Neural Networks: Unleashing the Power of Artificial Intelligence
In the ever-evolving field of artificial intelligence, one technology stands out for its remarkable ability to mimic the human brain and revolutionize various industries – neural networks. These complex systems have become a driving force behind many groundbreaking advancements, from speech recognition and image processing to self-driving cars and natural language understanding.
At its core, a neural network is a computational model inspired by the biological structure of the brain. Just like our brain consists of interconnected neurons, a neural network comprises layers of artificial neurons called nodes or units. These nodes work together to process and analyze vast amounts of data, enabling machines to learn patterns, make decisions, and perform tasks with remarkable accuracy.
The strength of neural networks lies in their ability to learn from examples. Through a process called training, these networks can recognize patterns and relationships within data sets, allowing them to generalize and make predictions on new inputs. This learning process is achieved through adjusting the weights and biases associated with each node, optimizing them to minimize errors and improve performance.
One key advantage of neural networks is their versatility. They can be applied to various problem domains such as image classification, natural language processing, time series analysis, and even financial forecasting. With deep learning architectures like convolutional neural networks (CNNs) or recurrent neural networks (RNNs), complex tasks that were once considered insurmountable are now being tackled with unprecedented success.
Take computer vision as an example. Neural networks have revolutionized this field by enabling machines to accurately identify objects within images or videos. By training on massive datasets containing millions of labeled images, these networks can learn intricate features that differentiate objects like cats from dogs or recognize specific facial expressions with astonishing precision.
In natural language processing, neural networks have also made significant strides. Language models built upon recurrent neural networks can generate coherent text or even engage in conversation that appears remarkably human-like. This breakthrough has not only transformed the way we interact with chatbots and virtual assistants but has also opened doors for advancements in machine translation, sentiment analysis, and information retrieval.
However, building and training neural networks is not without its challenges. These models require substantial computational resources and extensive data sets to achieve optimal performance. Additionally, overfitting (when a network becomes too specialized in the training data) and vanishing gradients (when the learning process becomes slow or stagnant) can hinder progress. Researchers are continually exploring techniques to mitigate these issues and enhance the capabilities of neural networks.
The future of neural networks looks promising. As technology advances, we can expect even more sophisticated architectures that push the boundaries of what machines can achieve. Reinforcement learning, where networks learn through trial and error guided by rewards, holds tremendous potential for creating intelligent systems capable of complex decision-making.
Neural networks have become the backbone of modern artificial intelligence, enabling machines to learn, adapt, and perform tasks that were once exclusively human domains. With ongoing research and development, these powerful tools will undoubtedly continue to shape our world, driving innovation across industries and unlocking new possibilities we have yet to imagine.
A Comprehensive Guide to Neural Networks: Frequently Asked Questions
- What is a neural network?
- How does a neural network work?
- What are the advantages of using a neural network?
- What are the different types of neural networks?
- How can I use a neural network to solve my problem?
- Are there any limitations to using a neural network?
- What is deep learning and how does it relate to neural networks?
- How do I train and optimize my own neural network model?
What is a neural network?
A neural network is a computational model inspired by the structure and functioning of the human brain. It is a complex system composed of interconnected artificial neurons, also known as nodes or units. These nodes work together to process and analyze vast amounts of data, enabling machines to learn from examples, recognize patterns, make decisions, and perform tasks with remarkable accuracy.
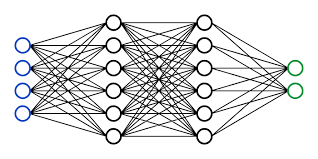
The neural network consists of layers of nodes. The first layer is called the input layer, where data is fed into the network. The last layer is the output layer, which produces the desired output or prediction based on the input data. In between these layers are hidden layers, where complex computations take place.
Each node in a neural network receives inputs from multiple nodes in the previous layer and applies a mathematical operation to generate an output value. This output value is then passed through an activation function that introduces non-linearity into the network, allowing it to learn complex relationships and make more accurate predictions.
The strength of a neural network lies in its ability to learn from examples through a process called training. During training, the network adjusts its internal parameters, known as weights and biases, based on feedback received from comparing its predictions with known correct outputs. By iteratively optimizing these parameters using algorithms like backpropagation or stochastic gradient descent, the neural network gradually improves its performance and becomes more accurate in making predictions on new inputs.
Neural networks have gained significant attention due to their versatility and ability to solve complex problems across various domains such as computer vision, natural language processing, speech recognition, and more. They have revolutionized fields like image classification, object detection, language translation, sentiment analysis, and even autonomous driving.
While building and training neural networks can be challenging due to computational requirements and potential issues like overfitting or vanishing gradients, ongoing research continues to enhance their capabilities. As technology advances further, we can expect even more sophisticated architectures that push the boundaries of what machines can achieve using neural networks.
How does a neural network work?
A neural network is a computational model inspired by the structure and functioning of the human brain. It consists of interconnected nodes, also known as artificial neurons or units, organized in layers. Each node receives input data, performs calculations, and passes the result to the next layer until an output is generated.
Here’s a simplified explanation of how a neural network works:
- Input Layer: The first layer of a neural network is called the input layer. It receives raw data or features from the external environment, such as images, text, or numerical values.
- Hidden Layers: Between the input and output layers are one or more hidden layers. These layers are responsible for processing and transforming the input data using weighted connections between nodes.
- Weights and Biases: Each connection between nodes in a neural network has a weight associated with it. These weights determine the strength or importance of each connection. Additionally, each node has a bias value that affects its activation level.
- Activation Function: At each node, the weighted sum of inputs (including biases) is passed through an activation function. This function introduces non-linearity into the network and determines whether the node should be activated or not.
- Forward Propagation: During forward propagation, data flows through the network from the input layer to the output layer. The activations and calculations at each node are computed based on weights, biases, and activation functions.
- Output Layer: The final layer in a neural network is called the output layer. It generates predictions or outputs based on the information processed throughout the hidden layers.
- Loss Function: To measure how well our predictions match expected outcomes, a loss function is used to calculate an error value. The goal is to minimize this error during training.
- Backpropagation: Backpropagation is an essential step in training a neural network. It involves calculating gradients that indicate how much each weight and bias contributes to the overall error. These gradients are then used to update the weights and biases, adjusting them to minimize the error.
- Training: Training a neural network involves iteratively presenting labeled training examples to the network, calculating errors, and updating weights and biases through backpropagation. This process helps the network learn patterns and optimize its performance.
- Prediction: Once a neural network is trained, it can be used for making predictions on new, unseen data. The input data is fed into the network, and forward propagation calculates the output based on the learned weights and biases.
Neural networks learn by adjusting their weights and biases through training examples, allowing them to generalize from known data to make predictions on new inputs. This ability to learn from data is what makes neural networks powerful tools for tasks such as image recognition, natural language processing, and many other applications in artificial intelligence.
What are the advantages of using a neural network?
Using a neural network offers several advantages that have contributed to its widespread adoption and success in various fields. Here are some key advantages:
- Pattern recognition and complex data analysis: Neural networks excel at recognizing patterns and extracting meaningful insights from large and complex datasets. They can identify intricate relationships, hidden patterns, and non-linear dependencies that may not be apparent to human analysts. This ability makes them valuable in tasks such as image recognition, speech processing, and natural language understanding.
- Adaptability and learning capability: Neural networks are highly adaptable and can learn from experience. Through training on labeled datasets, they can adjust their internal parameters (weights and biases) to optimize performance over time. This adaptability allows them to improve accuracy, generalize knowledge, and make predictions on new inputs or data they haven’t encountered before.
- Handling high-dimensional data: Traditional machine learning algorithms struggle with high-dimensional data due to the “curse of dimensionality.” Neural networks, on the other hand, can effectively handle such data by automatically learning relevant features through multiple layers of interconnected nodes. This makes them well-suited for tasks involving images, videos, audio signals, or text analysis.
- Parallel processing: Neural networks can perform computations in parallel across multiple nodes simultaneously. This parallel processing capability enables faster training and inference times compared to sequential algorithms. It also allows for efficient utilization of modern hardware architectures like GPUs (Graphics Processing Units) or TPUs (Tensor Processing Units), further accelerating neural network operations.
- Robustness against noise: Neural networks exhibit robustness against noisy or incomplete data due to their ability to generalize patterns from examples during training. They can handle missing values or noisy inputs by inferring reasonable outputs based on the learned relationships within the dataset.
- Non-linearity handling: Many real-world problems involve non-linear relationships between input variables and outputs. Traditional linear models struggle with capturing these complex relationships effectively. Neural networks excel at modeling non-linear functions and can approximate even highly complex mappings, making them suitable for tasks requiring non-linear decision boundaries.
- Domain versatility: Neural networks have proven to be versatile across various domains and applications. They have achieved state-of-the-art performance in computer vision, natural language processing, speech recognition, recommendation systems, fraud detection, and many other fields. Their flexibility allows them to adapt to different problem types and datasets with relative ease.
While neural networks offer numerous advantages, it’s important to note that they also come with challenges such as the need for substantial computational resources, extensive training data availability, and potential overfitting. However, ongoing research and advancements continue to address these challenges, further enhancing the benefits of using neural networks in artificial intelligence applications.
What are the different types of neural networks?
There are several types of neural networks, each designed to tackle specific problem domains and data structures. Here are some commonly used types:
- Feedforward Neural Networks (FNN): This is the most basic type of neural network, where information flows in one direction, from input nodes through hidden layers to output nodes. FNNs are primarily used for tasks like classification and regression.
- Convolutional Neural Networks (CNN): CNNs excel in image and video analysis tasks. They use convolutional layers to automatically extract relevant features from input data, making them highly effective in tasks such as object recognition, image classification, and computer vision.
- Recurrent Neural Networks (RNN): RNNs are designed to process sequential data by utilizing feedback connections. They have a memory-like capability that allows them to retain information about previous inputs, making them suitable for tasks like natural language processing, speech recognition, and time series analysis.
- Long Short-Term Memory Networks (LSTM): LSTMs are a specialized type of RNN that address the vanishing gradient problem associated with traditional RNNs. They have an improved memory cell structure that enables better handling of long-term dependencies in sequential data.
- Generative Adversarial Networks (GAN): GANs consist of two interconnected neural networks: a generator network and a discriminator network. The generator network generates synthetic data samples while the discriminator network tries to distinguish between real and fake samples. GANs are widely used for tasks like image synthesis, video generation, and anomaly detection.
- Autoencoders: Autoencoders are unsupervised learning models that aim to reconstruct input data from compressed representations called encodings or latent variables. They can be used for dimensionality reduction, feature extraction, and anomaly detection.
- Radial Basis Function Networks (RBFN): RBFNs use radial basis functions as activation functions in their hidden layers. They are commonly used for tasks like function approximation, pattern recognition, and time series prediction.
- Self-Organizing Maps (SOM): SOMs are unsupervised learning models that organize input data into a low-dimensional grid or map. They can be used for tasks like clustering, visualization, and feature extraction.
These are just a few examples of neural network types. There are also variations and hybrid models that combine different architectures to address specific challenges in various domains. The choice of neural network type depends on the nature of the problem, the available data, and the desired outcome.
How can I use a neural network to solve my problem?
Using a neural network to solve a problem involves several steps. Here’s a general guide to help you get started:
- Define your problem: Clearly identify the problem you want to solve and determine if it is suitable for a neural network approach. Neural networks excel in tasks involving pattern recognition, classification, regression, and sequence processing.
- Gather and preprocess data: Collect or generate a dataset that is relevant to your problem. Ensure the data is clean, labeled (if applicable), and representative of the real-world scenarios you aim to tackle. Preprocess the data by normalizing, scaling, or encoding it appropriately for input into the neural network.
- Design your neural network architecture: Choose the type of neural network architecture that aligns with your problem domain. Popular types include feedforward neural networks (multilayer perceptrons), convolutional neural networks (for image-related tasks), recurrent neural networks (for sequence data), and more advanced architectures like transformers or generative adversarial networks (GANs). Determine the number of layers, nodes per layer, activation functions, and other hyperparameters based on your specific requirements.
- Split your dataset: Divide your dataset into training, validation, and testing sets. The training set will be used to train the neural network, while the validation set helps fine-tune hyperparameters during training. The testing set evaluates the final performance of your trained model.
- Train your neural network: Initialize the weights and biases of your network and start training using an appropriate optimization algorithm such as gradient descent or its variants (e.g., Adam). During training, feed batches of input data into the network and compare its predictions with known outputs using a loss function that quantifies prediction errors. Backpropagation is then used to adjust weights and biases iteratively in order to minimize this loss.
- Evaluate and fine-tune: Monitor performance metrics such as accuracy, precision, recall, or mean squared error on both the training and validation sets. If the model is not performing well, consider adjusting hyperparameters, changing the network architecture, or augmenting the data to improve performance.
- Test and deploy: Once you are satisfied with your trained model’s performance, evaluate it on the testing set to get a final measure of its accuracy. If the results are satisfactory, you can deploy your neural network to make predictions or perform tasks on new, unseen data.
Remember that successfully using a neural network requires a combination of domain knowledge, experimentation, and iterative refinement. It’s also essential to stay up-to-date with current research and best practices in neural network design and training techniques.
Are there any limitations to using a neural network?
While neural networks have shown remarkable capabilities, they do come with certain limitations. Here are a few key considerations:
- Data requirements: Neural networks typically require large amounts of labeled data to achieve optimal performance. Without sufficient training data, the network may struggle to generalize and make accurate predictions. Acquiring and labeling extensive datasets can be time-consuming and costly.
- Computational resources: Training complex neural networks can be computationally intensive, requiring powerful hardware such as GPUs (Graphics Processing Units) or specialized processors. This can limit accessibility for individuals or organizations with limited resources.
- Overfitting: Neural networks are prone to overfitting, where they become too specialized in the training data and fail to generalize well on unseen examples. Overfitting can occur when the network is too complex relative to the available training data or when the training process is not properly regularized.
- Interpretability: Neural networks often function as black boxes, making it challenging to interpret how they arrive at their decisions. Understanding the internal workings of a neural network and providing explanations for its outputs can be difficult, especially in complex architectures like deep neural networks.
- Vulnerability to adversarial attacks: Neural networks can be susceptible to adversarial attacks, where small perturbations or modifications in input data lead to incorrect predictions or misclassifications. Adversarial attacks pose security concerns in applications such as autonomous vehicles or cybersecurity systems.
- Limited domain knowledge: Neural networks rely solely on patterns learned from training data and lack inherent domain knowledge or common sense reasoning abilities that humans possess naturally. This means that in situations requiring contextual understanding or reasoning outside of their training data scope, neural networks may struggle to perform accurately.
Addressing these limitations is an active area of research within the field of artificial intelligence. Researchers are continually exploring techniques such as transfer learning, regularization methods, explainable AI, and robustness enhancements to mitigate these challenges and improve the reliability and performance of neural networks.
What is deep learning and how does it relate to neural networks?
Deep learning is a subfield of machine learning that focuses on training artificial neural networks with multiple layers, also known as deep neural networks. It is inspired by the structure and function of the human brain, specifically the interconnectedness of neurons.
While traditional neural networks typically consist of only a few layers, deep neural networks can have dozens or even hundreds of layers. These additional layers allow for the extraction of increasingly complex features and patterns from data, enabling more sophisticated learning and decision-making processes.
Deep learning algorithms excel at automatically learning hierarchical representations of data. Each layer in a deep neural network performs a series of computations on the input data, transforming it into higher-level abstractions. This hierarchical representation allows the network to capture intricate relationships and nuances within the data.
The key advantage of deep learning lies in its ability to automatically learn feature representations from raw data without requiring explicit feature engineering. Instead of manually selecting and designing features, deep neural networks can learn to extract relevant features directly from the input data during training. This makes deep learning highly adaptable to various domains and reduces the need for domain-specific knowledge.
Deep learning has revolutionized many fields, including computer vision, natural language processing, speech recognition, and recommendation systems. For example, in computer vision tasks such as image classification or object detection, deep convolutional neural networks (CNNs) have achieved unprecedented accuracy by automatically learning hierarchical representations of visual features.
In natural language processing (NLP), recurrent neural networks (RNNs) or transformer models have been instrumental in tasks such as machine translation, sentiment analysis, and text generation. These models can process sequential data like sentences or documents while capturing contextual dependencies between words or phrases.
The success of deep learning is largely attributed to advancements in computational power and access to large-scale labeled datasets. Training deep neural networks requires significant computational resources due to their depth and complexity. Additionally, having vast amounts of labeled data allows these models to generalize better and achieve higher accuracy.
In summary, deep learning is a subset of machine learning that leverages deep neural networks with multiple layers to learn hierarchical representations of data. It has proven to be highly effective in various domains, enabling machines to automatically extract features and make complex predictions or decisions. Deep learning has significantly advanced the field of artificial intelligence and continues to drive innovation across industries.
How do I train and optimize my own neural network model?
Training and optimizing a neural network model can be a complex process, but here are some general steps to get you started:
- Define your problem and gather data: Clearly define the problem you want your neural network to solve, and collect a suitable dataset that represents the input-output relationship you want the model to learn.
- Preprocess the data: Clean and preprocess your data to ensure it is in a suitable format for training. This may involve tasks such as removing outliers, normalizing or scaling features, handling missing values, and splitting the data into training and validation sets.
- Design your neural network architecture: Choose an appropriate architecture for your neural network based on the nature of your problem. Consider factors such as the number of layers, types of activation functions, and connectivity patterns between layers. This step requires domain knowledge or experimentation.
- Initialize the model parameters: Initialize the weights and biases of your neural network randomly or using predefined techniques such as Xavier or He initialization. Proper initialization can help speed up convergence during training.
- Forward propagation: Implement the forward propagation algorithm to compute predictions based on the current parameter values of your model. This involves passing input data through each layer, applying activation functions, and producing an output prediction.
- Define a loss function: Choose an appropriate loss function that quantifies how well your predictions match the ground truth labels in your dataset. Common loss functions include mean squared error (MSE) for regression problems and categorical cross-entropy for classification problems.
- Backpropagation: Implement the backpropagation algorithm to calculate gradients of the loss function with respect to each parameter in your model. These gradients indicate how much each parameter contributes to minimizing the loss.
- Update parameters: Use optimization algorithms like stochastic gradient descent (SGD) or its variants (e.g., Adam, RMSprop) to update the weights and biases of your model based on the computed gradients from backpropagation. This step involves finding an optimal learning rate and applying regularization techniques (e.g., L1 or L2 regularization) to prevent overfitting.
- Iterate: Repeat steps 5-8 for multiple epochs, where each epoch represents one complete pass through the entire dataset. This iterative process allows the model to gradually improve its performance by adjusting parameters based on the training data.
- Evaluate and fine-tune: Evaluate your trained model using the validation set and metrics appropriate for your problem (e.g., accuracy, precision, recall, F1-score). Fine-tune your model by adjusting hyperparameters like learning rate, batch size, or network architecture based on the validation performance.
- Test your model: Once you are satisfied with the performance on the validation set, test your trained neural network on a separate test set that was not used during training or validation. This provides an unbiased evaluation of your model’s generalization ability.
Remember that training and optimizing a neural network is an iterative process that often requires experimentation and fine-tuning of various components. It’s also helpful to stay updated with recent research papers and techniques in the field to enhance your understanding and improve results.