Recurrent Neural Network (RNN) in Natural Language Processing (NLP)
Recurrent Neural Networks (RNNs) have revolutionized the field of Natural Language Processing (NLP) by enabling machines to understand and generate human language with remarkable accuracy and fluency. RNNs are a type of artificial neural network designed to handle sequential data, making them ideal for tasks such as language modeling, speech recognition, machine translation, and sentiment analysis.
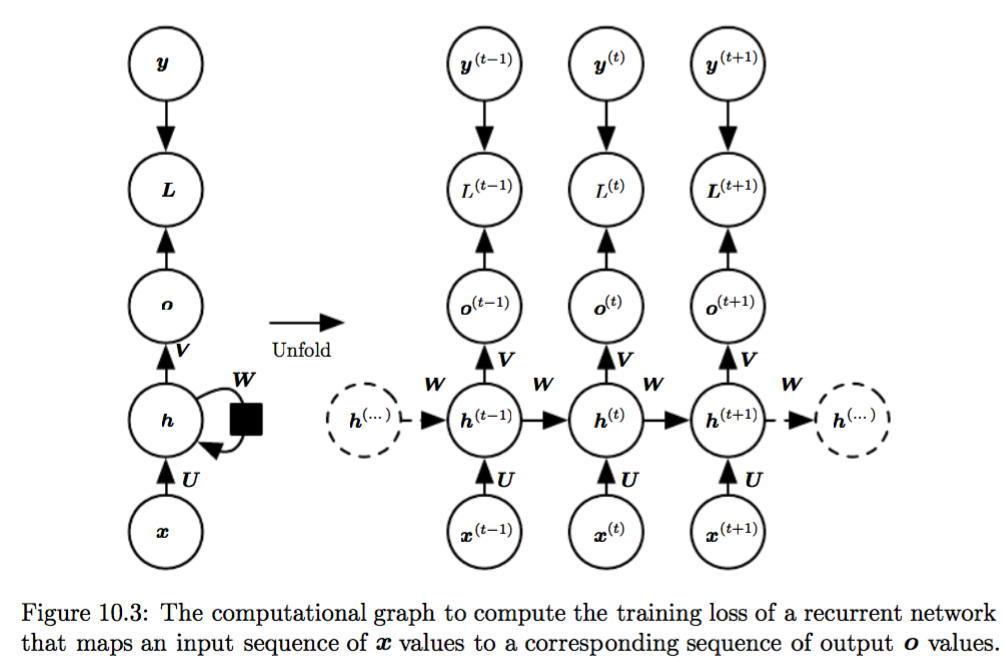
One of the key features that sets RNNs apart from other neural networks is their ability to maintain a memory of previous inputs through hidden states. This memory mechanism allows RNNs to capture dependencies and patterns in sequential data, making them particularly effective for processing text data.
In NLP applications, RNNs excel at tasks that require an understanding of context and temporal relationships within a sequence of words. For example, in language modeling, an RNN can predict the next word in a sentence based on the words that have come before it. In machine translation, RNNs can translate entire sentences by considering the context of each word within the sentence.
Despite their effectiveness, traditional RNNs have limitations when it comes to capturing long-term dependencies in sequences. This is where more advanced variants of RNNs, such as Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), come into play. These models address the vanishing gradient problem associated with standard RNNs and enable better handling of long-range dependencies in sequences.
RNNs have been instrumental in advancing NLP research and applications, paving the way for state-of-the-art language models like GPT-3 and BERT. These models leverage the power of deep learning and large-scale training data to achieve unprecedented levels of performance in tasks such as text generation, question answering, and sentiment analysis.
As NLP continues to evolve rapidly, recurrent neural networks remain a fundamental building block for developing sophisticated language processing systems. Their ability to capture sequential patterns and contextual information makes them indispensable tools for unlocking the full potential of natural language understanding and generation.
7 Essential Tips for Enhancing NLP with Recurrent Neural Networks
- Preprocess text data by tokenizing words and converting them to numerical representations.
- Use word embeddings like Word2Vec or GloVe to capture semantic relationships between words.
- Consider using pre-trained language models like GPT-3 or BERT for better performance.
- Experiment with different RNN architectures such as LSTM or GRU to find the best model for your task.
- Regularize your RNN model with techniques like dropout to prevent overfitting.
- Optimize hyperparameters such as learning rate and batch size to improve training efficiency.
- Monitor training progress using metrics like loss and accuracy to make informed decisions during model development.
Preprocess text data by tokenizing words and converting them to numerical representations.
To effectively utilize recurrent neural networks in Natural Language Processing (NLP), it is crucial to preprocess text data by tokenizing words and converting them into numerical representations. Tokenization involves breaking down the text into individual words or tokens, which serves as the basic unit for analysis. By converting these tokens into numerical representations, such as word embeddings or one-hot encodings, the RNN can effectively process and learn from the textual data. This preprocessing step is essential for enabling the network to understand and analyze the sequential nature of language data, allowing for more accurate and meaningful predictions in NLP tasks.
Use word embeddings like Word2Vec or GloVe to capture semantic relationships between words.
By utilizing word embeddings such as Word2Vec or GloVe in recurrent neural network NLP models, you can effectively capture semantic relationships between words. These embeddings represent words as dense vectors in a continuous space, where words with similar meanings are located closer to each other. By leveraging this semantic information, RNNs can better understand the context and meaning of words within a sequence, leading to improved performance in tasks such as language modeling, sentiment analysis, and machine translation.
Consider using pre-trained language models like GPT-3 or BERT for better performance.
When working with recurrent neural networks in Natural Language Processing (NLP), it is highly beneficial to consider utilizing pre-trained language models such as GPT-3 or BERT to enhance performance. These advanced models have been trained on vast amounts of text data and have learned intricate language patterns, making them incredibly effective for a wide range of NLP tasks. By leveraging pre-trained language models, researchers and developers can achieve higher accuracy, improved efficiency, and faster deployment of NLP solutions, ultimately enhancing the quality and effectiveness of their language processing applications.
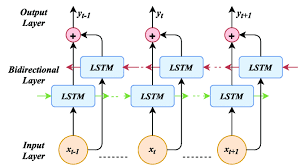
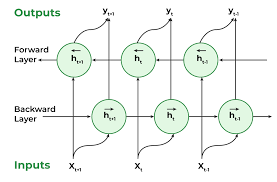
Experiment with different RNN architectures such as LSTM or GRU to find the best model for your task.
To optimize the performance of your recurrent neural network in Natural Language Processing, it is crucial to experiment with various architectures like LSTM or GRU. By exploring different RNN models, you can identify the one that best suits the specific requirements of your task. LSTM and GRU architectures, known for their ability to handle long-term dependencies effectively, offer enhanced capabilities compared to traditional RNNs. Through thorough experimentation and evaluation, you can determine the optimal model that maximizes accuracy and efficiency in processing sequential data for your NLP application.
Regularize your RNN model with techniques like dropout to prevent overfitting.
To enhance the performance and generalization of your Recurrent Neural Network (RNN) model in Natural Language Processing (NLP), it is crucial to apply regularization techniques such as dropout. Dropout helps prevent overfitting by randomly deactivating a fraction of neurons during training, forcing the network to learn more robust and generalized representations. By incorporating dropout into your RNN model, you can improve its ability to capture meaningful patterns in language data while reducing the risk of memorizing noise or irrelevant details, ultimately leading to better performance on unseen data.
Optimize hyperparameters such as learning rate and batch size to improve training efficiency.
To enhance the training efficiency of a recurrent neural network in Natural Language Processing (NLP), it is crucial to optimize hyperparameters like learning rate and batch size. Adjusting the learning rate can help the model converge faster and more effectively by controlling the size of parameter updates during training. Similarly, optimizing the batch size can impact the speed and stability of training, as it determines the number of samples processed in each iteration. By fine-tuning these hyperparameters, researchers and practitioners can significantly improve the performance and efficiency of RNN models in NLP tasks, leading to more accurate results and faster training times.
Monitor training progress using metrics like loss and accuracy to make informed decisions during model development.
Monitoring training progress using metrics like loss and accuracy is crucial in developing effective Recurrent Neural Network (RNN) models for Natural Language Processing (NLP). By tracking these key metrics throughout the training process, developers can gain valuable insights into how well the model is learning and generalizing from the data. The loss metric indicates how well the model is minimizing errors during training, while accuracy provides a measure of how correctly the model is predicting outcomes. By analyzing these metrics, developers can make informed decisions on adjusting hyperparameters, optimizing training strategies, and diagnosing potential issues to enhance the performance and efficiency of their RNN-based NLP models.