability to capture local patterns and dependencies.
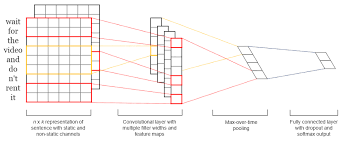
In the context of NLP, CNNs operate on input sequences like sentences or documents. They use convolutional layers to apply filters over the input data, extracting relevant features at different levels of abstraction. These filters slide across the input sequences, performing element-wise multiplications and aggregating the results to create feature maps.
The key advantage of using CNNs in NLP is their ability to learn hierarchical representations of textual data. The initial layers capture low-level features like individual characters or word n-grams, while deeper layers learn more complex features that span across multiple words or phrases. This hierarchical approach enables CNNs to understand both local and global dependencies within the text.
To handle variable-length inputs, CNNs often employ padding and pooling operations. Padding ensures that all input sequences have a consistent length by adding zeros or special tokens. Pooling reduces the dimensionality of feature maps by selecting the most salient information. These operations enable CNNs to effectively process texts of different lengths without losing important contextual information.
Training CNN models for NLP tasks typically requires large labeled datasets. By leveraging these datasets and employing techniques like transfer learning or pre-training on massive corpora, such as Wikipedia or Twitter, CNN models can generalize well across various domains and languages.
CNNs have proven successful in various NLP applications including sentiment analysis, text classification, document summarization, question answering, machine translation, and more. Their ability to automatically learn relevant features from raw input data and capture both local and global dependencies makes them a popular choice among researchers and practitioners in the field of NLP.
However, it’s worth noting that CNNs also face challenges in NLP. Interpreting their predictions or understanding which features are considered important can be difficult due to their complex architecture. Additionally, handling out-of-vocabulary words or rare linguistic phenomena can pose challenges when working with CNNs. Nonetheless, ongoing research and advancements continue to enhance the capabilities of CNNs for NLP tasks, pushing the boundaries of language understanding and generation.
How does a CNN work for NLP?
Convolutional Neural Networks (CNNs) work for Natural Language Processing (NLP) by leveraging their ability to process and analyze sequential data, such as text or speech. Although CNNs were initially developed for computer vision tasks, they have been successfully adapted to NLP problems and have demonstrated impressive performance in various language-related tasks.
To understand how CNNs work for NLP, let’s dive into the key components and operations involved:
- Input representation: In NLP, text is typically represented as a sequence of words or characters. Before feeding the text data into a CNN, it needs to be converted into a numerical representation. This can be achieved through techniques like word embeddings (e.g., Word2Vec or GloVe), character embeddings, or one-hot encoding.
- Convolutional layers: The core operation in a CNN is the convolution operation. Convolutional layers consist of multiple filters (also known as kernels) that slide over the input sequence, capturing local patterns and dependencies between neighboring words or characters. Each filter performs element-wise multiplications followed by summations to produce a feature map.
- Feature extraction: As the convolutional filters slide over the input sequence, they generate feature maps by applying different filters across various positions. These feature maps capture different aspects of the input data at different levels of abstraction. The initial layers capture low-level features like individual characters or word n-grams, while deeper layers learn more complex features that span across multiple words or phrases.
- Padding and pooling: Since texts can have varying lengths, padding is often applied to ensure that all input sequences have a consistent length. Padding involves adding special tokens (e.g., zeros) to either the beginning or end of sequences so that they match a desired length. Pooling operations like max pooling or average pooling are then applied to reduce the dimensionality of feature maps and extract the most salient information.
- Fully connected layers: After the convolutional and pooling layers, fully connected layers are employed to combine the extracted features and make predictions. These layers connect every neuron from the previous layer to every neuron in the subsequent layer. They learn complex relationships between features and produce output probabilities or class labels.
- Training and optimization: CNN models for NLP tasks are trained using labeled datasets. The training process involves optimizing model parameters by minimizing a loss function, typically through techniques like backpropagation and gradient descent. Large labeled datasets are crucial for CNNs to learn meaningful representations and generalize well across different domains.
By leveraging these operations, CNNs can effectively capture both local and global dependencies within texts. The hierarchical feature extraction process enables them to understand patterns at different levels of granularity, making them powerful tools for various NLP tasks such as sentiment analysis, text classification, machine translation, and more.
It’s worth noting that while CNNs have demonstrated remarkable success in NLP, they are not the only approach available. Recurrent Neural Networks (RNNs), Transformer models (e.g., BERT), and other architectures have also been widely used in NLP tasks, each with their own strengths and limitations. Researchers continue to explore new architectures and techniques to further advance the field of NLP.
What are the advantages of using a CNN for NLP?
Using a Convolutional Neural Network (CNN) in Natural Language Processing (NLP) offers several advantages that have contributed to its popularity and success in various language-related tasks. Here are some key advantages:
- **Efficient feature extraction**: CNNs excel at automatically learning relevant features from raw input data. By applying convolutional filters over input sequences, they can capture local patterns and dependencies between words or characters. This feature extraction process is crucial for understanding the underlying structures and patterns within textual data.
- **Hierarchical representation**: CNNs are known for their ability to learn hierarchical representations of text. The initial layers capture low-level features like individual characters or word n-grams, while deeper layers learn more complex features that span across multiple words or phrases. This hierarchical approach allows CNNs to effectively model both local and global dependencies within the text.
- **Handling variable-length inputs**: CNNs can handle variable-length inputs through padding and pooling operations. Padding ensures that all input sequences have a consistent length, while pooling reduces the dimensionality of feature maps by selecting the most salient information. These operations enable CNNs to efficiently process texts of different lengths without losing important contextual information.
- **Scalability**: CNN models can scale well with large labeled datasets. By leveraging these datasets and employing techniques like transfer learning or pre-training on massive corpora, such as Wikipedia or Twitter, CNN models can generalize well across various domains and languages.
- **Parallel processing**: CNN computations can be parallelized efficiently, making them suitable for implementation on modern hardware architectures like GPUs (Graphics Processing Units) or TPUs (Tensor Processing Units). This parallel processing capability enables faster training and inference times, making CNNs efficient for large-scale NLP tasks.
- **State-of-the-art performance**: CNNs have achieved state-of-the-art results in various NLP applications, including sentiment analysis, text classification, document summarization, question answering, machine translation, and more. Their ability to capture local and global dependencies, combined with their scalability and efficiency, has made them a popular choice among researchers and practitioners.
While CNNs offer numerous advantages, it is important to note that they also face challenges like interpretability and handling out-of-vocabulary words or rare linguistic phenomena. Nonetheless, the advantages of CNNs in NLP have significantly advanced the field and continue to push the boundaries of what is possible in language understanding and generation.
How is a CNN different from other deep learning models used for NLP?
Convolutional Neural Networks (CNNs) differ from other deep learning models used in Natural Language Processing (NLP) in terms of their architecture and the way they process sequential data. Here are a few key differences:
- Architecture: CNNs are primarily designed for processing grid-like data, such as images or sequences. They typically consist of convolutional layers, pooling layers, and fully connected layers. In contrast, other popular deep learning models for NLP, such as Recurrent Neural Networks (RNNs) or Transformers, have different architectures that are specifically tailored to handle sequential data.
- Local vs. Sequential Dependencies: CNNs excel at capturing local patterns and dependencies within the input data. By applying convolutional filters over the input sequence, they can extract relevant features at different levels of abstraction. This makes them particularly effective at modeling short-range dependencies in NLP tasks. On the other hand, RNNs and Transformers are designed to capture long-range dependencies by maintaining an internal memory or attention mechanism that allows them to process the entire sequence.
- Parameter Sharing: CNNs utilize parameter sharing across different regions of the input data, which significantly reduces the number of parameters compared to fully connected networks. This property makes CNNs computationally efficient and enables them to scale well with larger datasets.
- Handling Variable-Length Inputs: CNNs can handle variable-length inputs through padding and pooling operations. Padding ensures that all input sequences have a consistent length, while pooling reduces dimensionality by selecting salient information from feature maps. This allows CNNs to efficiently process texts of different lengths without losing important contextual information.
- Interpretability: Compared to some other deep learning models used in NLP, such as RNNs or LSTMs (Long Short-Term Memory), CNNs may be less interpretable due to their complex architecture and hierarchical feature extraction process.
It’s important to note that each model has its own strengths and weaknesses, and the choice of model depends on the specific NLP task at hand. While CNNs have shown remarkable success in tasks like sentiment analysis or text classification, other models like RNNs or Transformers may be more suitable for tasks that require capturing long-range dependencies or generating coherent sequences of text.
What datasets are commonly used to train and evaluate CNNs for NLP applications?
Several datasets are commonly used to train and evaluate Convolutional Neural Networks (CNNs) for NLP applications. Here are some widely recognized datasets in the field:
- IMDB Movie Reviews: The IMDB dataset consists of movie reviews labeled with sentiment polarity (positive or negative). It is often used for sentiment analysis tasks and has become a benchmark dataset in the NLP community.
- AG News: The AG News dataset contains news articles from various categories, such as World, Sports, Business, and Science. It is commonly used for text classification tasks.
- Reuters-21578: This dataset comprises news articles from the Reuters newswire service, classified into different topics. It is frequently used for text categorization and topic modeling tasks.
- 20 Newsgroups: The 20 Newsgroups dataset consists of posts from different newsgroups on Usenet. It covers a wide range of topics and is commonly employed for text classification and topic modeling purposes.
- SQuAD (Stanford Question Answering Dataset): SQuAD is a popular dataset for question answering tasks. It contains questions based on Wikipedia articles, along with corresponding passages where the answers can be found.
- CoNLL-2003: The CoNLL-2003 dataset focuses on named entity recognition (NER) tasks. It provides labeled data for identifying named entities like people, organizations, locations, etc., in news articles.
- SNLI (Stanford Natural Language Inference): SNLI is a large-scale dataset that involves determining the relationship between two given sentences: whether they entail each other, contradict each other, or are neutral.
- WikiText/Wikipedia Dumps: These datasets consist of large collections of Wikipedia articles and are often used to pre-train language models that can later be fine-tuned for specific NLP tasks.
These datasets serve as valuable resources for training and evaluating CNN models in NLP. They cover a range of tasks, including sentiment analysis, text classification, question answering, named entity recognition, and more. Researchers and practitioners often use these datasets to benchmark their models and compare their performance against existing state-of-the-art approaches.
Are there any challenges associated with using a CNN for NLP tasks?
While Convolutional Neural Networks (CNNs) have proven to be effective in many Natural Language Processing (NLP) tasks, they also come with their own set of challenges. Here are some key challenges associated with using CNNs for NLP:
- Interpretability: CNNs are deep and complex models, making it challenging to interpret how they make predictions or which features they consider important. Understanding the decision-making process of a CNN can be crucial, especially in sensitive domains like healthcare or legal applications.
- Handling Out-of-vocabulary (OOV) words: CNN models typically rely on pre-trained word embeddings that map words to continuous vector representations. However, OOV words, which are not present in the pre-trained embeddings, pose a challenge. Handling rare or unseen words effectively is an ongoing area of research in NLP.
- Contextual understanding: While CNNs can capture local patterns and dependencies effectively, modeling long-range dependencies and contextual understanding can be more challenging. Tasks that require a deep understanding of context, such as coreference resolution or document-level sentiment analysis, may require additional techniques or architectural modifications.
- Data requirements: Training CNN models for NLP tasks often requires large labeled datasets. Collecting and annotating such datasets can be time-consuming and expensive. Additionally, domain-specific data may not always be readily available, leading to difficulties in training task-specific models.
- Overfitting: As with any deep learning model, overfitting is a concern when using CNNs for NLP tasks. Overfitting occurs when the model becomes too specialized on the training data and fails to generalize well on unseen data. Regularization techniques like dropout or early stopping are commonly employed to mitigate this issue.
- Computational complexity: CNN models can be computationally expensive to train and deploy due to their deep architecture and large number of parameters. Training on large-scale datasets may require significant computational resources and time.
- Multilingual challenges: While CNNs have been successful in various languages, they may face challenges when dealing with languages with different structures, morphologies, or syntactic rules. Adapting CNN models to different languages or low-resource settings can be a complex task.
Despite these challenges, CNNs remain a popular choice for many NLP tasks due to their ability to capture local patterns and hierarchical representations. Ongoing research and advancements in the field aim to address these challenges and further improve the performance and applicability of CNNs in NLP.